 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Comparison of Deep Learning Models for Lung and COVID-19 Lesion Segmentation in CT scans
Sep 10, 2020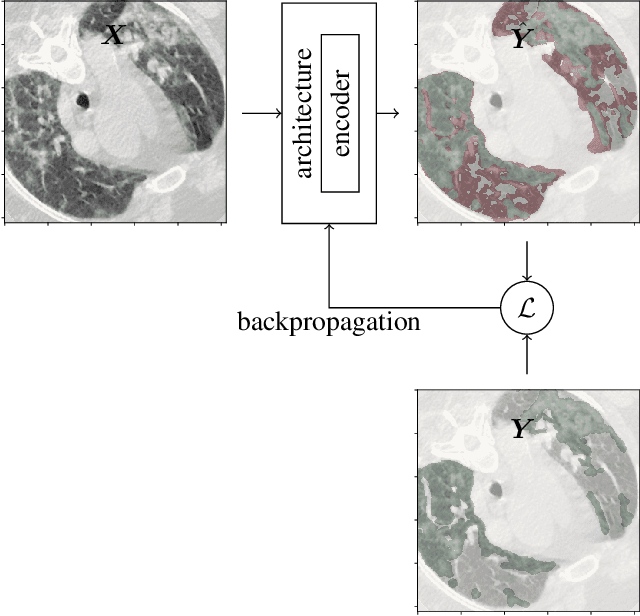



Recently there has been an explosion in the use of Deep Learning (DL) methods for medical image segmentation. However the field's reliability is hindered by the lack of a common base of reference for accuracy/performance evaluation and the fact that previous research uses different datasets for evaluation. In this paper, an extensive comparison of DL models for lung and COVID-19 lesion segmentation in Computerized Tomography (CT) scans is presented, which can also be used as a benchmark for testing medical image segmentation models. Four DL architectures (Unet, Linknet, FPN, PSPNet) are combined with 25 randomly initialized and pretrained encoders (variations of VGG, DenseNet, ResNet, ResNext, DPN, MobileNet, Xception, Inception-v4, EfficientNet), to construct 200 tested models. Three experimental setups are conducted for lung segmentation, lesion segmentation and lesion segmentation using the original lung masks. A public COVID-19 dataset with 100 CT scan images (80 for train, 20 for validation) is used for training/validation and a different public dataset consisting of 829 images from 9 CT scan volumes for testing. Multiple findings are provided including the best architecture-encoder models for each experiment as well as mean Dice results for each experiment, architecture and encoder independently. Finally, the upper bounds improvements when using lung masks as a preprocessing step or when using pretrained models are quantified. The source code and 600 pretrained models for the three experiments are provided, suitable for fine-tuning in experimental setups without GPU capabilities.
Multi-view adaptive graph convolutions for graph classification
Jul 24, 2020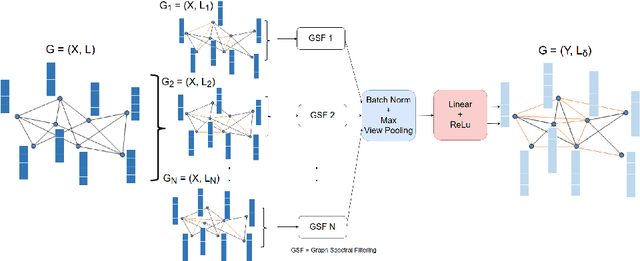
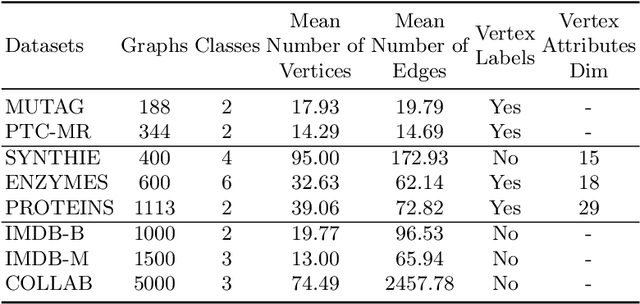
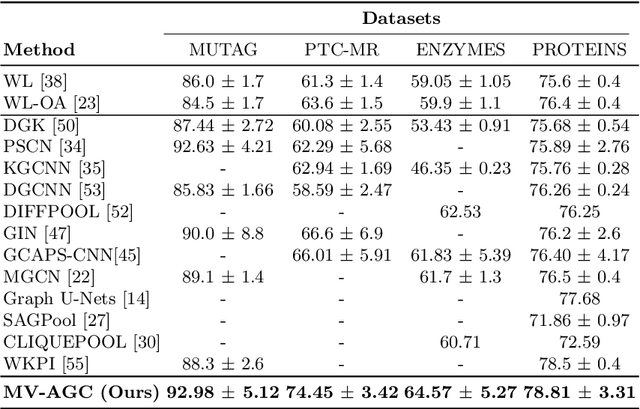
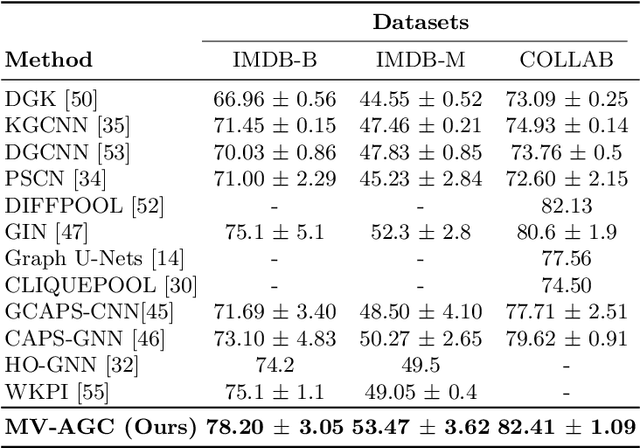
