 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSQ+: Improving low-bit quantization through learnable offsets and better initialization
Paper and Code
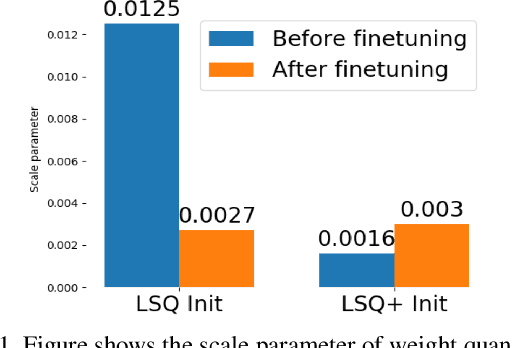

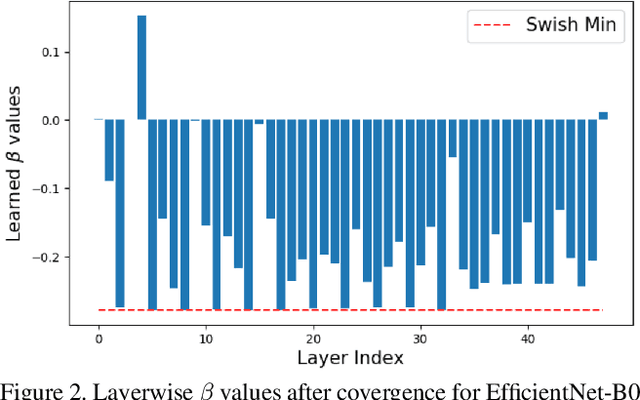
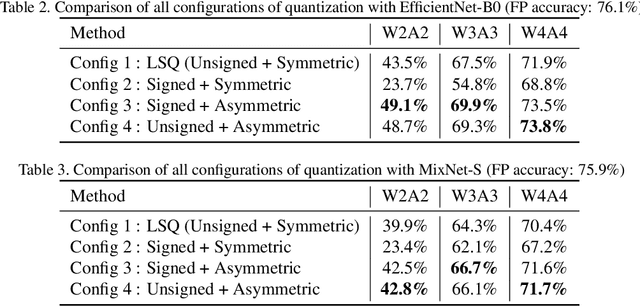
Unlike ReLU, newer activation functions (like Swish, H-swish, Mish) that are frequently employed in popular efficient architectures can also result in negative activation values, with skewed positive and negative ranges. Typical learnable quantization schemes [PACT, LSQ] assume unsigned quantization for activations and quantize all negative activations to zero which leads to significant loss in performance. Naively using signed quantization to accommodate these negative values requires an extra sign bit which is expensive for low-bit (2-, 3-, 4-bit) quantization. To solve this problem, we propose LSQ+, a natural extension of LSQ, wherein we introduce a general asymmetric quantization scheme with trainable scale and offset parameters that can learn to accommodate the negative activations. Gradient-based learnable quantization schemes also commonly suffer from high instability or variance in the final training performance, hence requiring a great deal of hyper-parameter tuning to reach a satisfactory performance. LSQ+ alleviates this problem by using an MSE-based initialization scheme for the quantization parameters. We show that this initialization leads to significantly lower variance in final performance across multiple training runs. Overall, LSQ+ shows state-of-the-art results for EfficientNet and MixNet and also significantly outperforms LSQ for low-bit quantization of neural nets with Swish activations (e.g.: 1.8% gain with W4A4 quantization and upto 5.6% gain with W2A2 quantization of EfficientNet-B0 on ImageNet dataset). To the best of our knowledge, ours is the first work to quantize such architectures to extremely low bit-widths.