 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeskCraft: Benchmarking Desktop Agents on Professional Workflows and Human-in-the-Loop Collaboration
Jun 02, 2026Real-world professional desktop workflows in specialized creative and engineering software unfold over long horizons and often require human-in-the-loop coordination, where agents proactively seek necessary information and users provide additional instructions, clarifications, feedback, or corrections as the task progresses. Yet existing desktop GUI benchmarks mostly reduce this setting to short, simplified tasks with all user instructions provided upfront. To address this issue, we introduce DeskCraft, a desktop GUI benchmark targeting long horizon creative and engineering workflows and proactive human-agent collaboration. DeskCraft organizes tasks into a multilevel difficulty taxonomy, with long horizon tasks requiring over 50 execution steps, and covers professional creative software across design, video, audio, and 3D creation. Furthermore, DeskCraft formalizes human-agent collaboration into an interaction protocol covering mid-turn and post-turn exchanges. Mid-turn interaction captures both agent-initiated clarification under uncertainty and user-initiated interruption during execution, while post-turn interaction accommodates user-driven feedback after the agent signals completion, together spanning the full space of realistic collaboration patterns. We evaluate 18 proprietary and open source agents on 538 tasks and find that GPT-5.4 reaches 31.6% on standard tasks and 27.6% on interactive tasks. Further analyses reveal persistent failures in long horizon workflow delivery and proactive clarification. We will open-source all evaluation codes, tasks, and data at https://github.com/mrwwk/DeskCraft.
Measure Twice, Click Once: Co-evolving Proposer and Visual Critic via Reinforcement Learning for GUI Grounding
Apr 23, 2026Graphical User Interface (GUI) grounding requires mapping natural language instructions to precise pixel coordinates. However, due to visually homogeneous elements and dense layouts, models typically grasp semantic intent yet struggle with achieving precise localization. While scaling sampling attempts (Pass@k) reveals potential gains, static self-consistency strategies derived from geometric clustering often yield limited improvements, as the model's predictions tend to be spatially dispersed. In this paper, we propose replacing static consistency strategies with a learnable selection mechanism that selects the optimal target by critiquing its own proposals rendered on the screenshot. Given the significant disparity between the model's grounding and critiquing capabilities, we propose a co-evolving Propose-then-Critic framework. To jointly optimize these, we introduce a maturity-aware adaptive co-evolutionary reinforcement learning paradigm. This approach dynamically balances the training objectives of proposer and critic, where the diversity of the proposer's outputs enhances critic robustness, while the critic's maturing discrimination capability conversely unlocks the proposer's potential for extensive spatial exploration, fostering the mutual reinforcement and co-evolution of both capabilities, thereby ensuring generalizability to adapt to diverse and complex interface layouts. Extensive experiments over 6 benchmarks show that our method significantly enhances both grounding accuracy and critic reliability.
World-Model-Augmented Web Agents with Action Correction
Feb 17, 2026Web agents based on large language models have demonstrated promising capability in automating web tasks. However, current web agents struggle to reason out sensible actions due to the limitations of predicting environment changes, and might not possess comprehensive awareness of execution risks, prematurely performing risky actions that cause losses and lead to task failure. To address these challenges, we propose WAC, a web agent that integrates model collaboration, consequence simulation, and feedback-driven action refinement. To overcome the cognitive isolation of individual models, we introduce a multi-agent collaboration process that enables an action model to consult a world model as a web-environment expert for strategic guidance; the action model then grounds these suggestions into executable actions, leveraging prior knowledge of environmental state transition dynamics to enhance candidate action proposal. To achieve risk-aware resilient task execution, we introduce a two-stage deduction chain. A world model, specialized in environmental state transitions, simulates action outcomes, which a judge model then scrutinizes to trigger action corrective feedback when necessary. Experiments show that WAC achieves absolute gains of 1.8% on VisualWebArena and 1.3% on Online-Mind2Web.
DPMT: Dual Process Multi-scale Theory of Mind Framework for Real-time Human-AI Collaboration
Jul 18, 2025Real-time human-artificial intelligence (AI) collaboration is crucial yet challenging, especially when AI agents must adapt to diverse and unseen human behaviors in dynamic scenarios. Existing large language model (LLM) agents often fail to accurately model the complex human mental characteristics such as domain intentions, especially in the absence of direct communication. To address this limitation, we propose a novel dual process multi-scale theory of mind (DPMT) framework, drawing inspiration from cognitive science dual process theory. Our DPMT framework incorporates a multi-scale theory of mind (ToM) module to facilitate robust human partner modeling through mental characteristic reasoning. Experimental results demonstrate that DPMT significantly enhances human-AI collaboration, and ablation studies further validate the contributions of our multi-scale ToM in the slow system.
