 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Semantic Representation for Recommendation
Paper and Code
Oct 12, 2024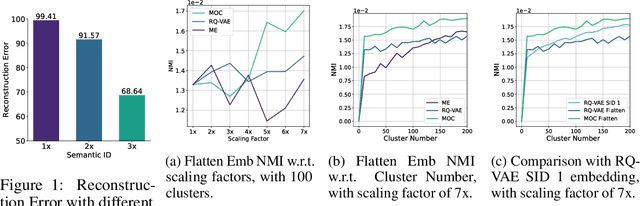
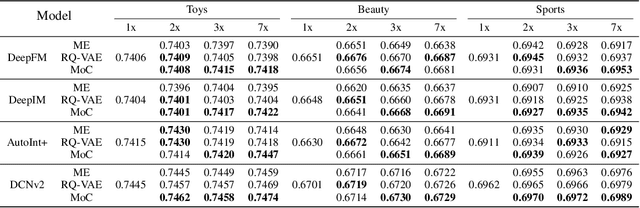
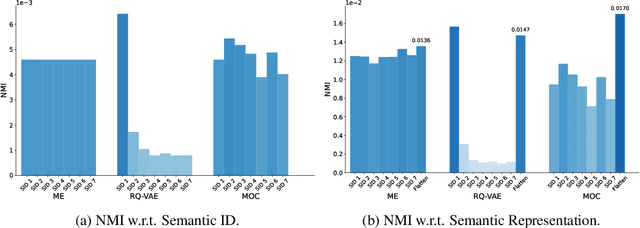
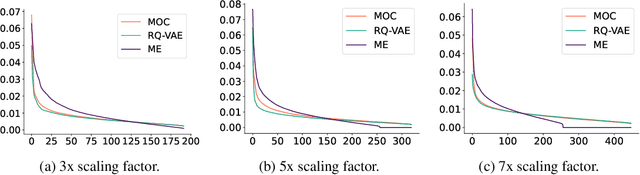
With recent advances in large language models (LLMs), there has been emerging numbers of research in developing Semantic IDs based on LLMs to enhance the performance of recommendation systems. However, the dimension of these embeddings needs to match that of the ID embedding in recommendation, which is usually much smaller than the original length. Such dimension compression results in inevitable losses in discriminability and dimension robustness of the LLM embeddings, which motivates us to scale up the semantic representation. In this paper, we propose Mixture-of-Codes, which first constructs multiple independent codebooks for LLM representation in the indexing stage, and then utilizes the Semantic Representation along with a fusion module for the downstream recommendation stage. Extensive analysis and experiments demonstrate that our method achieves superior discriminability and dimension robustness scalability, leading to the best scale-up performance in recommendations.