 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCannot See the Forest for the Trees: Invoking Heuristics and Biases to Elicit Irrational Choices of LLMs
May 03, 2025Despite the remarkable performance of Large Language Models (LLMs), they remain vulnerable to jailbreak attacks, which can compromise their safety mechanisms. Existing studies often rely on brute-force optimization or manual design, failing to uncover potential risks in real-world scenarios. To address this, we propose a novel jailbreak attack framework, ICRT, inspired by heuristics and biases in human cognition. Leveraging the simplicity effect, we employ cognitive decomposition to reduce the complexity of malicious prompts. Simultaneously, relevance bias is utilized to reorganize prompts, enhancing semantic alignment and inducing harmful outputs effectively. Furthermore, we introduce a ranking-based harmfulness evaluation metric that surpasses the traditional binary success-or-failure paradigm by employing ranking aggregation methods such as Elo, HodgeRank, and Rank Centrality to comprehensively quantify the harmfulness of generated content. Experimental results show that our approach consistently bypasses mainstream LLMs' safety mechanisms and generates high-risk content, providing insights into jailbreak attack risks and contributing to stronger defense strategies.
Elliptic Loss Regularization
Mar 04, 2025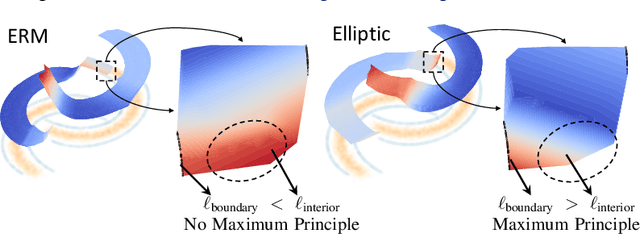

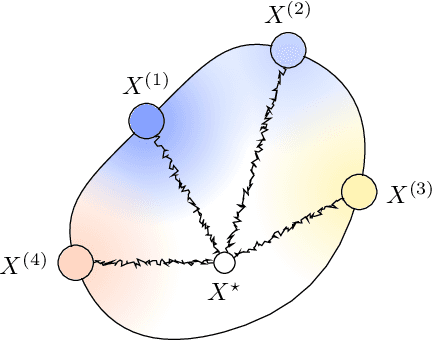
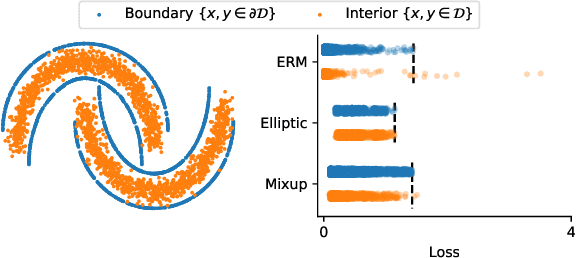
Regularizing neural networks is important for anticipating model behavior in regions of the data space that are not well represented. In this work, we propose a regularization technique for enforcing a level of smoothness in the mapping between the data input space and the loss value. We specify the level of regularity by requiring that the loss of the network satisfies an elliptic operator over the data domain. To do this, we modify the usual empirical risk minimization objective such that we instead minimize a new objective that satisfies an elliptic operator over points within the domain. This allows us to use existing theory on elliptic operators to anticipate the behavior of the error for points outside the training set. We propose a tractable computational method that approximates the behavior of the elliptic operator while being computationally efficient. Finally, we analyze the properties of the proposed regularization to understand the performance on common problems of distribution shift and group imbalance. Numerical experiments confirm the utility of the proposed regularization technique.
Parabolic Continual Learning
Mar 03, 2025



Regularizing continual learning techniques is important for anticipating algorithmic behavior under new realizations of data. We introduce a new approach to continual learning by imposing the properties of a parabolic partial differential equation (PDE) to regularize the expected behavior of the loss over time. This class of parabolic PDEs has a number of favorable properties that allow us to analyze the error incurred through forgetting and the error induced through generalization. Specifically, we do this through imposing boundary conditions where the boundary is given by a memory buffer. By using the memory buffer as a boundary, we can enforce long term dependencies by bounding the expected error by the boundary loss. Finally, we illustrate the empirical performance of the method on a series of continual learning tasks.
S2TX: Cross-Attention Multi-Scale State-Space Transformer for Time Series Forecasting
Feb 17, 2025Time series forecasting has recently achieved significant progress with multi-scale models to address the heterogeneity between long and short range patterns. Despite their state-of-the-art performance, we identify two potential areas for improvement. First, the variates of the multivariate time series are processed independently. Moreover, the multi-scale (long and short range) representations are learned separately by two independent models without communication. In light of these concerns, we propose State Space Transformer with cross-attention (S2TX). S2TX employs a cross-attention mechanism to integrate a Mamba model for extracting long-range cross-variate context and a Transformer model with local window attention to capture short-range representations. By cross-attending to the global context, the Transformer model further facilitates variate-level interactions as well as local/global communications. Comprehensive experiments on seven classic long-short range time-series forecasting benchmark datasets demonstrate that S2TX can achieve highly robust SOTA results while maintaining a low memory footprint.
Neural McKean-Vlasov Processes: Distributional Dependence in Diffusion Processes
Apr 15, 2024McKean-Vlasov stochastic differential equations (MV-SDEs) provide a mathematical description of the behavior of an infinite number of interacting particles by imposing a dependence on the particle density. As such, we study the influence of explicitly including distributional information in the parameterization of the SDE. We propose a series of semi-parametric methods for representing MV-SDEs, and corresponding estimators for inferring parameters from data based on the properties of the MV-SDE. We analyze the characteristics of the different architectures and estimators, and consider their applicability in relevant machine learning problems. We empirically compare the performance of the different architectures and estimators on real and synthetic datasets for time series and probabilistic modeling. The results suggest that explicitly including distributional dependence in the parameterization of the SDE is effective in modeling temporal data with interaction under an exchangeability assumption while maintaining strong performance for standard It\^o-SDEs due to the richer class of probability flows associated with MV-SDEs.