 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphTOP: Graph Topology-Oriented Prompting for Graph Neural Networks
Oct 25, 2025Graph Neural Networks (GNNs) have revolutionized the field of graph learning by learning expressive graph representations from massive graph data. As a common pattern to train powerful GNNs, the "pre-training, adaptation" scheme first pre-trains GNNs over unlabeled graph data and subsequently adapts them to specific downstream tasks. In the adaptation phase, graph prompting is an effective strategy that modifies input graph data with learnable prompts while keeping pre-trained GNN models frozen. Typically, existing graph prompting studies mainly focus on *feature-oriented* methods that apply graph prompts to node features or hidden representations. However, these studies often achieve suboptimal performance, as they consistently overlook the potential of *topology-oriented* prompting, which adapts pre-trained GNNs by modifying the graph topology. In this study, we conduct a pioneering investigation of graph prompting in terms of graph topology. We propose the first **Graph** **T**opology-**O**riented **P**rompting (GraphTOP) framework to effectively adapt pre-trained GNN models for downstream tasks. More specifically, we reformulate topology-oriented prompting as an edge rewiring problem within multi-hop local subgraphs and relax it into the continuous probability space through reparameterization while ensuring tight relaxation and preserving graph sparsity. Extensive experiments on five graph datasets under four pre-training strategies demonstrate that our proposed GraphTOP outshines six baselines on multiple node classification datasets. Our code is available at https://github.com/xbfu/GraphTOP.
Graph Prompting for Graph Learning Models: Recent Advances and Future Directions
Jun 10, 2025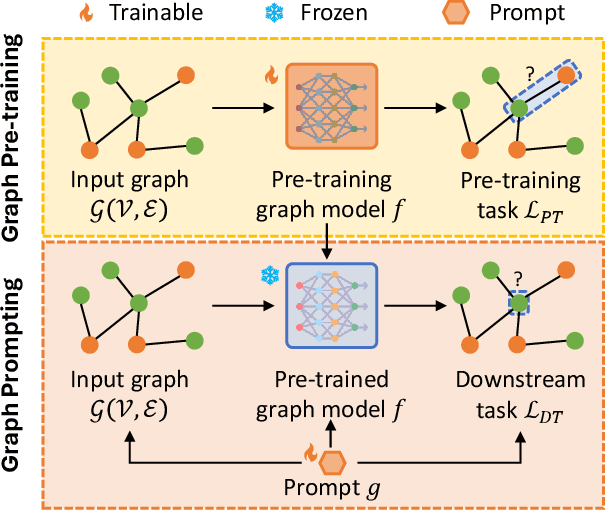
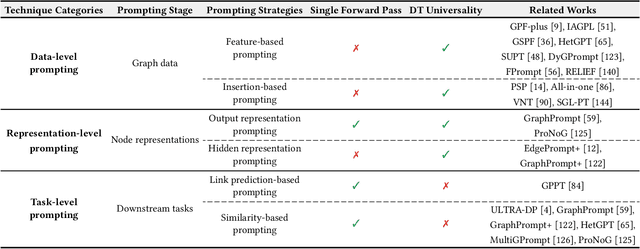
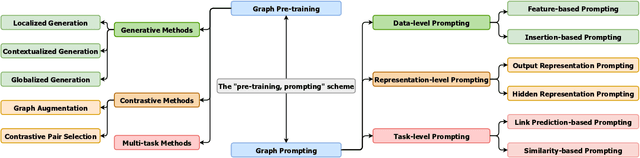
Graph learning models have demonstrated great prowess in learning expressive representations from large-scale graph data in a wide variety of real-world scenarios. As a prevalent strategy for training powerful graph learning models, the "pre-training, adaptation" scheme first pre-trains graph learning models on unlabeled graph data in a self-supervised manner and then adapts them to specific downstream tasks. During the adaptation phase, graph prompting emerges as a promising approach that learns trainable prompts while keeping the pre-trained graph learning models unchanged. In this paper, we present a systematic review of recent advancements in graph prompting. First, we introduce representative graph pre-training methods that serve as the foundation step of graph prompting. Next, we review mainstream techniques in graph prompting and elaborate on how they design learnable prompts for graph prompting. Furthermore, we summarize the real-world applications of graph prompting from different domains. Finally, we discuss several open challenges in existing studies with promising future directions in this field.
