 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Circuit-Based Knowledge Editing in Large Language Models
Apr 07, 2026Deploying Large Language Models (LLMs) in real-world dynamic environments raises the challenge of updating their pre-trained knowledge. While existing knowledge editing methods can reliably patch isolated facts, they frequently suffer from a "Reasoning Gap", where the model recalls the edited fact but fails to utilize it in multi-step reasoning chains. To bridge this gap, we introduce MCircKE (\underline{M}echanistic \underline{Circ}uit-based \underline{K}nowledge \underline{E}diting), a novel framework that enables a precise "map-and-adapt" editing procedure. MCircKE first identifies the causal circuits responsible for a specific reasoning task, capturing both the storage of the fact and the routing of its logical consequences. It then surgically update parameters exclusively within this mapped circuit. Extensive experiments on the MQuAKE-3K benchmark demonstrate the effectiveness of the proposed method for multi-hop reasoning in knowledge editing.
Wired for Overconfidence: A Mechanistic Perspective on Inflated Verbalized Confidence in LLMs
Apr 01, 2026Large language models are often not just wrong, but \emph{confidently wrong}: when they produce factually incorrect answers, they tend to verbalize overly high confidence rather than signal uncertainty. Such verbalized overconfidence can mislead users and weaken confidence scores as a reliable uncertainty signal, yet its internal mechanisms remain poorly understood. We present a circuit-level mechanistic analysis of this inflated verbalized confidence in LLMs, organized around three axes: capturing verbalized confidence as a differentiable internal signal, identifying the circuits that causally inflate it, and leveraging these insights for targeted inference-time recalibration. Across two instruction-tuned LLMs on three datasets, we find that a compact set of MLP blocks and attention heads, concentrated in middle-to-late layers, consistently writes the confidence-inflation signal at the final token position. We further show that targeted inference-time interventions on these circuits substantially improve calibration. Together, our results suggest that verbalized overconfidence in LLMs is driven by identifiable internal circuits and can be mitigated through targeted intervention.
IAPO: Information-Aware Policy Optimization for Token-Efficient Reasoning
Feb 22, 2026Large language models increasingly rely on long chains of thought to improve accuracy, yet such gains come with substantial inference-time costs. We revisit token-efficient post-training and argue that existing sequence-level reward-shaping methods offer limited control over how reasoning effort is allocated across tokens. To bridge the gap, we propose IAPO, an information-theoretic post-training framework that assigns token-wise advantages based on each token's conditional mutual information (MI) with the final answer. This yields an explicit, principled mechanism for identifying informative reasoning steps and suppressing low-utility exploration. We provide a theoretical analysis showing that our IAPO can induce monotonic reductions in reasoning verbosity without harming correctness. Empirically, IAPO consistently improves reasoning accuracy while reducing reasoning length by up to 36%, outperforming existing token-efficient RL methods across various reasoning datasets. Extensive empirical evaluations demonstrate that information-aware advantage shaping is a powerful and general direction for token-efficient post-training. The code is available at https://github.com/YinhanHe123/IAPO.
Saliency-Aware Multi-Route Thinking: Revisiting Vision-Language Reasoning
Feb 18, 2026Vision-language models (VLMs) aim to reason by jointly leveraging visual and textual modalities. While allocating additional inference-time computation has proven effective for large language models (LLMs), achieving similar scaling in VLMs remains challenging. A key obstacle is that visual inputs are typically provided only once at the start of generation, while textual reasoning (e.g., early visual summaries) is generated autoregressively, causing reasoning to become increasingly text-dominated and allowing early visual grounding errors to accumulate. Moreover, vanilla guidance for visual grounding during inference is often coarse and noisy, making it difficult to steer reasoning over long texts. To address these challenges, we propose \emph{Saliency-Aware Principle} (SAP) selection. SAP operates on high-level reasoning principles rather than token-level trajectories, which enable stable control over discrete generation under noisy feedback while allowing later reasoning steps to re-consult visual evidence when renewed grounding is required. In addition, SAP supports multi-route inference, enabling parallel exploration of diverse reasoning behaviors. SAP is model-agnostic and data-free, requiring no additional training. Empirical results show that SAP achieves competitive performance, especially in reducing object hallucination, under comparable token-generation budgets while yielding more stable reasoning and lower response latency than CoT-style long sequential reasoning.
PhysicsAgentABM: Physics-Guided Generative Agent-Based Modeling
Feb 05, 2026Large language model (LLM)-based multi-agent systems enable expressive agent reasoning but are expensive to scale and poorly calibrated for timestep-aligned state-transition simulation, while classical agent-based models (ABMs) offer interpretability but struggle to integrate rich individual-level signals and non-stationary behaviors. We propose PhysicsAgentABM, which shifts inference to behaviorally coherent agent clusters: state-specialized symbolic agents encode mechanistic transition priors, a multimodal neural transition model captures temporal and interaction dynamics, and uncertainty-aware epistemic fusion yields calibrated cluster-level transition distributions. Individual agents then stochastically realize transitions under local constraints, decoupling population inference from entity-level variability. We further introduce ANCHOR, an LLM agent-driven clustering strategy based on cross-contextual behavioral responses and a novel contrastive loss, reducing LLM calls by up to 6-8 times. Experiments across public health, finance, and social sciences show consistent gains in event-time accuracy and calibration over mechanistic, neural, and LLM baselines. By re-architecting generative ABM around population-level inference with uncertainty-aware neuro-symbolic fusion, PhysicsAgentABM establishes a new paradigm for scalable and calibrated simulation with LLMs.
