 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetMamba+: A Framework of Pre-trained Models for Efficient and Accurate Network Traffic Classification
Jan 29, 2026With the rapid growth of encrypted network traffic, effective traffic classification has become essential for network security and quality of service management. Current machine learning and deep learning approaches for traffic classification face three critical challenges: computational inefficiency of Transformer architectures, inadequate traffic representations with loss of crucial byte-level features while retaining detrimental biases, and poor handling of long-tail distributions in real-world data. We propose NetMamba+, a framework that addresses these challenges through three key innovations: (1) an efficient architecture considering Mamba and Flash Attention mechanisms, (2) a multimodal traffic representation scheme that preserves essential traffic information while eliminating biases, and (3) a label distribution-aware fine-tuning strategy. Evaluation experiments on massive datasets encompassing four main classification tasks showcase NetMamba+'s superior classification performance compared to state-of-the-art baselines, with improvements of up to 6.44\% in F1 score. Moreover, NetMamba+ demonstrates excellent efficiency, achieving 1.7x higher inference throughput than the best baseline while maintaining comparably low memory usage. Furthermore, NetMamba+ exhibits superior few-shot learning abilities, achieving better classification performance with fewer labeled data. Additionally, we implement an online traffic classification system that demonstrates robust real-world performance with a throughput of 261.87 Mb/s. As the first framework to adapt Mamba architecture for network traffic classification, NetMamba+ opens new possibilities for efficient and accurate traffic analysis in complex network environments.
Bias in the Shadows: Explore Shortcuts in Encrypted Network Traffic Classification
Jan 15, 2026Pre-trained models operating directly on raw bytes have achieved promising performance in encrypted network traffic classification (NTC), but often suffer from shortcut learning-relying on spurious correlations that fail to generalize to real-world data. Existing solutions heavily rely on model-specific interpretation techniques, which lack adaptability and generality across different model architectures and deployment scenarios. In this paper, we propose BiasSeeker, the first semi-automated framework that is both model-agnostic and data-driven for detecting dataset-specific shortcut features in encrypted traffic. By performing statistical correlation analysis directly on raw binary traffic, BiasSeeker identifies spurious or environment-entangled features that may compromise generalization, independent of any classifier. To address the diverse nature of shortcut features, we introduce a systematic categorization and apply category-specific validation strategies that reduce bias while preserving meaningful information. We evaluate BiasSeeker on 19 public datasets across three NTC tasks. By emphasizing context-aware feature selection and dataset-specific diagnosis, BiasSeeker offers a novel perspective for understanding and addressing shortcut learning in encrypted network traffic classification, raising awareness that feature selection should be an intentional and scenario-sensitive step prior to model training.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
NetMamba: Efficient Network Traffic Classification via Pre-training Unidirectional Mamba
May 19, 2024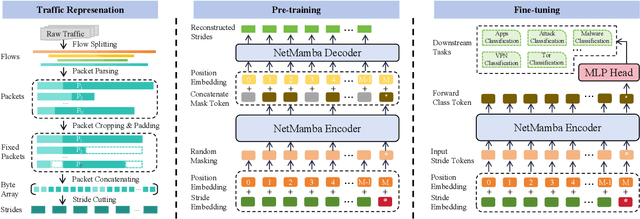
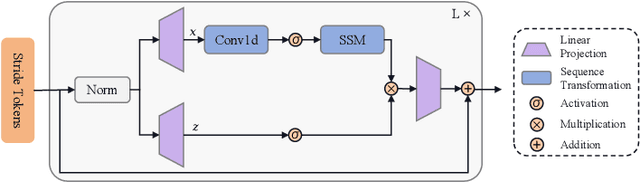
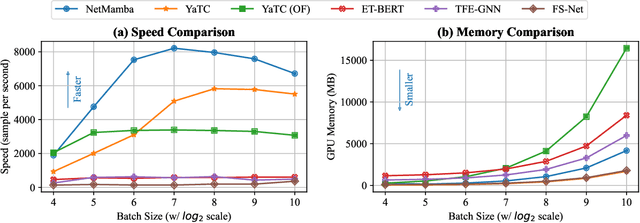
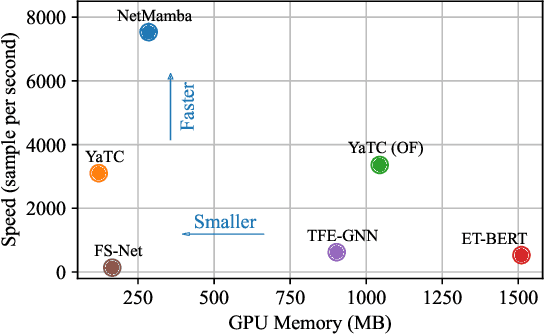
Network traffic classification is a crucial research area aiming to enhance service quality, streamline network management, and bolster cybersecurity. To address the growing complexity of transmission encryption techniques, various machine learning and deep learning methods have been proposed. However, existing approaches encounter two main challenges. Firstly, they struggle with model inefficiency due to the quadratic complexity of the widely used Transformer architecture. Secondly, they suffer from unreliable traffic representation because of discarding important byte information while retaining unwanted biases. To address these challenges, we propose NetMamba, an efficient linear-time state space model equipped with a comprehensive traffic representation scheme. We replace the Transformer with our specially selected and improved Mamba architecture for the networking field to address efficiency issues. In addition, we design a scheme for traffic representation, which is used to extract valid information from massive traffic while removing biased information. Evaluation experiments on six public datasets encompassing three main classification tasks showcase NetMamba's superior classification performance compared to state-of-the-art baselines. It achieves up to 4.83\% higher accuracy and 4.64\% higher f1 score on encrypted traffic classification tasks. Additionally, NetMamba demonstrates excellent efficiency, improving inference speed by 2.24 times while maintaining comparably low memory usage. Furthermore, NetMamba exhibits superior few-shot learning abilities, achieving better classification performance with fewer labeled data. To the best of our knowledge, NetMamba is the first model to tailor the Mamba architecture for networking.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476