 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQKD: Quantization-aware Knowledge Distillation
Paper and Code
Nov 28, 2019

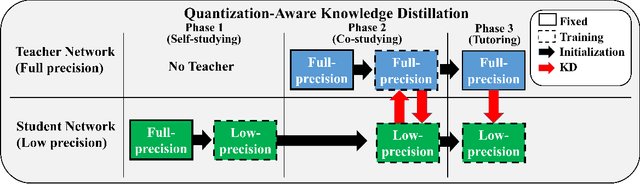
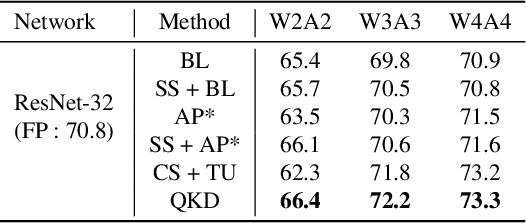
Quantization and Knowledge distillation (KD) methods are widely used to reduce memory and power consumption of deep neural networks (DNNs), especially for resource-constrained edge devices. Although their combination is quite promising to meet these requirements, it may not work as desired. It is mainly because the regularization effect of KD further diminishes the already reduced representation power of a quantized model. To address this short-coming, we propose Quantization-aware Knowledge Distillation (QKD) wherein quantization and KD are care-fully coordinated in three phases. First, Self-studying (SS) phase fine-tunes a quantized low-precision student network without KD to obtain a good initialization. Second, Co-studying (CS) phase tries to train a teacher to make it more quantizaion-friendly and powerful than a fixed teacher. Finally, Tutoring (TU) phase transfers knowledge from the trained teacher to the student. We extensively evaluate our method on ImageNet and CIFAR-10/100 datasets and show an ablation study on networks with both standard and depthwise-separable convolutions. The proposed QKD outperformed existing state-of-the-art methods (e.g., 1.3% improvement on ResNet-18 with W4A4, 2.6% on MobileNetV2 with W4A4). Additionally, QKD could recover the full-precision accuracy at as low as W3A3 quantization on ResNet and W6A6 quantization on MobilenetV2.