 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASS: Mathematical Data Selection via Skill Graphs for Pretraining Large Language Models
Paper and Code
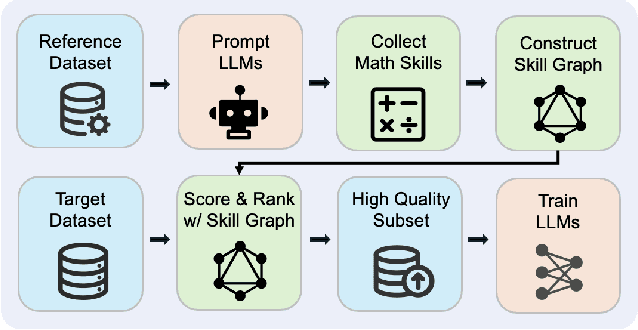

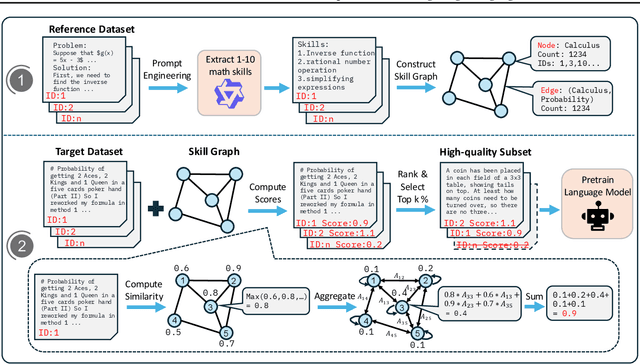

High-quality data plays a critical role in the pretraining and fine-tuning of large language models (LLMs), even determining their performance ceiling to some degree. Consequently, numerous data selection methods have been proposed to identify subsets of data that can effectively and efficiently enhance model performance. However, most of these methods focus on general data selection and tend to overlook the specific nuances of domain-related data. In this paper, we introduce MASS, a \textbf{MA}thematical data \textbf{S}election framework using the \textbf{S}kill graph for pretraining LLMs in the mathematical reasoning domain. By taking into account the unique characteristics of mathematics and reasoning, we construct a skill graph that captures the mathematical skills and their interrelations from a reference dataset. This skill graph guides us in assigning quality scores to the target dataset, enabling us to select the top-ranked subset which is further used to pretrain LLMs. Experimental results demonstrate the efficiency and effectiveness of MASS across different model sizes (1B and 7B) and pretraining datasets (web data and synthetic data). Specifically, in terms of efficiency, models trained on subsets selected by MASS can achieve similar performance to models trained on the original datasets, with a significant reduction in the number of trained tokens - ranging from 50\% to 70\% fewer tokens. In terms of effectiveness, when trained on the same amount of tokens, models trained on the data selected by MASS outperform those trained on the original datasets by 3.3\% to 5.9\%. These results underscore the potential of MASS to improve both the efficiency and effectiveness of pretraining LLMs.