 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Human-Object Interaction Detection
Aug 20, 2024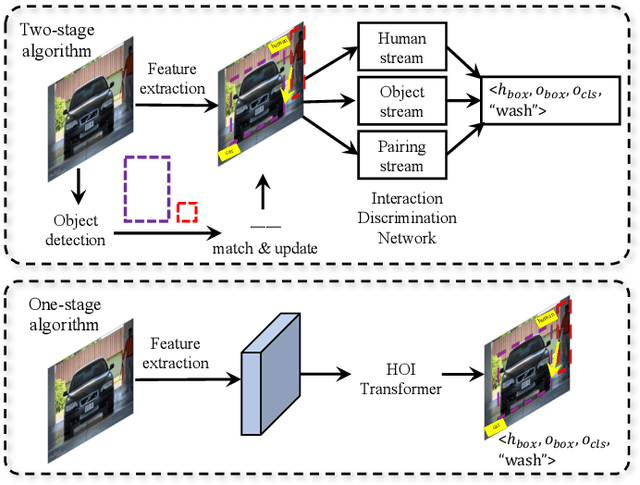
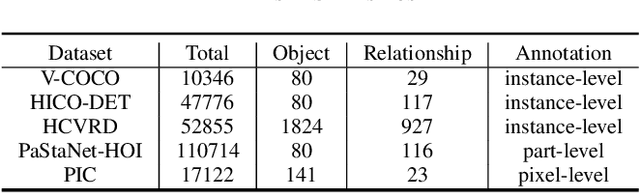
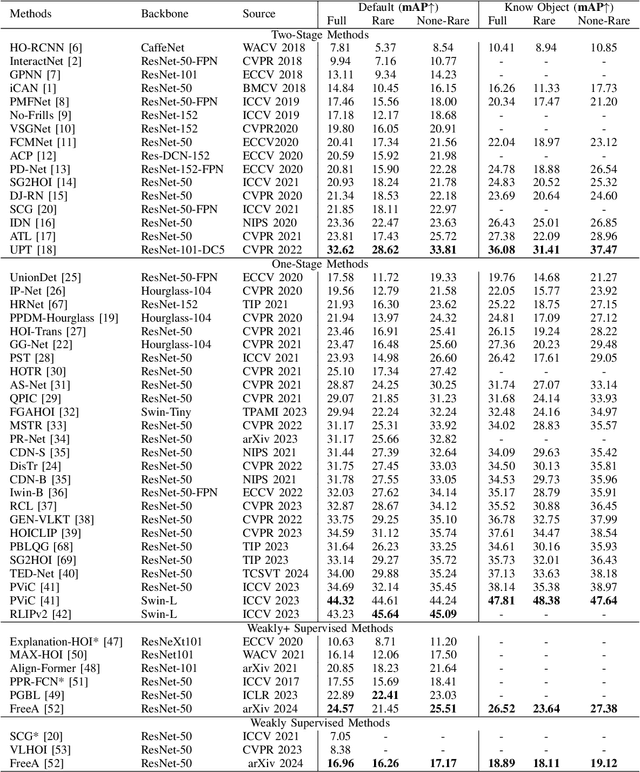
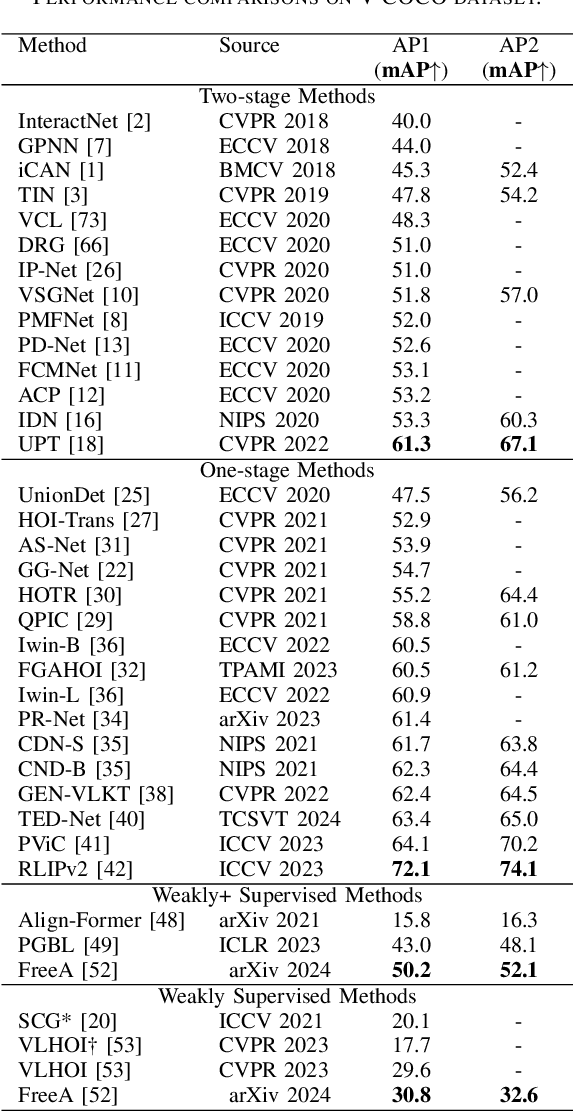
Human-object interaction (HOI) detection plays a key role in high-level visual understanding, facilitating a deep comprehension of human activities. Specifically, HOI detection aims to locate the humans and objects involved in interactions within images or videos and classify the specific interactions between them. The success of this task is influenced by several key factors, including the accurate localization of human and object instances, as well as the correct classification of object categories and interaction relationships. This paper systematically summarizes and discusses the recent work in image-based HOI detection. First, the mainstream datasets involved in HOI relationship detection are introduced. Furthermore, starting with two-stage methods and end-to-end one-stage detection approaches, this paper comprehensively discusses the current developments in image-based HOI detection, analyzing the strengths and weaknesses of these two methods. Additionally, the advancements of zero-shot learning, weakly supervised learning, and the application of large-scale language models in HOI detection are discussed. Finally, the current challenges in HOI detection are outlined, and potential research directions and future trends are explored.
