 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEADRE: Multi-Faceted Knowledge Enhanced LLM Empowered Display Advertisement Recommender System
Nov 21, 2024



Display advertising provides significant value to advertisers, publishers, and users. Traditional display advertising systems utilize a multi-stage architecture consisting of retrieval, coarse ranking, and final ranking. However, conventional retrieval methods rely on ID-based learning to rank mechanisms and fail to adequately utilize the content information of ads, which hampers their ability to provide diverse recommendation lists. To address this limitation, we propose leveraging the extensive world knowledge of LLMs. However, three key challenges arise when attempting to maximize the effectiveness of LLMs: "How to capture user interests", "How to bridge the knowledge gap between LLMs and advertising system", and "How to efficiently deploy LLMs". To overcome these challenges, we introduce a novel LLM-based framework called LLM Empowered Display ADvertisement REcommender system (LEADRE). LEADRE consists of three core modules: (1) The Intent-Aware Prompt Engineering introduces multi-faceted knowledge and designs intent-aware <Prompt, Response> pairs that fine-tune LLMs to generate ads tailored to users' personal interests. (2) The Advertising-Specific Knowledge Alignment incorporates auxiliary fine-tuning tasks and Direct Preference Optimization (DPO) to align LLMs with ad semantic and business value. (3) The Efficient System Deployment deploys LEADRE in an online environment by integrating both latency-tolerant and latency-sensitive service. Extensive offline experiments demonstrate the effectiveness of LEADRE and validate the contributions of individual modules. Online A/B test shows that LEADRE leads to a 1.57% and 1.17% GMV lift for serviced users on WeChat Channels and Moments separately. LEADRE has been deployed on both platforms, serving tens of billions of requests each day.
Towards Scalable Semantic Representation for Recommendation
Oct 12, 2024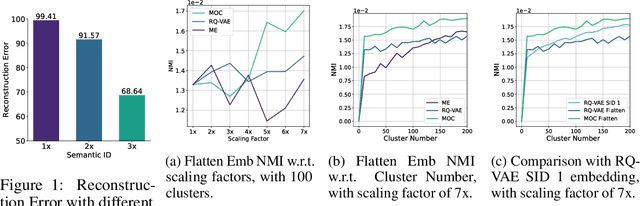
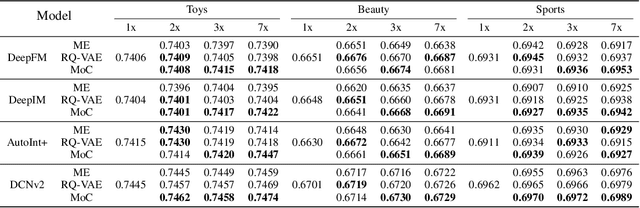
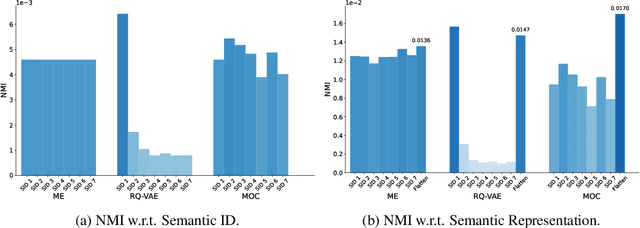
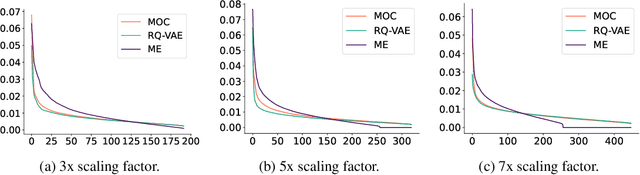
With recent advances in large language models (LLMs), there has been emerging numbers of research in developing Semantic IDs based on LLMs to enhance the performance of recommendation systems. However, the dimension of these embeddings needs to match that of the ID embedding in recommendation, which is usually much smaller than the original length. Such dimension compression results in inevitable losses in discriminability and dimension robustness of the LLM embeddings, which motivates us to scale up the semantic representation. In this paper, we propose Mixture-of-Codes, which first constructs multiple independent codebooks for LLM representation in the indexing stage, and then utilizes the Semantic Representation along with a fusion module for the downstream recommendation stage. Extensive analysis and experiments demonstrate that our method achieves superior discriminability and dimension robustness scalability, leading to the best scale-up performance in recommendations.