MolEdit: Knowledge Editing for Multimodal Molecule Language Models
Nov 16, 2025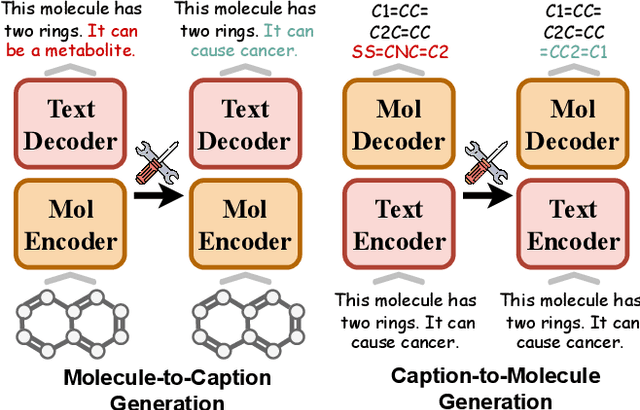
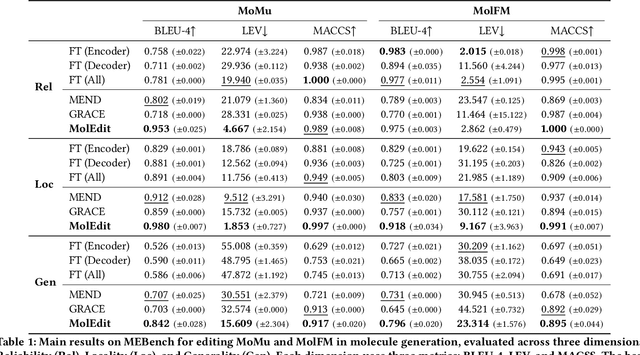

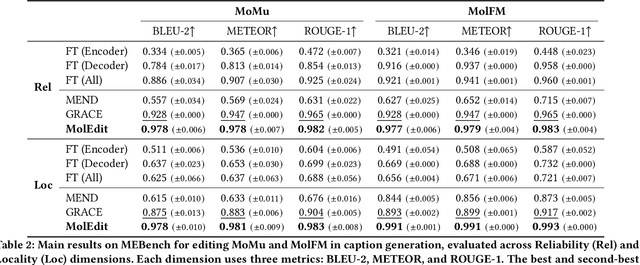
Understanding and continuously refining multimodal molecular knowledge is crucial for advancing biomedicine, chemistry, and materials science. Molecule language models (MoLMs) have become powerful tools in these domains, integrating structural representations (e.g., SMILES strings, molecular graphs) with rich contextual descriptions (e.g., physicochemical properties). However, MoLMs can encode and propagate inaccuracies due to outdated web-mined training corpora or malicious manipulation, jeopardizing downstream discovery pipelines. While knowledge editing has been explored for general-domain AI, its application to MoLMs remains uncharted, presenting unique challenges due to the multifaceted and interdependent nature of molecular knowledge. In this paper, we take the first step toward MoLM editing for two critical tasks: molecule-to-caption generation and caption-to-molecule generation. To address molecule-specific challenges, we propose MolEdit, a powerful framework that enables targeted modifications while preserving unrelated molecular knowledge. MolEdit combines a Multi-Expert Knowledge Adapter that routes edits to specialized experts for different molecular facets with an Expertise-Aware Editing Switcher that activates the adapters only when input closely matches the stored edits across all expertise, minimizing interference with unrelated knowledge. To systematically evaluate editing performance, we introduce MEBench, a comprehensive benchmark assessing multiple dimensions, including Reliability (accuracy of the editing), Locality (preservation of irrelevant knowledge), and Generality (robustness to reformed queries). Across extensive experiments on two popular MoLM backbones, MolEdit delivers up to 18.8% higher Reliability and 12.0% better Locality than baselines while maintaining efficiency. The code is available at: https://github.com/LzyFischer/MolEdit.
Virtual Nodes Can Help: Tackling Distribution Shifts in Federated Graph Learning
Dec 26, 2024



Federated Graph Learning (FGL) enables multiple clients to jointly train powerful graph learning models, e.g., Graph Neural Networks (GNNs), without sharing their local graph data for graph-related downstream tasks, such as graph property prediction. In the real world, however, the graph data can suffer from significant distribution shifts across clients as the clients may collect their graph data for different purposes. In particular, graph properties are usually associated with invariant label-relevant substructures (i.e., subgraphs) across clients, while label-irrelevant substructures can appear in a client-specific manner. The issue of distribution shifts of graph data hinders the efficiency of GNN training and leads to serious performance degradation in FGL. To tackle the aforementioned issue, we propose a novel FGL framework entitled FedVN that eliminates distribution shifts through client-specific graph augmentation strategies with multiple learnable Virtual Nodes (VNs). Specifically, FedVN lets the clients jointly learn a set of shared VNs while training a global GNN model. To eliminate distribution shifts, each client trains a personalized edge generator that determines how the VNs connect local graphs in a client-specific manner. Furthermore, we provide theoretical analyses indicating that FedVN can eliminate distribution shifts of graph data across clients. Comprehensive experiments on four datasets under five settings demonstrate the superiority of our proposed FedVN over nine baselines.