Mixture of personality improved Spiking actor network for efficient multi-agent cooperation
May 10, 2023
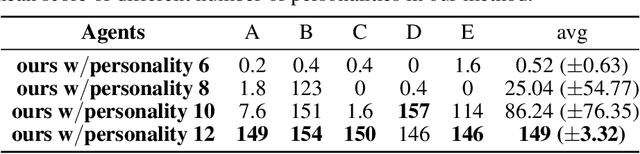

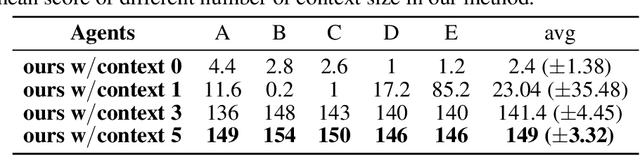
Adaptive human-agent and agent-agent cooperation are becoming more and more critical in the research area of multi-agent reinforcement learning (MARL), where remarked progress has been made with the help of deep neural networks. However, many established algorithms can only perform well during the learning paradigm but exhibit poor generalization during cooperation with other unseen partners. The personality theory in cognitive psychology describes that humans can well handle the above cooperation challenge by predicting others' personalities first and then their complex actions. Inspired by this two-step psychology theory, we propose a biologically plausible mixture of personality (MoP) improved spiking actor network (SAN), whereby a determinantal point process is used to simulate the complex formation and integration of different types of personality in MoP, and dynamic and spiking neurons are incorporated into the SAN for the efficient reinforcement learning. The benchmark Overcooked task, containing a strong requirement for cooperative cooking, is selected to test the proposed MoP-SAN. The experimental results show that the MoP-SAN can achieve both high performances during not only the learning paradigm but also the generalization test (i.e., cooperation with other unseen agents) paradigm where most counterpart deep actor networks failed. Necessary ablation experiments and visualization analyses were conducted to explain why MoP and SAN are effective in multi-agent reinforcement learning scenarios while DNN performs poorly in the generalization test.
Offline Pre-trained Multi-Agent Decision Transformer: One Big Sequence Model Tackles All SMAC Tasks
Dec 20, 2021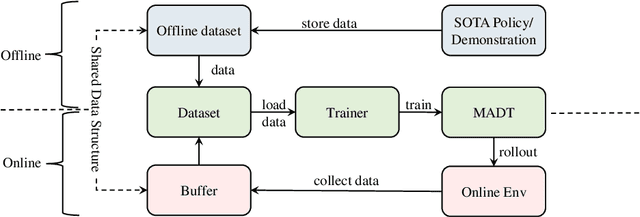
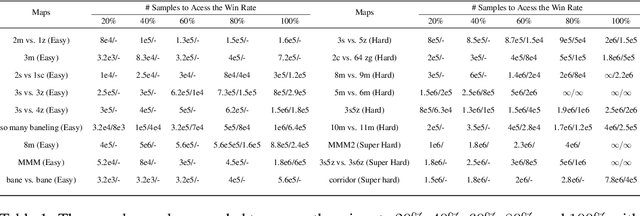
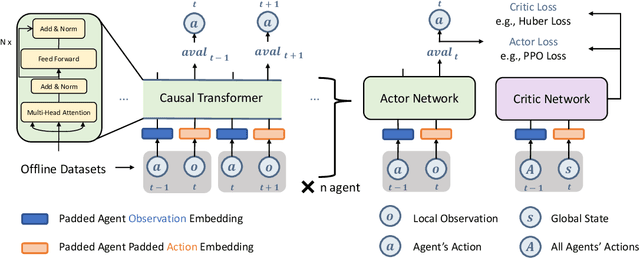
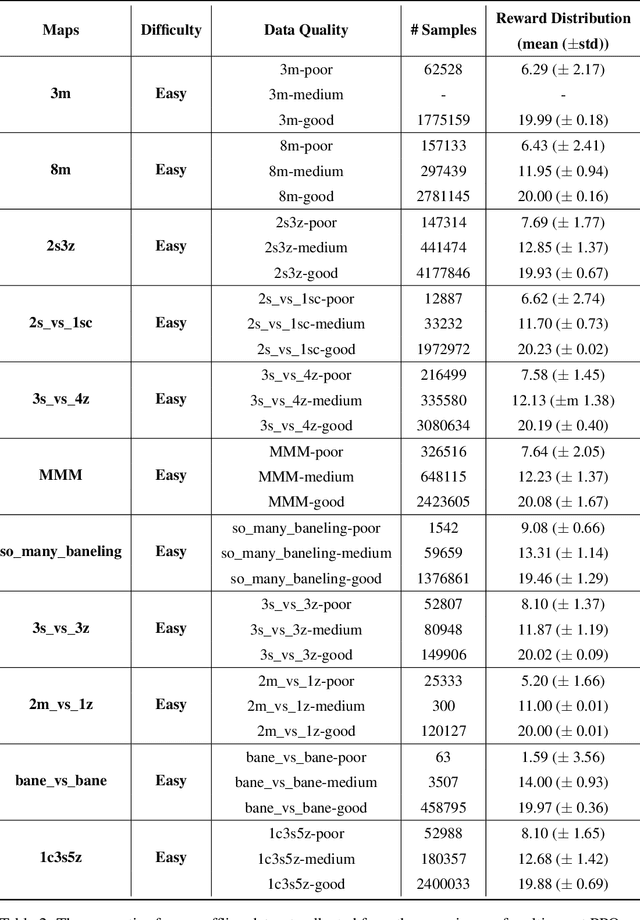
Offline reinforcement learning leverages previously-collected offline datasets to learn optimal policies with no necessity to access the real environment. Such a paradigm is also desirable for multi-agent reinforcement learning (MARL) tasks, given the increased interactions among agents and with the enviroment. Yet, in MARL, the paradigm of offline pre-training with online fine-tuning has not been studied, nor datasets or benchmarks for offline MARL research are available. In this paper, we facilitate the research by providing large-scale datasets, and use them to examine the usage of the Decision Transformer in the context