 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fully Convolutional Neural Network for Speech Enhancement
Paper and Code
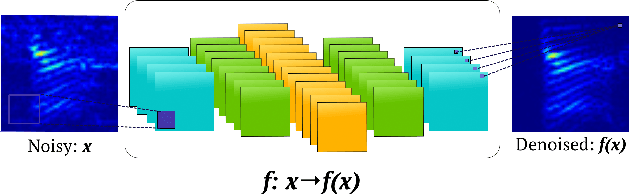

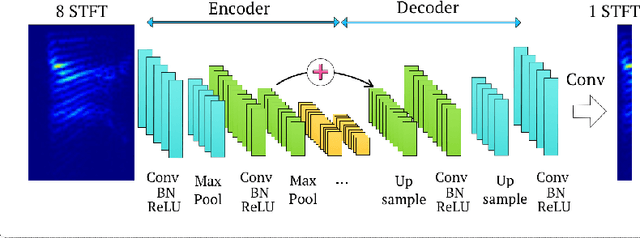

In hearing aids, the presence of babble noise degrades hearing intelligibility of human speech greatly. However, removing the babble without creating artifacts in human speech is a challenging task in a low SNR environment. Here, we sought to solve the problem by finding a `mapping' between noisy speech spectra and clean speech spectra via supervised learning. Specifically, we propose using fully Convolutional Neural Networks, which consist of lesser number of parameters than fully connected networks. The proposed network, Redundant Convolutional Encoder Decoder (R-CED), demonstrates that a convolutional network can be 12 times smaller than a recurrent network and yet achieves better performance, which shows its applicability for an embedded system: the hearing aids.