 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Deepfake by Creating Spatio-Temporal Regularity Disruption
Paper and Code
Jul 21, 2022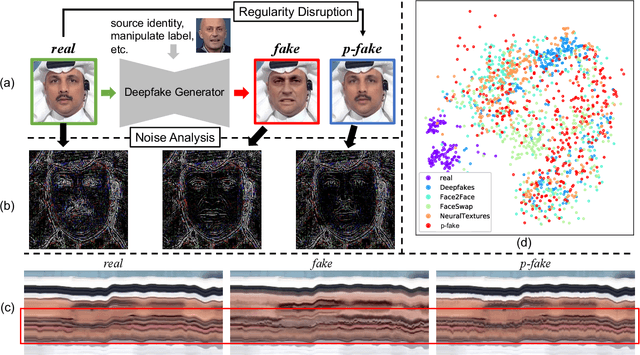
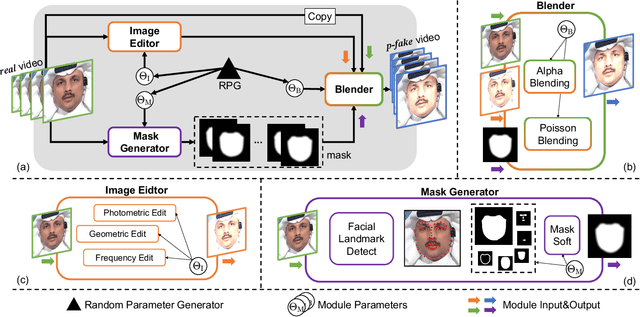
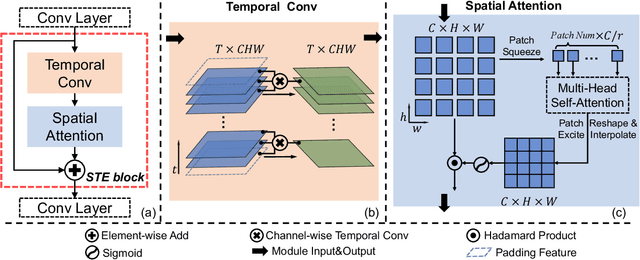
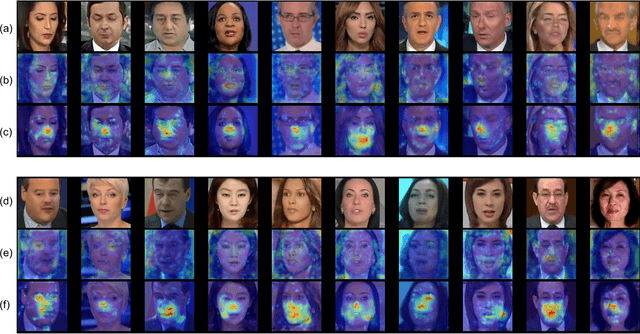
Despite encouraging progress in deepfake detection, generalization to unseen forgery types remains a significant challenge due to the limited forgery clues explored during training. In contrast, we notice a common phenomenon in deepfake: fake video creation inevitably disrupts the statistical regularity in original videos. Inspired by this observation, we propose to boost the generalization of deepfake detection by distinguishing the "regularity disruption" that does not appear in real videos. Specifically, by carefully examining the spatial and temporal properties, we propose to disrupt a real video through a Pseudo-fake Generator and create a wide range of pseudo-fake videos for training. Such practice allows us to achieve deepfake detection without using fake videos and improves the generalization ability in a simple and efficient manner. To jointly capture the spatial and temporal disruptions, we propose a Spatio-Temporal Enhancement block to learn the regularity disruption across space and time on our self-created videos. Through comprehensive experiments, our method exhibits excellent performance on several datasets.