Graph Foundation Models: A Comprehensive Survey
May 21, 2025Graph-structured data pervades domains such as social networks, biological systems, knowledge graphs, and recommender systems. While foundation models have transformed natural language processing, vision, and multimodal learning through large-scale pretraining and generalization, extending these capabilities to graphs -- characterized by non-Euclidean structures and complex relational semantics -- poses unique challenges and opens new opportunities. To this end, Graph Foundation Models (GFMs) aim to bring scalable, general-purpose intelligence to structured data, enabling broad transfer across graph-centric tasks and domains. This survey provides a comprehensive overview of GFMs, unifying diverse efforts under a modular framework comprising three key components: backbone architectures, pretraining strategies, and adaptation mechanisms. We categorize GFMs by their generalization scope -- universal, task-specific, and domain-specific -- and review representative methods, key innovations, and theoretical insights within each category. Beyond methodology, we examine theoretical foundations including transferability and emergent capabilities, and highlight key challenges such as structural alignment, heterogeneity, scalability, and evaluation. Positioned at the intersection of graph learning and general-purpose AI, GFMs are poised to become foundational infrastructure for open-ended reasoning over structured data. This survey consolidates current progress and outlines future directions to guide research in this rapidly evolving field. Resources are available at https://github.com/Zehong-Wang/Awesome-Foundation-Models-on-Graphs.
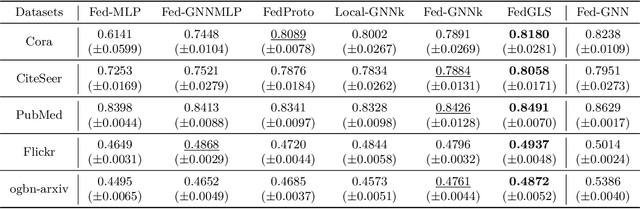
FedHERO: A Federated Learning Approach for Node Classification Task on Heterophilic Graphs
Apr 29, 2025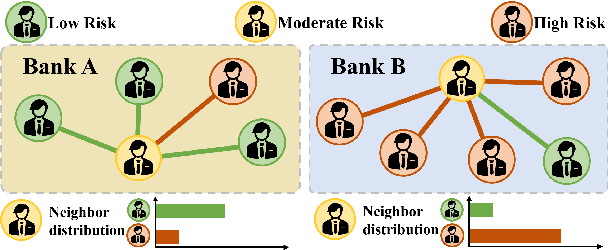

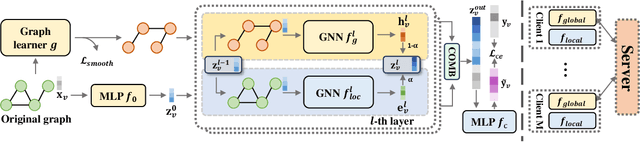
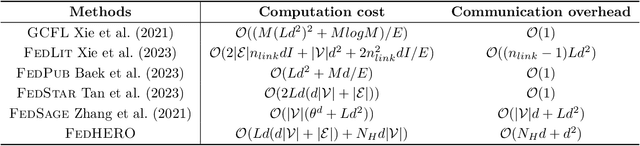
Federated Graph Learning (FGL) empowers clients to collaboratively train Graph neural networks (GNNs) in a distributed manner while preserving data privacy. However, FGL methods usually require that the graph data owned by all clients is homophilic to ensure similar neighbor distribution patterns of nodes. Such an assumption ensures that the learned knowledge is consistent across the local models from all clients. Therefore, these local models can be properly aggregated as a global model without undermining the overall performance. Nevertheless, when the neighbor distribution patterns of nodes vary across different clients (e.g., when clients hold graphs with different levels of heterophily), their local models may gain different and even conflict knowledge from their node-level predictive tasks. Consequently, aggregating these local models usually leads to catastrophic performance deterioration on the global model. To address this challenge, we propose FedHERO, an FGL framework designed to harness and share insights from heterophilic graphs effectively. At the heart of FedHERO is a dual-channel GNN equipped with a structure learner, engineered to discern the structural knowledge encoded in the local graphs. With this specialized component, FedHERO enables the local model for each client to identify and learn patterns that are universally applicable across graphs with different patterns of node neighbor distributions. FedHERO not only enhances the performance of individual client models by leveraging both local and shared structural insights but also sets a new precedent in this field to effectively handle graph data with various node neighbor distribution patterns. We conduct extensive experiments to validate the superior performance of FedHERO against existing alternatives.
