 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Machine Unlearning for Vision-Language Models
May 26, 2026Vision-language models (VLMs) may memorize undesirable information from training data, motivating growing interest in machine unlearning. In this work, we present the first systematic survey and robustness analysis of VLM unlearning. We provide a comprehensive taxonomy and review of existing VLM unlearning methods, together with unified evaluations under multiple prompt settings. We then propose three attack paradigms to examine whether forgotten multimodal knowledge can be reactivated through contextual prompting or downstream retraining. Extensive experiments show that many existing methods remain vulnerable under these attacks, indicating that current approaches often hide rather than fully remove target knowledge. Our study provides new insights into the robustness and limitations of current VLM unlearning methods and highlights the need for more reliable multimodal unlearning strategies. Code is available at https://github.com/XMUDeepLIT/VLM-UnL-Attack.
Curriculum-style Data Augmentation for LLM-based Metaphor Detection
Dec 04, 2024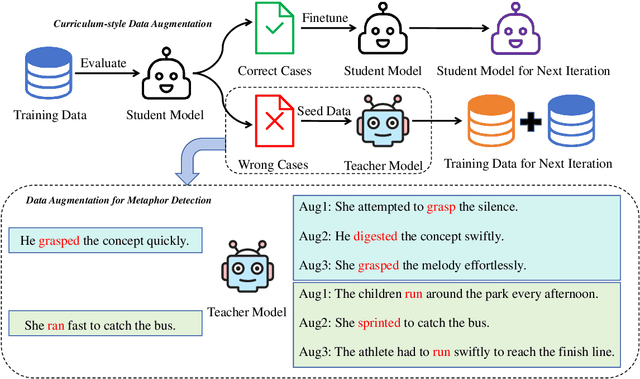

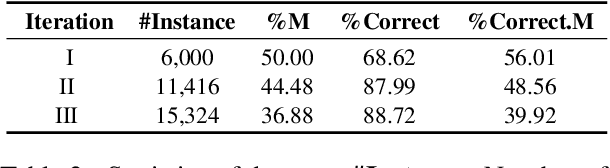
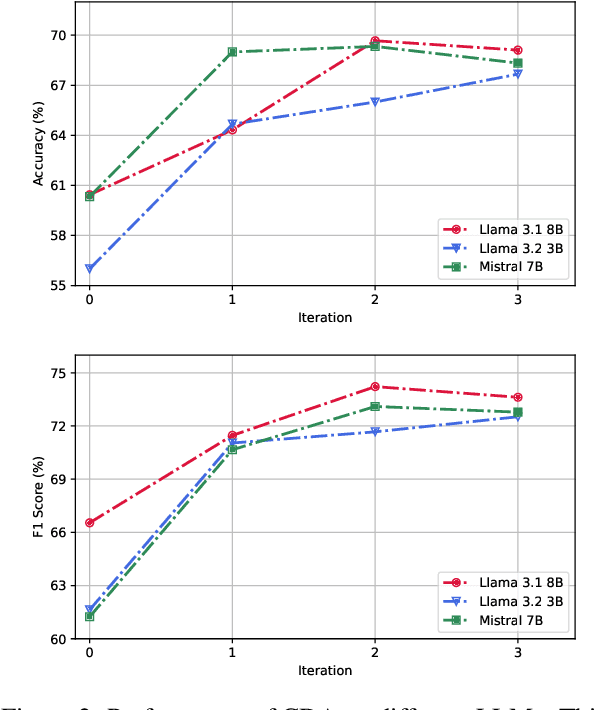
Recently, utilizing large language models (LLMs) for metaphor detection has achieved promising results. However, these methods heavily rely on the capabilities of closed-source LLMs, which come with relatively high inference costs and latency. To address this, we propose a method for metaphor detection by fine-tuning open-source LLMs, effectively reducing inference costs and latency with a single inference step. Furthermore, metaphor detection suffers from a severe data scarcity problem, which hinders effective fine-tuning of LLMs. To tackle this, we introduce Curriculum-style Data Augmentation (CDA). Specifically, before fine-tuning, we evaluate the training data to identify correctly predicted instances for fine-tuning, while incorrectly predicted instances are used as seed data for data augmentation. This approach enables the model to quickly learn simpler knowledge and progressively acquire more complex knowledge, thereby improving performance incrementally. Experimental results demonstrate that our method achieves state-of-the-art performance across all baselines. Additionally, we provide detailed ablation studies to validate the effectiveness of CDA.
Not All Languages are Equal: Insights into Multilingual Retrieval-Augmented Generation
Oct 29, 2024



RALMs (Retrieval-Augmented Language Models) broaden their knowledge scope by incorporating external textual resources. However, the multilingual nature of global knowledge necessitates RALMs to handle diverse languages, a topic that has received limited research focus. In this work, we propose \textit{Futurepedia}, a carefully crafted benchmark containing parallel texts across eight representative languages. We evaluate six multilingual RALMs using our benchmark to explore the challenges of multilingual RALMs. Experimental results reveal linguistic inequalities: 1) high-resource languages stand out in Monolingual Knowledge Extraction; 2) Indo-European languages lead RALMs to provide answers directly from documents, alleviating the challenge of expressing answers across languages; 3) English benefits from RALMs' selection bias and speaks louder in multilingual knowledge selection. Based on these findings, we offer advice for improving multilingual Retrieval Augmented Generation. For monolingual knowledge extraction, careful attention must be paid to cascading errors from translating low-resource languages into high-resource ones. In cross-lingual knowledge transfer, encouraging RALMs to provide answers within documents in different languages can improve transfer performance. For multilingual knowledge selection, incorporating more non-English documents and repositioning English documents can help mitigate RALMs' selection bias. Through comprehensive experiments, we underscore the complexities inherent in multilingual RALMs and offer valuable insights for future research.
Enhancing Metaphor Detection through Soft Labels and Target Word Prediction
Apr 09, 2024



Metaphors play a significant role in our everyday communication, yet detecting them presents a challenge. Traditional methods often struggle with improper application of language rules and a tendency to overlook data sparsity. To address these issues, we integrate knowledge distillation and prompt learning into metaphor detection. Our approach revolves around a tailored prompt learning framework specifically designed for metaphor detection. By strategically masking target words and providing relevant prompt data, we guide the model to accurately predict the contextual meanings of these words. This approach not only mitigates confusion stemming from the literal meanings of the words but also ensures effective application of language rules for metaphor detection. Furthermore, we've introduced a teacher model to generate valuable soft labels. These soft labels provide a similar effect to label smoothing and help prevent the model from becoming over confident and effectively addresses the challenge of data sparsity. Experimental results demonstrate that our model has achieved state-of-the-art performance, as evidenced by its remarkable results across various datasets.