 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Condition Numbers: Why is GLU Better than non-GLU Structure?
May 20, 2026Gated Linear Units (GLU) and their variants are widely adopted in modern open-source large language model architectures and consistently outperform their non-gated counterparts, yet the underlying reasons for this advantage remain unclear. In this work, we study GLU by analyzing two-layer networks in the neural tangent kernel (NTK) regime. Our analysis reveals that the GLU structure reshapes the NTK spectrum, leading to a smaller condition number and a more compact eigenvalue distribution. Building on this finding, we further analyze the resulting training dynamics and show how the reshaped spectrum leads to faster convergence of GLU models, including a characteristic loss-crossing phenomenon observed between GLU and non-GLU models. Finally, we empirically observe that GLU has limited impact in reducing the generalization gap on various models, including ViT and GPT-2, suggesting that its primary benefit lies in accelerating optimization rather than reducing the generalization gap.
ADAM: A Systematic Data Extraction Attack on Agent Memory via Adaptive Querying
Apr 10, 2026Large Language Model (LLM) agents have achieved rapid adoption and demonstrated remarkable capabilities across a wide range of applications. To improve reasoning and task execution, modern LLM agents would incorporate memory modules or retrieval-augmented generation (RAG) mechanisms, enabling them to further leverage prior interactions or external knowledge. However, such a design also introduces a group of critical privacy vulnerabilities: sensitive information stored in memory can be leaked through query-based attacks. Although feasible, existing attacks often achieve only limited performance, with low attack success rates (ASR). In this paper, we propose ADAM, a novel privacy attack that features data distribution estimation of a victim agent's memory and employs an entropy-guided query strategy for maximizing privacy leakage. Extensive experiments demonstrate that our attack substantially outperforms state-of-the-art ones, achieving up to 100% ASRs. These results thus underscore the urgent need for robust privacy-preserving methods for current LLM agents.
Buffer is All You Need: Defending Federated Learning against Backdoor Attacks under Non-iids via Buffering
Mar 30, 2025



Federated Learning (FL) is a popular paradigm enabling clients to jointly train a global model without sharing raw data. However, FL is known to be vulnerable towards backdoor attacks due to its distributed nature. As participants, attackers can upload model updates that effectively compromise FL. What's worse, existing defenses are mostly designed under independent-and-identically-distributed (iid) settings, hence neglecting the fundamental non-iid characteristic of FL. Here we propose FLBuff for tackling backdoor attacks even under non-iids. The main challenge for such defenses is that non-iids bring benign and malicious updates closer, hence harder to separate. FLBuff is inspired by our insight that non-iids can be modeled as omni-directional expansion in representation space while backdoor attacks as uni-directional. This leads to the key design of FLBuff, i.e., a supervised-contrastive-learning model extracting penultimate-layer representations to create a large in-between buffer layer. Comprehensive evaluations demonstrate that FLBuff consistently outperforms state-of-the-art defenses.
Two Heads Are Better than One: Model-Weight and Latent-Space Analysis for Federated Learning on Non-iid Data against Poisoning Attacks
Mar 30, 2025



Federated Learning is a popular paradigm that enables remote clients to jointly train a global model without sharing their raw data. However, FL has been shown to be vulnerable towards model poisoning attacks due to its distributed nature. Particularly, attackers acting as participants can upload arbitrary model updates that effectively compromise the global model of FL. While extensive research has been focusing on fighting against these attacks, we find that most of them assume data at remote clients are under iid while in practice they are inevitably non-iid. Our benchmark evaluations reveal that existing defenses generally fail to live up to their reputation when applied to various non-iid scenarios. In this paper, we propose a novel approach, GeminiGuard, that aims to address such a significant gap. We design GeminiGuard to be lightweight, versatile, and unsupervised so that it aligns well with the practical requirements of deploying such defenses. The key challenge from non-iids is that they make benign model updates look more similar to malicious ones. GeminiGuard is mainly built on two fundamental observations: (1) existing defenses based on either model-weight analysis or latent-space analysis face limitations in covering different MPAs and non-iid scenarios, and (2) model-weight and latent-space analysis are sufficiently different yet potentially complementary methods as MPA defenses. We hence incorporate a novel model-weight analysis component as well as a custom latent-space analysis component in GeminiGuard, aiming to further enhance its defense performance. We conduct extensive experiments to evaluate our defense across various settings, demonstrating its effectiveness in countering multiple types of untargeted and targeted MPAs, including adaptive ones. Our comprehensive evaluations show that GeminiGuard consistently outperforms SOTA defenses under various settings.
