 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum-style Data Augmentation for LLM-based Metaphor Detection
Paper and Code
Dec 04, 2024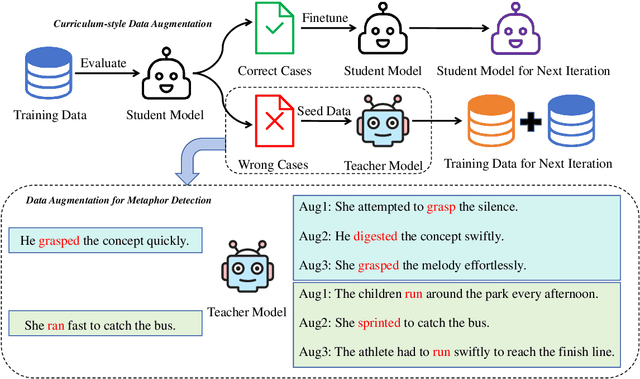

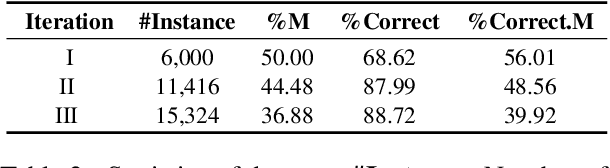
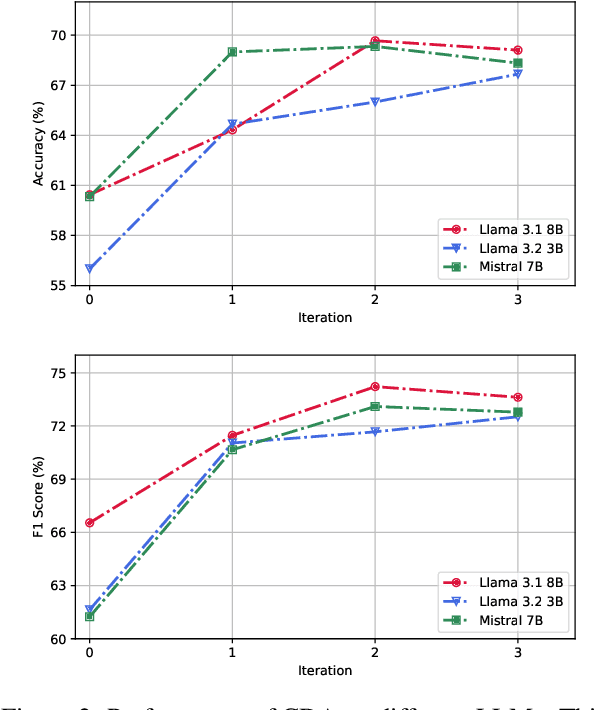
Recently, utilizing large language models (LLMs) for metaphor detection has achieved promising results. However, these methods heavily rely on the capabilities of closed-source LLMs, which come with relatively high inference costs and latency. To address this, we propose a method for metaphor detection by fine-tuning open-source LLMs, effectively reducing inference costs and latency with a single inference step. Furthermore, metaphor detection suffers from a severe data scarcity problem, which hinders effective fine-tuning of LLMs. To tackle this, we introduce Curriculum-style Data Augmentation (CDA). Specifically, before fine-tuning, we evaluate the training data to identify correctly predicted instances for fine-tuning, while incorrectly predicted instances are used as seed data for data augmentation. This approach enables the model to quickly learn simpler knowledge and progressively acquire more complex knowledge, thereby improving performance incrementally. Experimental results demonstrate that our method achieves state-of-the-art performance across all baselines. Additionally, we provide detailed ablation studies to validate the effectiveness of CDA.