 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-D3: A Solution to the Hidden Overfitting Problem of Deep Learning Models
Dec 15, 2025Deep learning for decoding EEG signals has gained traction, with many claims to state-of-the-art accuracy. However, despite the convincing benchmark performance, successful translation to real applications is limited. The frequent disconnect between performance on controlled BCI benchmarks and its lack of generalisation to practical settings indicates hidden overfitting problems. We introduce Disentangled Decoding Decomposition (D3), a weakly supervised method for training deep learning models across EEG datasets. By predicting the place in the respective trial sequence from which the input window was sampled, EEG-D3 separates latent components of brain activity, akin to non-linear ICA. We utilise a novel model architecture with fully independent sub-networks for strict interpretability. We outline a feature interpretation paradigm to contrast the component activation profiles on different datasets and inspect the associated temporal and spatial filters. The proposed method reliably separates latent components of brain activity on motor imagery data. Training downstream classifiers on an appropriate subset of these components prevents hidden overfitting caused by task-correlated artefacts, which severely affects end-to-end classifiers. We further exploit the linearly separable latent space for effective few-shot learning on sleep stage classification. The ability to distinguish genuine components of brain activity from spurious features results in models that avoid the hidden overfitting problem and generalise well to real-world applications, while requiring only minimal labelled data. With interest to the neuroscience community, the proposed method gives researchers a tool to separate individual brain processes and potentially even uncover heretofore unknown dynamics.
Motor Imagery Decoding Using Ensemble Curriculum Learning and Collaborative Training
Nov 21, 2022Objective: In this work, we study the problem of cross-subject motor imagery (MI) decoding from electroenchephalography (EEG) data. Multi-subject EEG datasets present several kinds of domain shifts due to various inter-individual differences (e.g. brain anatomy, personality and cognitive profile). These domain shifts render multi-subject training a challenging task and also impede robust cross-subject generalization. Method: We propose a two-stage model ensemble architecture, built with multiple feature extractors (first stage) and a shared classifier (second stage), which we train end-to-end with two loss terms. The first loss applies curriculum learning, forcing each feature extractor to specialize to a subset of the training subjects and promoting feature diversity. The second loss is an intra-ensemble distillation objective that allows collaborative exchange of knowledge between the models of the ensemble. Results: We compare our method against several state-of-the-art techniques, conducting subject-independent experiments on two large MI datasets, namely Physionet and OpenBMI. Our algorithm outperforms all of the methods in both 5-fold cross-validation and leave-one-subject-out evaluation settings, using a substantially lower number of trainable parameters. Conclusion: We demonstrate that our model ensembling approach combining the powers of curriculum learning and collaborative training, leads to high learning capacity and robust performance. Significance: Our work addresses the issue of domain shifts in multi-subject EEG datasets, paving the way for calibration-free BCI systems.
TARN: Temporal Attentive Relation Network for Few-Shot and Zero-Shot Action Recognition
Jul 21, 2019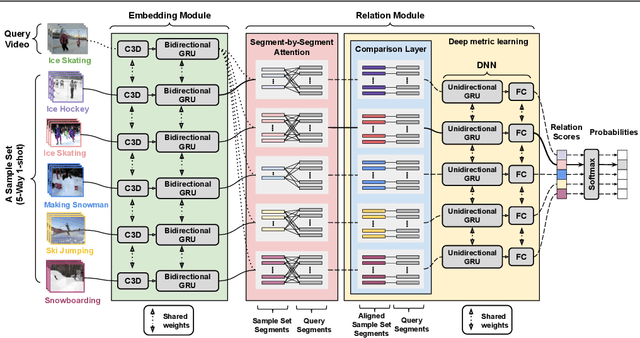
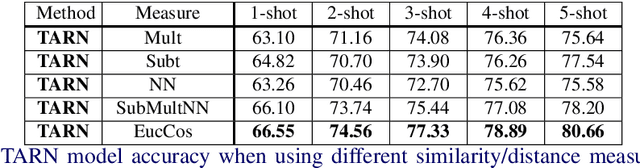
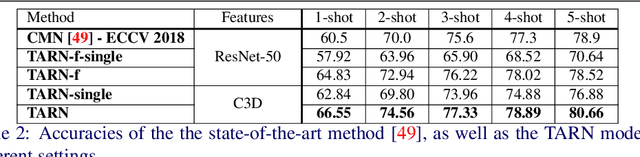

In this paper we propose a novel Temporal Attentive Relation Network (TARN) for the problems of few-shot and zero-shot action recognition. At the heart of our network is a meta-learning approach that learns to compare representations of variable temporal length, that is, either two videos of different length (in the case of few-shot action recognition) or a video and a semantic representation such as word vector (in the case of zero-shot action recognition). By contrast to other works in few-shot and zero-shot action recognition, we a) utilise attention mechanisms so as to perform temporal alignment, and b) learn a deep-distance measure on the aligned representations at video segment level. We adopt an episode-based training scheme and train our network in an end-to-end manner. The proposed method does not require any fine-tuning in the target domain or maintaining additional representations as is the case of memory networks. Experimental results show that the proposed architecture outperforms the state of the art in few-shot action recognition, and achieves competitive results in zero-shot action recognition.