Graph Neural Networks Are More Than Filters: Revisiting and Benchmarking from A Spectral Perspective
Dec 10, 2024Graph Neural Networks (GNNs) have achieved remarkable success in various graph-based learning tasks. While their performance is often attributed to the powerful neighborhood aggregation mechanism, recent studies suggest that other components such as non-linear layers may also significantly affecting how GNNs process the input graph data in the spectral domain. Such evidence challenges the prevalent opinion that neighborhood aggregation mechanisms dominate the behavioral characteristics of GNNs in the spectral domain. To demystify such a conflict, this paper introduces a comprehensive benchmark to measure and evaluate GNNs' capability in capturing and leveraging the information encoded in different frequency components of the input graph data. Specifically, we first conduct an exploratory study demonstrating that GNNs can flexibly yield outputs with diverse frequency components even when certain frequencies are absent or filtered out from the input graph data. We then formulate a novel research problem of measuring and benchmarking the performance of GNNs from a spectral perspective. To take an initial step towards a comprehensive benchmark, we design an evaluation protocol supported by comprehensive theoretical analysis. Finally, we introduce a comprehensive benchmark on real-world datasets, revealing insights that challenge prevalent opinions from a spectral perspective. We believe that our findings will open new avenues for future advancements in this area. Our implementations can be found at: https://github.com/yushundong/Spectral-benchmark.
Global Graph Counterfactual Explanation: A Subgraph Mapping Approach
Oct 25, 2024



Graph Neural Networks (GNNs) have been widely deployed in various real-world applications. However, most GNNs are black-box models that lack explanations. One strategy to explain GNNs is through counterfactual explanation, which aims to find minimum perturbations on input graphs that change the GNN predictions. Existing works on GNN counterfactual explanations primarily concentrate on the local-level perspective (i.e., generating counterfactuals for each individual graph), which suffers from information overload and lacks insights into the broader cross-graph relationships. To address such issues, we propose GlobalGCE, a novel global-level graph counterfactual explanation method. GlobalGCE aims to identify a collection of subgraph mapping rules as counterfactual explanations for the target GNN. According to these rules, substituting certain significant subgraphs with their counterfactual subgraphs will change the GNN prediction to the desired class for most graphs (i.e., maximum coverage). Methodologically, we design a significant subgraph generator and a counterfactual subgraph autoencoder in our GlobalGCE, where the subgraphs and the rules can be effectively generated. Extensive experiments demonstrate the superiority of our GlobalGCE compared to existing baselines. Our code can be found at https://anonymous.4open.science/r/GlobalGCE-92E8.
Explaining Graph Neural Networks with Large Language Models: A Counterfactual Perspective for Molecular Property Prediction
Oct 19, 2024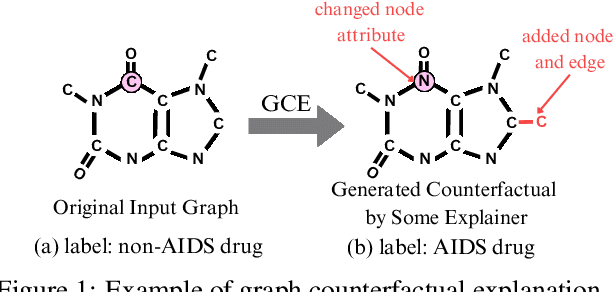



In recent years, Graph Neural Networks (GNNs) have become successful in molecular property prediction tasks such as toxicity analysis. However, due to the black-box nature of GNNs, their outputs can be concerning in high-stakes decision-making scenarios, e.g., drug discovery. Facing such an issue, Graph Counterfactual Explanation (GCE) has emerged as a promising approach to improve GNN transparency. However, current GCE methods usually fail to take domain-specific knowledge into consideration, which can result in outputs that are not easily comprehensible by humans. To address this challenge, we propose a novel GCE method, LLM-GCE, to unleash the power of large language models (LLMs) in explaining GNNs for molecular property prediction. Specifically, we utilize an autoencoder to generate the counterfactual graph topology from a set of counterfactual text pairs (CTPs) based on an input graph. Meanwhile, we also incorporate a CTP dynamic feedback module to mitigate LLM hallucination, which provides intermediate feedback derived from the generated counterfactuals as an attempt to give more faithful guidance. Extensive experiments demonstrate the superior performance of LLM-GCE. Our code is released on https://github.com/YinhanHe123/new\_LLM4GNNExplanation.