of MARL. We investigate the generalisation of MARL offline pre-training in the following three aspects: 1) between single agents and multiple agents, 2) from offline pretraining to the online fine-tuning, and 3) to that of multiple downstream tasks with few-shot and zero-shot capabilities. We start by introducing the first offline MARL dataset with diverse quality levels based on the StarCraftII environment, and then propose the novel architecture of multi-agent decision transformer (MADT) for effective offline learning. MADT leverages transformer's modelling ability of sequence modelling and integrates it seamlessly with both offline and online MARL tasks. A crucial benefit of MADT is that it learns generalizable policies that can transfer between different types of agents under different task scenarios. On StarCraft II offline dataset, MADT outperforms the state-of-the-art offline RL baselines. When applied to online tasks, the pre-trained MADT significantly improves sample efficiency, and enjoys strong performance both few-short and zero-shot cases. To our best knowledge, this is the first work that studies and demonstrates the effectiveness of offline pre-trained models in terms of sample efficiency and generalisability enhancements in MARL.
MIMO Self-attentive RNN Beamformer for Multi-speaker Speech Separation
Apr 26, 2021
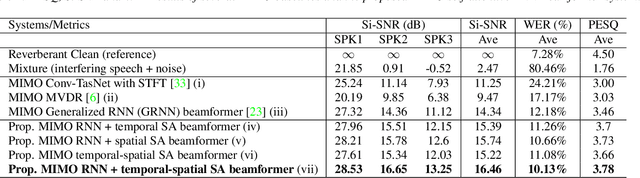

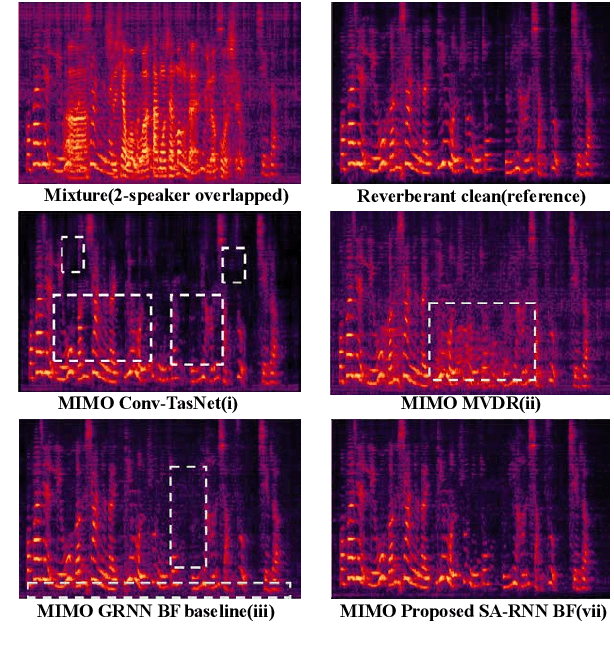
Recently, our proposed recurrent neural network (RNN) based all deep learning minimum variance distortionless response (ADL-MVDR) beamformer method yielded superior performance over the conventional MVDR by replacing the matrix inversion and eigenvalue decomposition with two recurrent neural networks. In this work, we present a self-attentive RNN beamformer to further improve our previous RNN-based beamformer by leveraging on the powerful modeling capability of self-attention. Temporal-spatial self-attention module is proposed to better learn the beamforming weights from the speech and noise spatial covariance matrices. The temporal self-attention module could help RNN to learn global statistics of covariance matrices. The spatial self-attention module is designed to attend on the cross-channel correlation in the covariance matrices. Furthermore, a multi-channel input with multi-speaker directional features and multi-speaker speech separation outputs (MIMO) model is developed to improve the inference efficiency. The evaluations demonstrate that our proposed MIMO self-attentive RNN beamformer improves both the automatic speech recognition (ASR) accuracy and the perceptual estimation of speech quality (PESQ) against prior arts.