A Survey of Scaling in Large Language Model Reasoning
Apr 02, 2025The rapid advancements in large Language models (LLMs) have significantly enhanced their reasoning capabilities, driven by various strategies such as multi-agent collaboration. However, unlike the well-established performance improvements achieved through scaling data and model size, the scaling of reasoning in LLMs is more complex and can even negatively impact reasoning performance, introducing new challenges in model alignment and robustness. In this survey, we provide a comprehensive examination of scaling in LLM reasoning, categorizing it into multiple dimensions and analyzing how and to what extent different scaling strategies contribute to improving reasoning capabilities. We begin by exploring scaling in input size, which enables LLMs to process and utilize more extensive context for improved reasoning. Next, we analyze scaling in reasoning steps that improves multi-step inference and logical consistency. We then examine scaling in reasoning rounds, where iterative interactions refine reasoning outcomes. Furthermore, we discuss scaling in training-enabled reasoning, focusing on optimization through iterative model improvement. Finally, we review applications of scaling across domains and outline future directions for further advancing LLM reasoning. By synthesizing these diverse perspectives, this survey aims to provide insights into how scaling strategies fundamentally enhance the reasoning capabilities of LLMs and further guide the development of next-generation AI systems.
Virtual Nodes Can Help: Tackling Distribution Shifts in Federated Graph Learning
Dec 26, 2024



Federated Graph Learning (FGL) enables multiple clients to jointly train powerful graph learning models, e.g., Graph Neural Networks (GNNs), without sharing their local graph data for graph-related downstream tasks, such as graph property prediction. In the real world, however, the graph data can suffer from significant distribution shifts across clients as the clients may collect their graph data for different purposes. In particular, graph properties are usually associated with invariant label-relevant substructures (i.e., subgraphs) across clients, while label-irrelevant substructures can appear in a client-specific manner. The issue of distribution shifts of graph data hinders the efficiency of GNN training and leads to serious performance degradation in FGL. To tackle the aforementioned issue, we propose a novel FGL framework entitled FedVN that eliminates distribution shifts through client-specific graph augmentation strategies with multiple learnable Virtual Nodes (VNs). Specifically, FedVN lets the clients jointly learn a set of shared VNs while training a global GNN model. To eliminate distribution shifts, each client trains a personalized edge generator that determines how the VNs connect local graphs in a client-specific manner. Furthermore, we provide theoretical analyses indicating that FedVN can eliminate distribution shifts of graph data across clients. Comprehensive experiments on four datasets under five settings demonstrate the superiority of our proposed FedVN over nine baselines.
Federated Graph Learning with Graphless Clients
Nov 13, 2024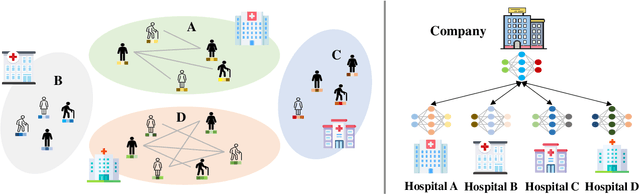
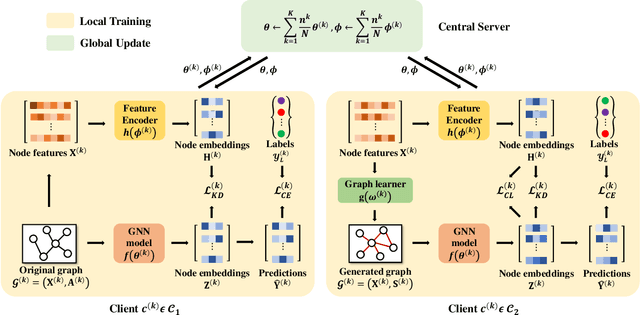
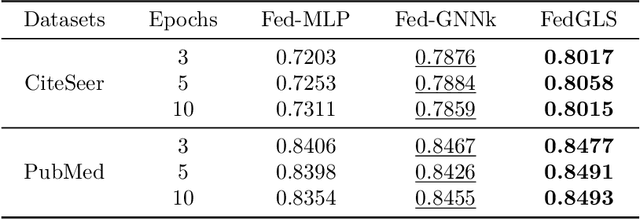
Federated Graph Learning (FGL) is tasked with training machine learning models, such as Graph Neural Networks (GNNs), for multiple clients, each with its own graph data. Existing methods usually assume that each client has both node features and graph structure of its graph data. In real-world scenarios, however, there exist federated systems where only a part of the clients have such data while other clients (i.e. graphless clients) may only have node features. This naturally leads to a novel problem in FGL: how to jointly train a model over distributed graph data with graphless clients? In this paper, we propose a novel framework FedGLS to tackle the problem in FGL with graphless clients. In FedGLS, we devise a local graph learner on each graphless client which learns the local graph structure with the structure knowledge transferred from other clients. To enable structure knowledge transfer, we design a GNN model and a feature encoder on each client. During local training, the feature encoder retains the local graph structure knowledge together with the GNN model via knowledge distillation, and the structure knowledge is transferred among clients in global update. Our extensive experiments demonstrate the superiority of the proposed FedGLS over five baselines.