SSE-SAM: Balancing Head and Tail Classes Gradually through Stage-Wise SAM
Dec 18, 2024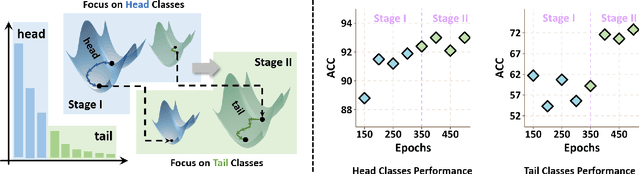
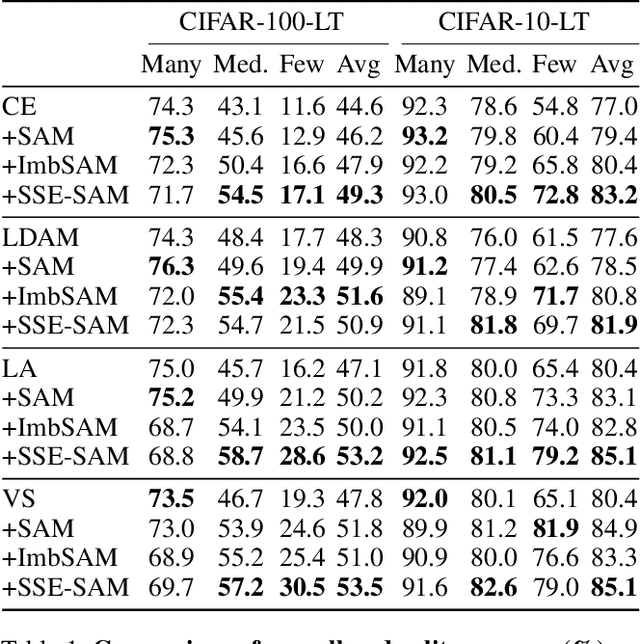
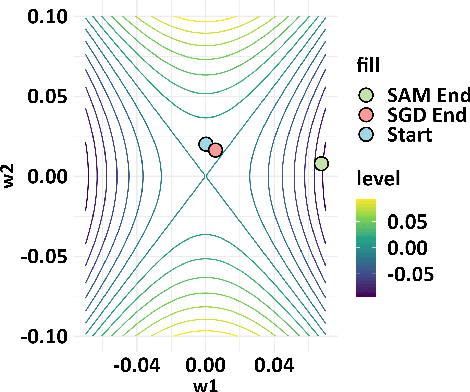
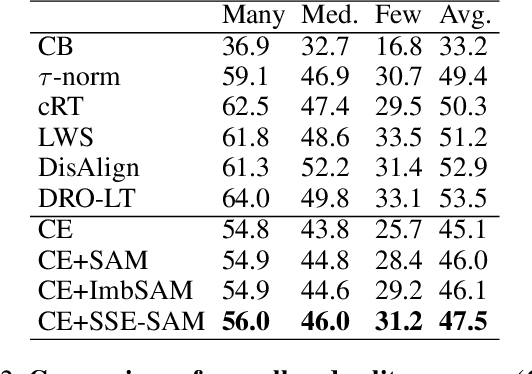
Real-world datasets often exhibit a long-tailed distribution, where vast majority of classes known as tail classes have only few samples. Traditional methods tend to overfit on these tail classes. Recently, a new approach called Imbalanced SAM (ImbSAM) is proposed to leverage the generalization benefits of Sharpness-Aware Minimization (SAM) for long-tailed distributions. The main strategy is to merely enhance the smoothness of the loss function for tail classes. However, we argue that improving generalization in long-tail scenarios requires a careful balance between head and tail classes. We show that neither SAM nor ImbSAM alone can fully achieve this balance. For SAM, we prove that although it enhances the model's generalization ability by escaping saddle point in the overall loss landscape, it does not effectively address this for tail-class losses. Conversely, while ImbSAM is more effective at avoiding saddle points in tail classes, the head classes are trained insufficiently, resulting in significant performance drops. Based on these insights, we propose Stage-wise Saddle Escaping SAM (SSE-SAM), which uses complementary strengths of ImbSAM and SAM in a phased approach. Initially, SSE-SAM follows the majority sample to avoid saddle points of the head-class loss. During the later phase, it focuses on tail-classes to help them escape saddle points. Our experiments confirm that SSE-SAM has better ability in escaping saddles both on head and tail classes, and shows performance improvements.