Non-linear Convolution Filters for CNN-based Learning
Aug 23, 2017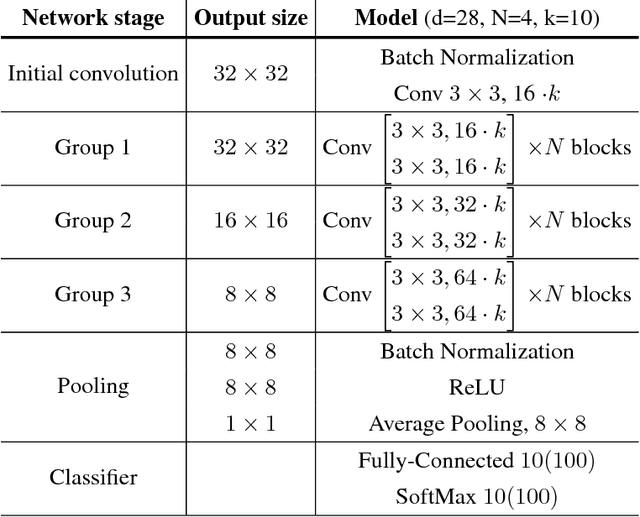
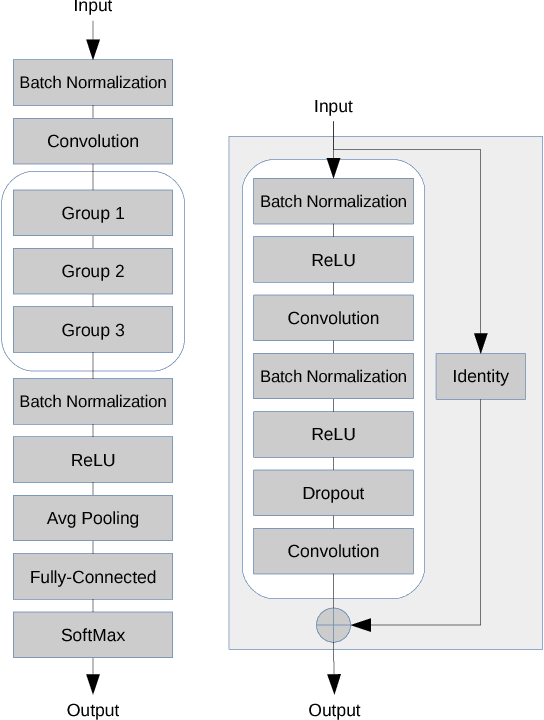
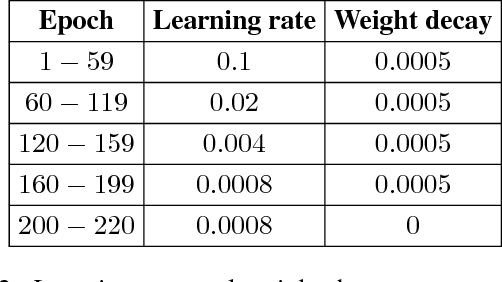
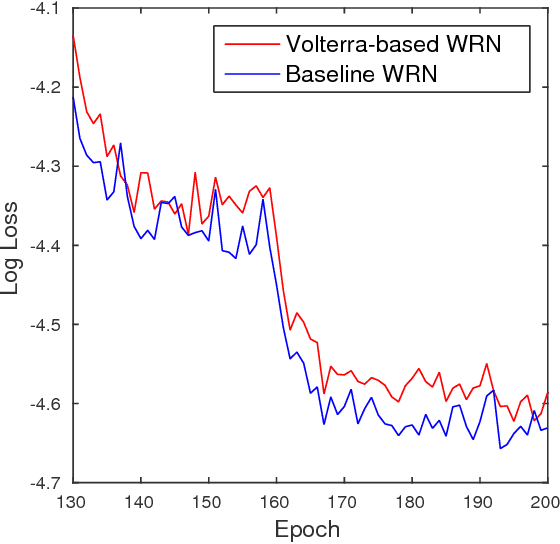
During the last years, Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance in image classification. Their architectures have largely drawn inspiration by models of the primate visual system. However, while recent research results of neuroscience prove the existence of non-linear operations in the response of complex visual cells, little effort has been devoted to extend the convolution technique to non-linear forms. Typical convolutional layers are linear systems, hence their expressiveness is limited. To overcome this, various non-linearities have been used as activation functions inside CNNs, while also many pooling strategies have been applied. We address the issue of developing a convolution method in the context of a computational model of the visual cortex, exploring quadratic forms through the Volterra kernels. Such forms, constituting a more rich function space, are used as approximations of the response profile of visual cells. Our proposed second-order convolution is tested on CIFAR-10 and CIFAR-100. We show that a network which combines linear and non-linear filters in its convolutional layers, can outperform networks that use standard linear filters with the same architecture, yielding results competitive with the state-of-the-art on these datasets.