Federated Graph Learning with Structure Proxy Alignment
Aug 18, 2024



Federated Graph Learning (FGL) aims to learn graph learning models over graph data distributed in multiple data owners, which has been applied in various applications such as social recommendation and financial fraud detection. Inherited from generic Federated Learning (FL), FGL similarly has the data heterogeneity issue where the label distribution may vary significantly for distributed graph data across clients. For instance, a client can have the majority of nodes from a class, while another client may have only a few nodes from the same class. This issue results in divergent local objectives and impairs FGL convergence for node-level tasks, especially for node classification. Moreover, FGL also encounters a unique challenge for the node classification task: the nodes from a minority class in a client are more likely to have biased neighboring information, which prevents FGL from learning expressive node embeddings with Graph Neural Networks (GNNs). To grapple with the challenge, we propose FedSpray, a novel FGL framework that learns local class-wise structure proxies in the latent space and aligns them to obtain global structure proxies in the server. Our goal is to obtain the aligned structure proxies that can serve as reliable, unbiased neighboring information for node classification. To achieve this, FedSpray trains a global feature-structure encoder and generates unbiased soft targets with structure proxies to regularize local training of GNN models in a personalized way. We conduct extensive experiments over four datasets, and experiment results validate the superiority of FedSpray compared with other baselines. Our code is available at https://github.com/xbfu/FedSpray.
Safety in Graph Machine Learning: Threats and Safeguards
May 17, 2024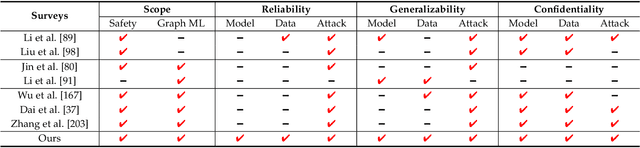
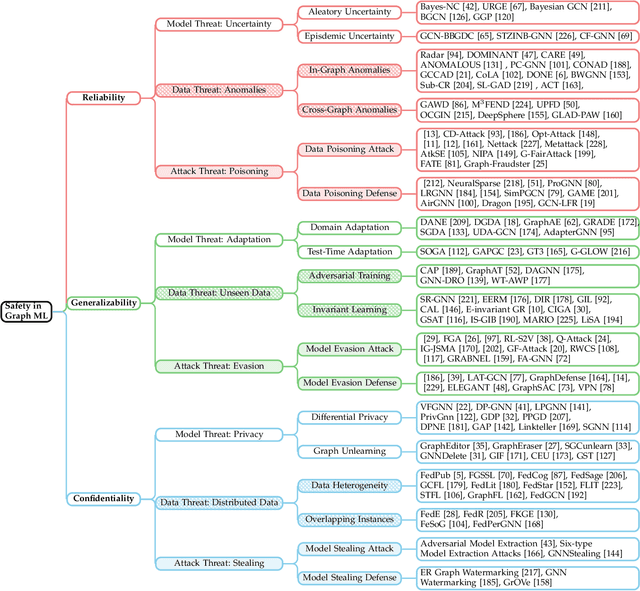

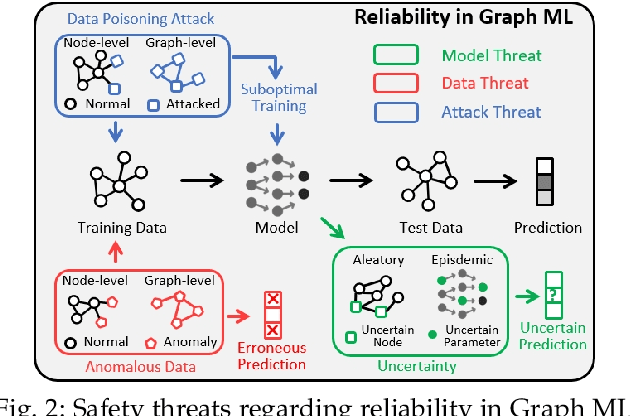
Graph Machine Learning (Graph ML) has witnessed substantial advancements in recent years. With their remarkable ability to process graph-structured data, Graph ML techniques have been extensively utilized across diverse applications, including critical domains like finance, healthcare, and transportation. Despite their societal benefits, recent research highlights significant safety concerns associated with the widespread use of Graph ML models. Lacking safety-focused designs, these models can produce unreliable predictions, demonstrate poor generalizability, and compromise data confidentiality. In high-stakes scenarios such as financial fraud detection, these vulnerabilities could jeopardize both individuals and society at large. Therefore, it is imperative to prioritize the development of safety-oriented Graph ML models to mitigate these risks and enhance public confidence in their applications. In this survey paper, we explore three critical aspects vital for enhancing safety in Graph ML: reliability, generalizability, and confidentiality. We categorize and analyze threats to each aspect under three headings: model threats, data threats, and attack threats. This novel taxonomy guides our review of effective strategies to protect against these threats. Our systematic review lays a groundwork for future research aimed at developing practical, safety-centered Graph ML models. Furthermore, we highlight the significance of safe Graph ML practices and suggest promising avenues for further investigation in this crucial area.
