 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSH-Bench: A Difficulty- and Scenario-Aware Benchmark with Hierarchical Subject Taxonomy for Subject-Driven Text-to-Image Generation
Mar 09, 2026Significant progress has been achieved in subject-driven text-to-image (T2I) generation, which aims to synthesize new images depicting target subjects according to user instructions. However, evaluating these models remains a significant challenge. Existing benchmarks exhibit critical limitations: 1) insufficient diversity and comprehensiveness in subject images, 2) inadequate granularity in assessing model performance across different subject difficulty levels and prompt scenarios, and 3) a profound lack of actionable insights and diagnostic guidance for subsequent model refinement. To address these limitations, we propose DSH-Bench, a comprehensive benchmark that enables systematic multi-perspective analysis of subject-driven T2I models through four principal innovations: 1) a hierarchical taxonomy sampling mechanism ensuring comprehensive subject representation across 58 fine-grained categories, 2) an innovative classification scheme categorizing both subject difficulty level and prompt scenario for granular capability assessment, 3) a novel Subject Identity Consistency Score (SICS) metric demonstrating a 9.4\% higher correlation with human evaluation compared to existing measures in quantifying subject preservation, and 4) a comprehensive set of diagnostic insights derived from the benchmark, offering critical guidance for optimizing future model training paradigms and data construction strategies. Through an extensive empirical evaluation of 19 leading models, DSH-Bench uncovers previously obscured limitations in current approaches, establishing concrete directions for future research and development.
DiffuReason: Bridging Latent Reasoning and Generative Refinement for Sequential Recommendation
Feb 12, 2026Latent reasoning has emerged as a promising paradigm for sequential recommendation, enabling models to capture complex user intent through multi-step deliberation. Yet existing approaches often rely on deterministic latent chains that accumulate noise and overlook the uncertainty inherent in user intent, and they are typically trained in staged pipelines that hinder joint optimization and exploration. To address these challenges, we propose DiffuReason, a unified "Think-then-Diffuse" framework for sequential recommendation. It integrates multi-step Thinking Tokens for latent reasoning, diffusion-based refinement for denoising intermediate representations, and end-to-end Group Relative Policy Optimization (GRPO) alignment to optimize for ranking performance. In the Think stage, the model generates Thinking Tokens that reason over user history to form an initial intent hypothesis. In the Diffuse stage, rather than treating this hypothesis as the final output, we refine it through a diffusion process that models user intent as a probabilistic distribution, providing iterative denoising against reasoning noise. Finally, GRPO-based reinforcement learning enables the reasoning and refinement modules to co-evolve throughout training, without the constraints of staged optimization. Extensive experiments on four benchmarks demonstrate that DiffuReason consistently improves diverse backbone architectures. Online A/B tests on a large-scale industrial platform further validate its practical effectiveness.
Technical Indicator Networks (TINs): An Interpretable Neural Architecture Modernizing Classic al Technical Analysis for Adaptive Algorithmic Trading
Jul 27, 2025This work proposes that a vast majority of classical technical indicators in financial analysis are, in essence, special cases of neural networks with fixed and interpretable weights. It is shown that nearly all such indicators, such as moving averages, momentum-based oscillators, volatility bands, and other commonly used technical constructs, can be reconstructed topologically as modular neural network components. Technical Indicator Networks (TINs) are introduced as a general neural architecture that replicates and structurally upgrades traditional indicators by supporting n-dimensional inputs such as price, volume, sentiment, and order book data. By encoding domain-specific knowledge into neural structures, TINs modernize the foundational logic of technical analysis and propel algorithmic trading into a new era, bridging the legacy of proven indicators with the potential of contemporary AI systems.
Large Point-to-Gaussian Model for Image-to-3D Generation
Aug 20, 2024


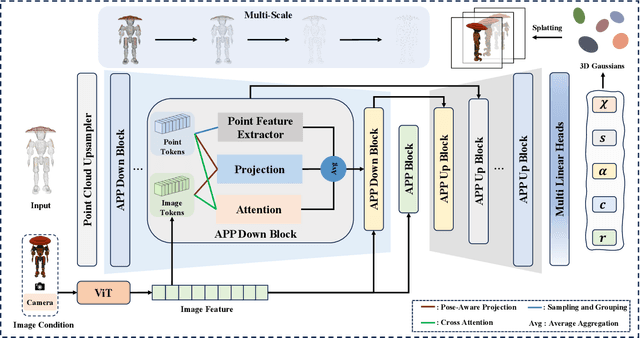
Recently, image-to-3D approaches have significantly advanced the generation quality and speed of 3D assets based on large reconstruction models, particularly 3D Gaussian reconstruction models. Existing large 3D Gaussian models directly map 2D image to 3D Gaussian parameters, while regressing 2D image to 3D Gaussian representations is challenging without 3D priors. In this paper, we propose a large Point-to-Gaussian model, that inputs the initial point cloud produced from large 3D diffusion model conditional on 2D image to generate the Gaussian parameters, for image-to-3D generation. The point cloud provides initial 3D geometry prior for Gaussian generation, thus significantly facilitating image-to-3D Generation. Moreover, we present the \textbf{A}ttention mechanism, \textbf{P}rojection mechanism, and \textbf{P}oint feature extractor, dubbed as \textbf{APP} block, for fusing the image features with point cloud features. The qualitative and quantitative experiments extensively demonstrate the effectiveness of the proposed approach on GSO and Objaverse datasets, and show the proposed method achieves state-of-the-art performance.
Invertible Residual Rescaling Models
May 05, 2024



Invertible Rescaling Networks (IRNs) and their variants have witnessed remarkable achievements in various image processing tasks like image rescaling. However, we observe that IRNs with deeper networks are difficult to train, thus hindering the representational ability of IRNs. To address this issue, we propose Invertible Residual Rescaling Models (IRRM) for image rescaling by learning a bijection between a high-resolution image and its low-resolution counterpart with a specific distribution. Specifically, we propose IRRM to build a deep network, which contains several Residual Downscaling Modules (RDMs) with long skip connections. Each RDM consists of several Invertible Residual Blocks (IRBs) with short connections. In this way, RDM allows rich low-frequency information to be bypassed by skip connections and forces models to focus on extracting high-frequency information from the image. Extensive experiments show that our IRRM performs significantly better than other state-of-the-art methods with much fewer parameters and complexity. Particularly, our IRRM has respectively PSNR gains of at least 0.3 dB over HCFlow and IRN in the $\times 4$ rescaling while only using 60\% parameters and 50\% FLOPs. The code will be available at https://github.com/THU-Kingmin/IRRM.
Optimal $γ$ and $C$ for $ε$-Support Vector Regression with RBF Kernels
Jun 12, 2015



The objective of this study is to investigate the efficient determination of $C$ and $\gamma$ for Support Vector Regression with RBF or mahalanobis kernel based on numerical and statistician considerations, which indicates the connection between $C$ and kernels and demonstrates that the deviation of geometric distance of neighbour observation in mapped space effects the predict accuracy of $\epsilon$-SVR. We determinate the arrange of $\gamma$ & $C$ and propose our method to choose their best values.