In this paper, a novel multi-view methodology for graph-based neural networks is proposed. A systematic and methodological adaptation of the key concepts of classical deep learning methods such as convolution, pooling and multi-view architectures is developed for the context of non-Euclidean manifolds. The aim of the proposed work is to present a novel multi-view graph convolution layer, as well as a new view pooling layer making use of: a) a new hybrid Laplacian that is adjusted based on feature distance metric learning, b) multiple trainable representations of a feature matrix of a graph, using trainable distance matrices, adapting the notion of views to graphs and c) a multi-view graph aggregation scheme called graph view pooling, in order to synthesise information from the multiple generated views. The aforementioned layers are used in an end-to-end graph neural network architecture for graph classification and show competitive results to other state-of-the-art methods.
An Improved Tobit Kalman Filter with Adaptive Censoring Limits
Nov 14, 2019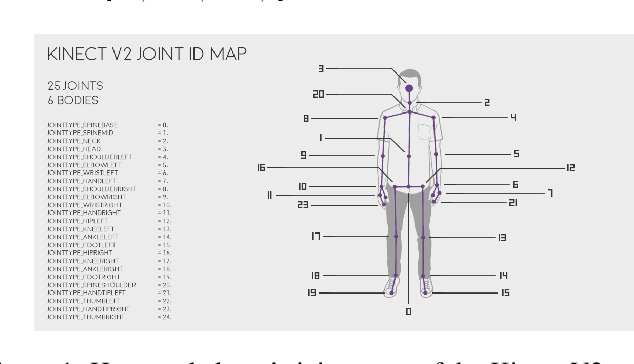

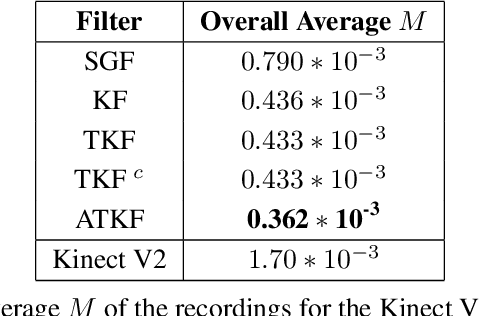
This paper deals with the Tobit Kalman filtering (TKF) process when the measurements are correlated and censored. The case of interval censoring, i.e., the case of measurements which belong to some interval with given censoring limits, is considered. Two improvements of the standard TKF process are proposed, in order to estimate the hidden state vectors. Firstly, the exact covariance matrix of the censored measurements is calculated by taking into account the censoring limits. Secondly, the probability of a latent (normally distributed) measurement to belong in or out of the uncensored region is calculated by taking into account the Kalman residual. The designed algorithm is tested using both synthetic and real data sets. The real data set includes human skeleton joints' coordinates captured by the Microsoft Kinect II sensor. In order to cope with certain real-life situations that cause problems in human skeleton tracking, such as (self)-occlusions, closely interacting persons etc., adaptive censoring limits are used in the proposed TKF process. Experiments show that the proposed method outperforms other filtering processes in minimizing the overall Root Mean Square Error (RMSE) for synthetic and real data sets.
