 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Magic of Code Reasoning through Hypothesis Decomposition and Amendment
Feb 17, 2025The reasoning abilities are one of the most enigmatic and captivating aspects of large language models (LLMs). Numerous studies are dedicated to exploring and expanding the boundaries of this reasoning capability. However, tasks that embody both reasoning and recall characteristics are often overlooked. In this paper, we introduce such a novel task, code reasoning, to provide a new perspective for the reasoning abilities of LLMs. We summarize three meta-benchmarks based on established forms of logical reasoning, and instantiate these into eight specific benchmark tasks. Our testing on these benchmarks reveals that LLMs continue to struggle with identifying satisfactory reasoning pathways. Additionally, we present a new pathway exploration pipeline inspired by human intricate problem-solving methods. This Reflective Hypothesis Decomposition and Amendment (RHDA) pipeline consists of the following iterative steps: (1) Proposing potential hypotheses based on observations and decomposing them; (2) Utilizing tools to validate hypotheses and reflection outcomes; (3) Revising hypothesis in light of observations. Our approach effectively mitigates logical chain collapses arising from forgetting or hallucination issues in multi-step reasoning, resulting in performance gains of up to $3\times$. Finally, we expanded this pipeline by applying it to simulate complex household tasks in real-world scenarios, specifically in VirtualHome, enhancing the handling of failure cases. We release our code and all of results at https://github.com/TnTWoW/code_reasoning.
Collaborative Evolving Strategy for Automatic Data-Centric Development
Jul 26, 2024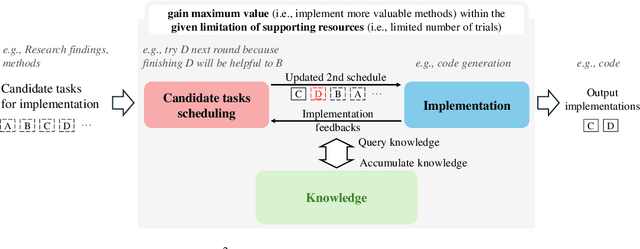

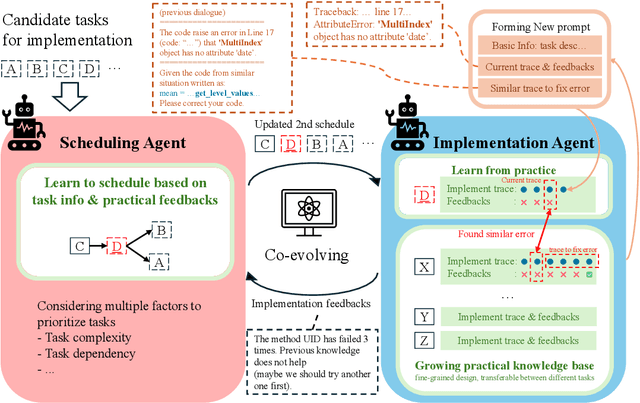
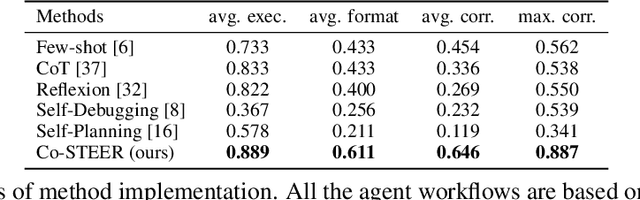
Artificial Intelligence (AI) significantly influences many fields, largely thanks to the vast amounts of high-quality data for machine learning models. The emphasis is now on a data-centric AI strategy, prioritizing data development over model design progress. Automating this process is crucial. In this paper, we serve as the first work to introduce the automatic data-centric development (AD^2) task and outline its core challenges, which require domain-experts-like task scheduling and implementation capability, largely unexplored by previous work. By leveraging the strong complex problem-solving capabilities of large language models (LLMs), we propose an LLM-based autonomous agent, equipped with a strategy named Collaborative Knowledge-STudying-Enhanced Evolution by Retrieval (Co-STEER), to simultaneously address all the challenges. Specifically, our proposed Co-STEER agent enriches its domain knowledge through our proposed evolving strategy and develops both its scheduling and implementation skills by accumulating and retrieving domain-specific practical experience. With an improved schedule, the capability for implementation accelerates. Simultaneously, as implementation feedback becomes more thorough, the scheduling accuracy increases. These two capabilities evolve together through practical feedback, enabling a collaborative evolution process. Extensive experimental results demonstrate that our Co-STEER agent breaks new ground in AD^2 research, possesses strong evolvable schedule and implementation ability, and demonstrates the significant effectiveness of its components. Our Co-STEER paves the way for AD^2 advancements.