Towards Zero-shot Human-Object Interaction Detection via Vision-Language Integration
Mar 12, 2024



Human-object interaction (HOI) detection aims to locate human-object pairs and identify their interaction categories in images. Most existing methods primarily focus on supervised learning, which relies on extensive manual HOI annotations. In this paper, we propose a novel framework, termed Knowledge Integration to HOI (KI2HOI), that effectively integrates the knowledge of visual-language model to improve zero-shot HOI detection. Specifically, the verb feature learning module is designed based on visual semantics, by employing the verb extraction decoder to convert corresponding verb queries into interaction-specific category representations. We develop an effective additive self-attention mechanism to generate more comprehensive visual representations. Moreover, the innovative interaction representation decoder effectively extracts informative regions by integrating spatial and visual feature information through a cross-attention mechanism. To deal with zero-shot learning in low-data, we leverage a priori knowledge from the CLIP text encoder to initialize the linear classifier for enhanced interaction understanding. Extensive experiments conducted on the mainstream HICO-DET and V-COCO datasets demonstrate that our model outperforms the previous methods in various zero-shot and full-supervised settings.
PointCore: Efficient Unsupervised Point Cloud Anomaly Detector Using Local-Global Features
Mar 04, 2024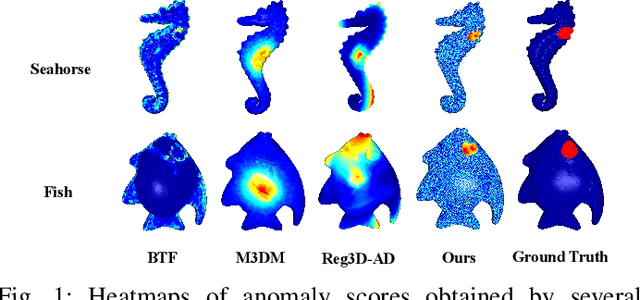
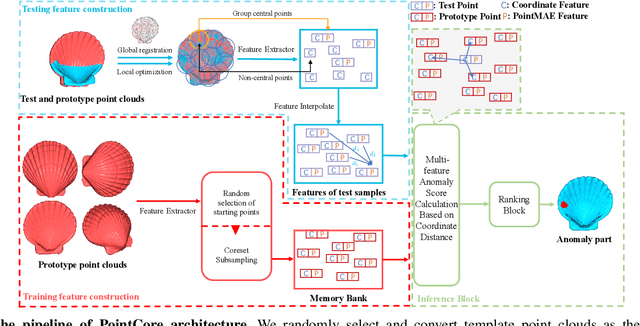
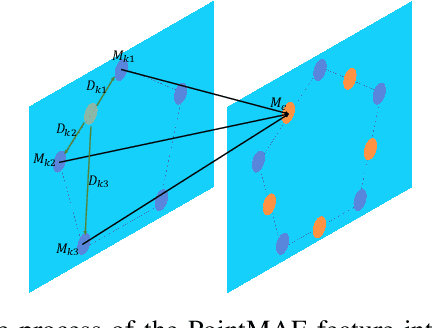
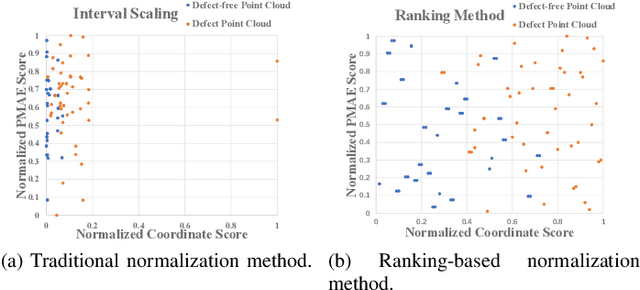
Three-dimensional point cloud anomaly detection that aims to detect anomaly data points from a training set serves as the foundation for a variety of applications, including industrial inspection and autonomous driving. However, existing point cloud anomaly detection methods often incorporate multiple feature memory banks to fully preserve local and global representations, which comes at the high cost of computational complexity and mismatches between features. To address that, we propose an unsupervised point cloud anomaly detection framework based on joint local-global features, termed PointCore. To be specific, PointCore only requires a single memory bank to store local (coordinate) and global (PointMAE) representations and different priorities are assigned to these local-global features, thereby reducing the computational cost and mismatching disturbance in inference. Furthermore, to robust against the outliers, a normalization ranking method is introduced to not only adjust values of different scales to a notionally common scale, but also transform densely-distributed data into a uniform distribution. Extensive experiments on Real3D-AD dataset demonstrate that PointCore achieves competitive inference time and the best performance in both detection and localization as compared to the state-of-the-art Reg3D-AD approach and several competitors.