Non-linear Convolution Filters for CNN-based Learning
Aug 23, 2017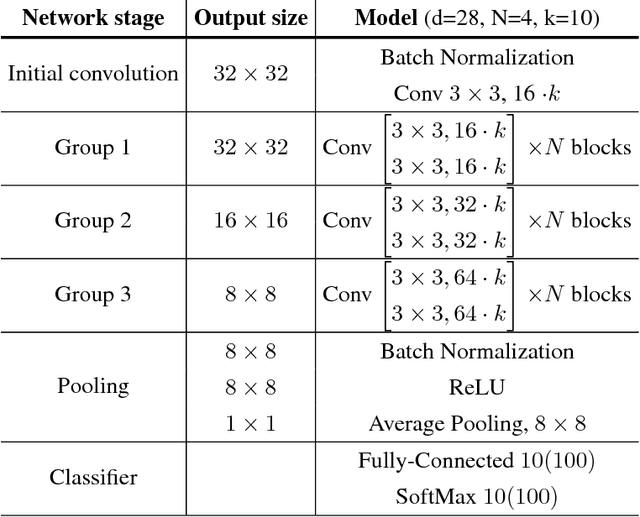
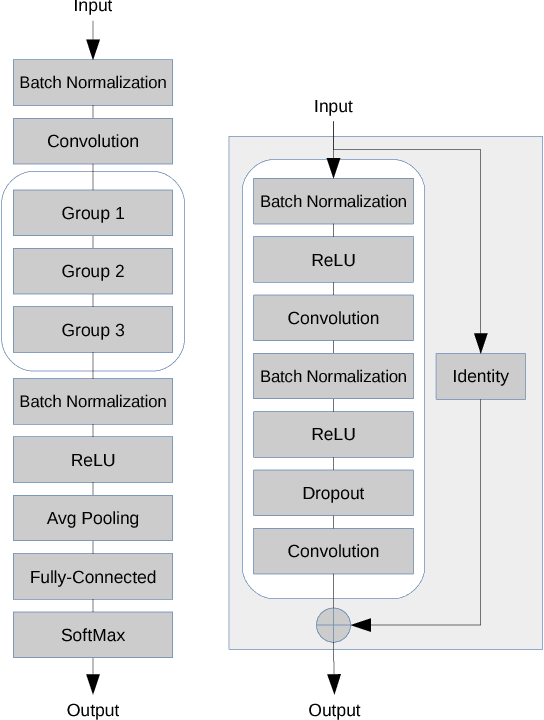
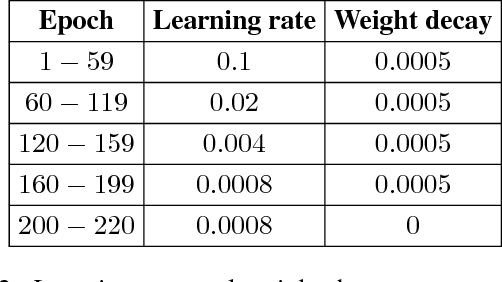
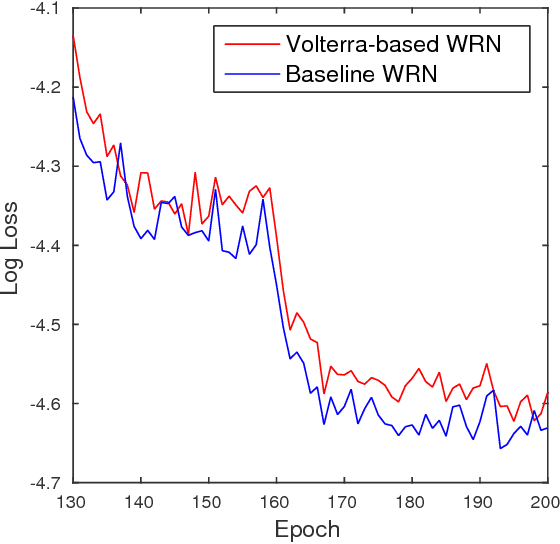
During the last years, Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance in image classification. Their architectures have largely drawn inspiration by models of the primate visual system. However, while recent research results of neuroscience prove the existence of non-linear operations in the response of complex visual cells, little effort has been devoted to extend the convolution technique to non-linear forms. Typical convolutional layers are linear systems, hence their expressiveness is limited. To overcome this, various non-linearities have been used as activation functions inside CNNs, while also many pooling strategies have been applied. We address the issue of developing a convolution method in the context of a computational model of the visual cortex, exploring quadratic forms through the Volterra kernels. Such forms, constituting a more rich function space, are used as approximations of the response profile of visual cells. Our proposed second-order convolution is tested on CIFAR-10 and CIFAR-100. We show that a network which combines linear and non-linear filters in its convolutional layers, can outperform networks that use standard linear filters with the same architecture, yielding results competitive with the state-of-the-art on these datasets.