 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and Conquer: Heterogeneous Noise Integration for Diffusion-based Adversarial Purification
Mar 03, 2025Existing diffusion-based purification methods aim to disrupt adversarial perturbations by introducing a certain amount of noise through a forward diffusion process, followed by a reverse process to recover clean examples. However, this approach is fundamentally flawed: the uniform operation of the forward process across all pixels compromises normal pixels while attempting to combat adversarial perturbations, resulting in the target model producing incorrect predictions. Simply relying on low-intensity noise is insufficient for effective defense. To address this critical issue, we implement a heterogeneous purification strategy grounded in the interpretability of neural networks. Our method decisively applies higher-intensity noise to specific pixels that the target model focuses on while the remaining pixels are subjected to only low-intensity noise. This requirement motivates us to redesign the sampling process of the diffusion model, allowing for the effective removal of varying noise levels. Furthermore, to evaluate our method against strong adaptative attack, our proposed method sharply reduces time cost and memory usage through a single-step resampling. The empirical evidence from extensive experiments across three datasets demonstrates that our method outperforms most current adversarial training and purification techniques by a substantial margin.
SSE-SAM: Balancing Head and Tail Classes Gradually through Stage-Wise SAM
Dec 18, 2024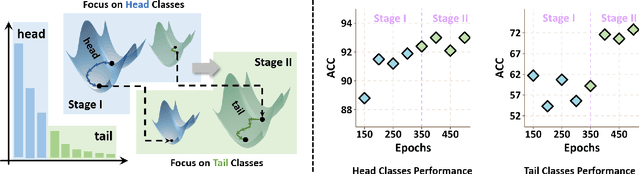
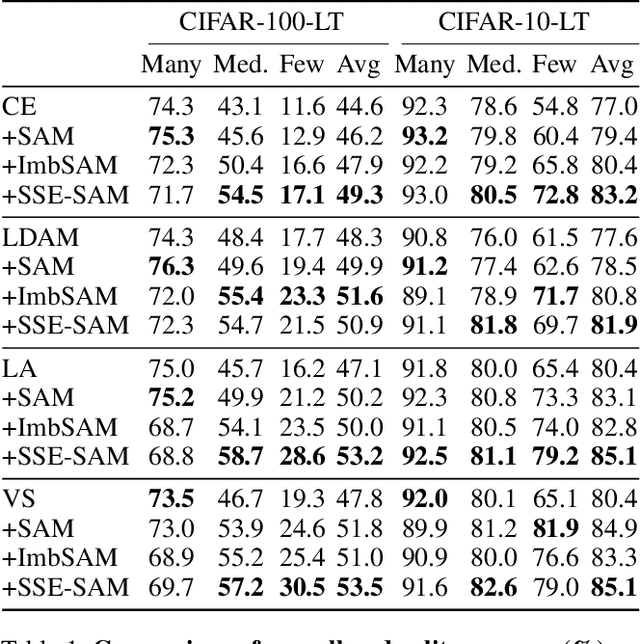
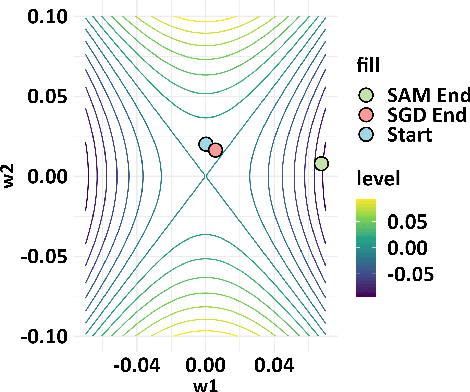
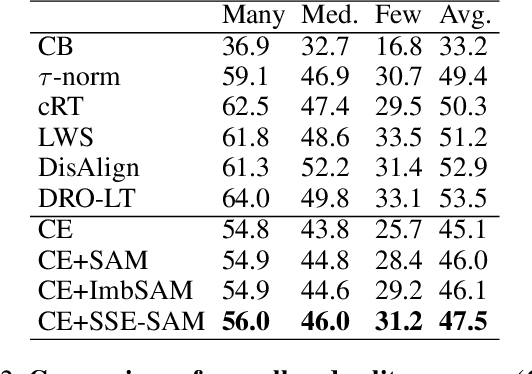
Real-world datasets often exhibit a long-tailed distribution, where vast majority of classes known as tail classes have only few samples. Traditional methods tend to overfit on these tail classes. Recently, a new approach called Imbalanced SAM (ImbSAM) is proposed to leverage the generalization benefits of Sharpness-Aware Minimization (SAM) for long-tailed distributions. The main strategy is to merely enhance the smoothness of the loss function for tail classes. However, we argue that improving generalization in long-tail scenarios requires a careful balance between head and tail classes. We show that neither SAM nor ImbSAM alone can fully achieve this balance. For SAM, we prove that although it enhances the model's generalization ability by escaping saddle point in the overall loss landscape, it does not effectively address this for tail-class losses. Conversely, while ImbSAM is more effective at avoiding saddle points in tail classes, the head classes are trained insufficiently, resulting in significant performance drops. Based on these insights, we propose Stage-wise Saddle Escaping SAM (SSE-SAM), which uses complementary strengths of ImbSAM and SAM in a phased approach. Initially, SSE-SAM follows the majority sample to avoid saddle points of the head-class loss. During the later phase, it focuses on tail-classes to help them escape saddle points. Our experiments confirm that SSE-SAM has better ability in escaping saddles both on head and tail classes, and shows performance improvements.