 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-CF: Knowledge Graph Completion with Context Filtering under the Guidance of Large Language Models
Jan 06, 2025



Large Language Models (LLMs) have shown impressive performance in various tasks, including knowledge graph completion (KGC). However, current studies mostly apply LLMs to classification tasks, like identifying missing triplets, rather than ranking-based tasks, where the model ranks candidate entities based on plausibility. This focus limits the practical use of LLMs in KGC, as real-world applications prioritize highly plausible triplets. Additionally, while graph paths can help infer the existence of missing triplets and improve completion accuracy, they often contain redundant information. To address these issues, we propose KG-CF, a framework tailored for ranking-based KGC tasks. KG-CF leverages LLMs' reasoning abilities to filter out irrelevant contexts, achieving superior results on real-world datasets. The code and datasets are available at \url{https://anonymous.4open.science/r/KG-CF}.
Explaining Graph Neural Networks with Large Language Models: A Counterfactual Perspective for Molecular Property Prediction
Oct 19, 2024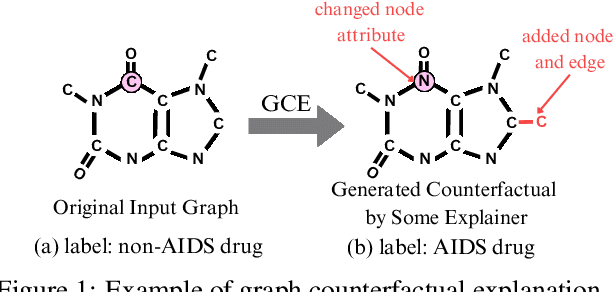



In recent years, Graph Neural Networks (GNNs) have become successful in molecular property prediction tasks such as toxicity analysis. However, due to the black-box nature of GNNs, their outputs can be concerning in high-stakes decision-making scenarios, e.g., drug discovery. Facing such an issue, Graph Counterfactual Explanation (GCE) has emerged as a promising approach to improve GNN transparency. However, current GCE methods usually fail to take domain-specific knowledge into consideration, which can result in outputs that are not easily comprehensible by humans. To address this challenge, we propose a novel GCE method, LLM-GCE, to unleash the power of large language models (LLMs) in explaining GNNs for molecular property prediction. Specifically, we utilize an autoencoder to generate the counterfactual graph topology from a set of counterfactual text pairs (CTPs) based on an input graph. Meanwhile, we also incorporate a CTP dynamic feedback module to mitigate LLM hallucination, which provides intermediate feedback derived from the generated counterfactuals as an attempt to give more faithful guidance. Extensive experiments demonstrate the superior performance of LLM-GCE. Our code is released on https://github.com/YinhanHe123/new\_LLM4GNNExplanation.
A Benchmark for Fairness-Aware Graph Learning
Jul 16, 2024Fairness-aware graph learning has gained increasing attention in recent years. Nevertheless, there lacks a comprehensive benchmark to evaluate and compare different fairness-aware graph learning methods, which blocks practitioners from choosing appropriate ones for broader real-world applications. In this paper, we present an extensive benchmark on ten representative fairness-aware graph learning methods. Specifically, we design a systematic evaluation protocol and conduct experiments on seven real-world datasets to evaluate these methods from multiple perspectives, including group fairness, individual fairness, the balance between different fairness criteria, and computational efficiency. Our in-depth analysis reveals key insights into the strengths and limitations of existing methods. Additionally, we provide practical guidance for applying fairness-aware graph learning methods in applications. To the best of our knowledge, this work serves as an initial step towards comprehensively understanding representative fairness-aware graph learning methods to facilitate future advancements in this area.
Knowledge Editing for Large Language Models: A Survey
Oct 26, 2023



Large language models (LLMs) have recently transformed both the academic and industrial landscapes due to their remarkable capacity to understand, analyze, and generate texts based on their vast knowledge and reasoning ability. Nevertheless, one major drawback of LLMs is their substantial computational cost for pre-training due to their unprecedented amounts of parameters. The disadvantage is exacerbated when new knowledge frequently needs to be introduced into the pre-trained model. Therefore, it is imperative to develop effective and efficient techniques to update pre-trained LLMs. Traditional methods encode new knowledge in pre-trained LLMs through direct fine-tuning. However, naively re-training LLMs can be computationally intensive and risks degenerating valuable pre-trained knowledge irrelevant to the update in the model. Recently, Knowledge-based Model Editing (KME) has attracted increasing attention, which aims to precisely modify the LLMs to incorporate specific knowledge, without negatively influencing other irrelevant knowledge. In this survey, we aim to provide a comprehensive and in-depth overview of recent advances in the field of KME. We first introduce a general formulation of KME to encompass different KME strategies. Afterward, we provide an innovative taxonomy of KME techniques based on how the new knowledge is introduced into pre-trained LLMs, and investigate existing KME strategies while analyzing key insights, advantages, and limitations of methods from each category. Moreover, representative metrics, datasets, and applications of KME are introduced accordingly. Finally, we provide an in-depth analysis regarding the practicality and remaining challenges of KME and suggest promising research directions for further advancement in this field.