Federated Few-shot Learning
Jul 02, 2023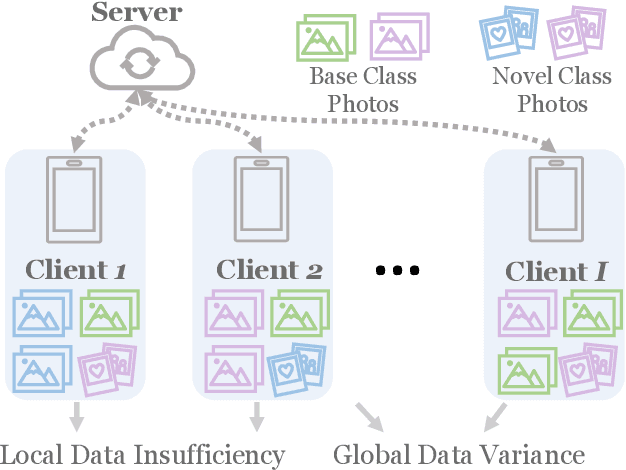
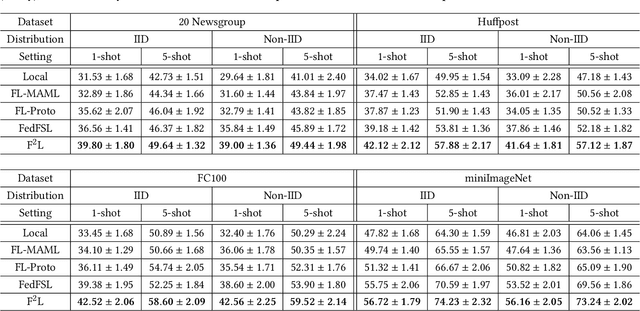
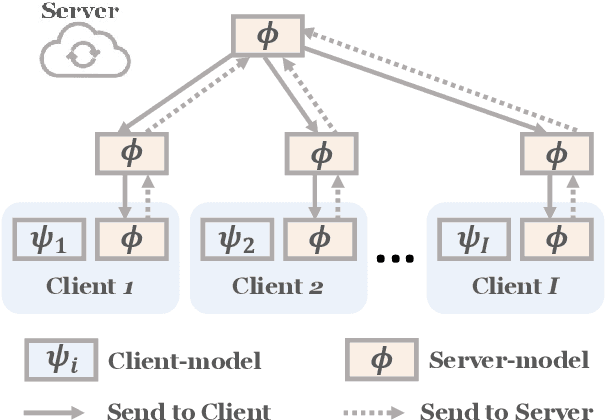

Federated Learning (FL) enables multiple clients to collaboratively learn a machine learning model without exchanging their own local data. In this way, the server can exploit the computational power of all clients and train the model on a larger set of data samples among all clients. Although such a mechanism is proven to be effective in various fields, existing works generally assume that each client preserves sufficient data for training. In practice, however, certain clients may only contain a limited number of samples (i.e., few-shot samples). For example, the available photo data taken by a specific user with a new mobile device is relatively rare. In this scenario, existing FL efforts typically encounter a significant performance drop on these clients. Therefore, it is urgent to develop a few-shot model that can generalize to clients with limited data under the FL scenario. In this paper, we refer to this novel problem as federated few-shot learning. Nevertheless, the problem remains challenging due to two major reasons: the global data variance among clients (i.e., the difference in data distributions among clients) and the local data insufficiency in each client (i.e., the lack of adequate local data for training). To overcome these two challenges, we propose a novel federated few-shot learning framework with two separately updated models and dedicated training strategies to reduce the adverse impact of global data variance and local data insufficiency. Extensive experiments on four prevalent datasets that cover news articles and images validate the effectiveness of our framework compared with the state-of-the-art baselines. Our code is provided at https://github.com/SongW-SW/F2L.