 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Evolving Strategy for Automatic Data-Centric Development
Jul 26, 2024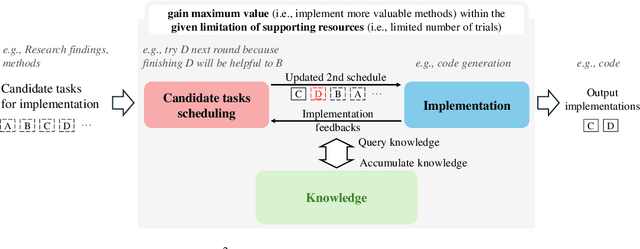

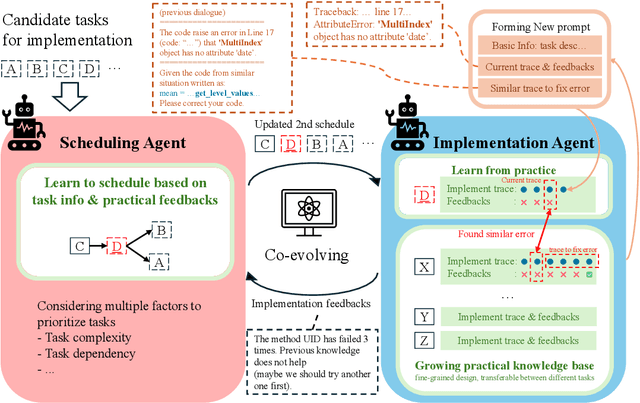
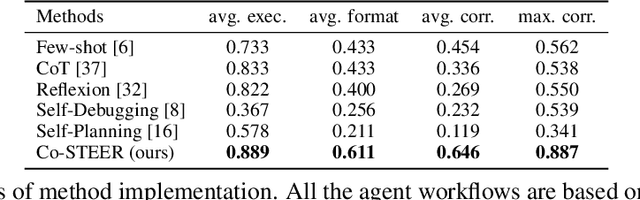
Artificial Intelligence (AI) significantly influences many fields, largely thanks to the vast amounts of high-quality data for machine learning models. The emphasis is now on a data-centric AI strategy, prioritizing data development over model design progress. Automating this process is crucial. In this paper, we serve as the first work to introduce the automatic data-centric development (AD^2) task and outline its core challenges, which require domain-experts-like task scheduling and implementation capability, largely unexplored by previous work. By leveraging the strong complex problem-solving capabilities of large language models (LLMs), we propose an LLM-based autonomous agent, equipped with a strategy named Collaborative Knowledge-STudying-Enhanced Evolution by Retrieval (Co-STEER), to simultaneously address all the challenges. Specifically, our proposed Co-STEER agent enriches its domain knowledge through our proposed evolving strategy and develops both its scheduling and implementation skills by accumulating and retrieving domain-specific practical experience. With an improved schedule, the capability for implementation accelerates. Simultaneously, as implementation feedback becomes more thorough, the scheduling accuracy increases. These two capabilities evolve together through practical feedback, enabling a collaborative evolution process. Extensive experimental results demonstrate that our Co-STEER agent breaks new ground in AD^2 research, possesses strong evolvable schedule and implementation ability, and demonstrates the significant effectiveness of its components. Our Co-STEER paves the way for AD^2 advancements.
CatBoost model with synthetic features in application to loan risk assessment of small businesses
Jun 30, 2021



Loan risk for small businesses has long been a complex problem worthy of exploring. Predicting the loan risk can benefit entrepreneurship by developing more jobs for the society. CatBoost (Categorical Boosting) is a powerful machine learning algorithm suitable for dataset with many categorical variables like the dataset for forecasting loan risk. In this paper, we identify the important risk factors that contribute to loan status classification problem. Then we compare the performance between boosting-type algorithms(especially CatBoost) with other traditional yet popular ones. The dataset we adopt in the research comes from the U.S. Small Business Administration (SBA) and holds a very large sample size (899,164 observations and 27 features). In order to make the best use of the important features in the dataset, we propose a technique named "synthetic generation" to develop more combined features based on arithmetic operation, which ends up improving the accuracy and AUC of the original CatBoost model. We obtain a high accuracy of 95.84% and well-performed AUC of 98.80% compared with the existent literature of related research.