 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Jun 12, 2024



Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
Challenging Gradient Boosted Decision Trees with Tabular Transformers for Fraud Detection at Booking.com
May 22, 2024Transformer-based neural networks, empowered by Self-Supervised Learning (SSL), have demonstrated unprecedented performance across various domains. However, related literature suggests that tabular Transformers may struggle to outperform classical Machine Learning algorithms, such as Gradient Boosted Decision Trees (GBDT). In this paper, we aim to challenge GBDTs with tabular Transformers on a typical task faced in e-commerce, namely fraud detection. Our study is additionally motivated by the problem of selection bias, often occurring in real-life fraud detection systems. It is caused by the production system affecting which subset of traffic becomes labeled. This issue is typically addressed by sampling randomly a small part of the whole production data, referred to as a Control Group. This subset follows a target distribution of production data and therefore is usually preferred for training classification models with standard ML algorithms. Our methodology leverages the capabilities of Transformers to learn transferable representations using all available data by means of SSL, giving it an advantage over classical methods. Furthermore, we conduct large-scale experiments, pre-training tabular Transformers on vast amounts of data instances and fine-tuning them on smaller target datasets. The proposed approach outperforms heavily tuned GBDTs by a considerable margin of the Average Precision (AP) score. Pre-trained models show more consistent performance than the ones trained from scratch when fine-tuning data is limited. Moreover, they require noticeably less labeled data for reaching performance comparable to their GBDT competitor that utilizes the whole dataset.
Explaining, Analyzing, and Probing Representations of Self-Supervised Learning Models for Sensor-based Human Activity Recognition
Apr 14, 2023



In recent years, self-supervised learning (SSL) frameworks have been extensively applied to sensor-based Human Activity Recognition (HAR) in order to learn deep representations without data annotations. While SSL frameworks reach performance almost comparable to supervised models, studies on interpreting representations learnt by SSL models are limited. Nevertheless, modern explainability methods could help to unravel the differences between SSL and supervised representations: how they are being learnt, what properties of input data they preserve, and when SSL can be chosen over supervised training. In this paper, we aim to analyze deep representations of two recent SSL frameworks, namely SimCLR and VICReg. Specifically, the emphasis is made on (i) comparing the robustness of supervised and SSL models to corruptions in input data; (ii) explaining predictions of deep learning models using saliency maps and highlighting what input channels are mostly used for predicting various activities; (iii) exploring properties encoded in SSL and supervised representations using probing. Extensive experiments on two single-device datasets (MobiAct and UCI-HAR) have shown that self-supervised learning representations are significantly more robust to noise in unseen data compared to supervised models. In contrast, features learnt by the supervised approaches are more homogeneous across subjects and better encode the nature of activities.
Temporal Feature Alignment in Contrastive Self-Supervised Learning for Human Activity Recognition
Oct 07, 2022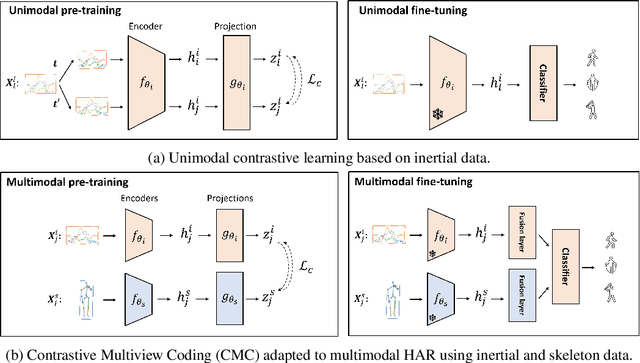
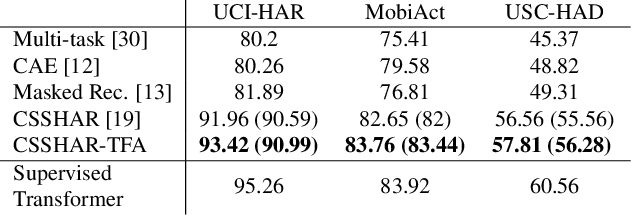
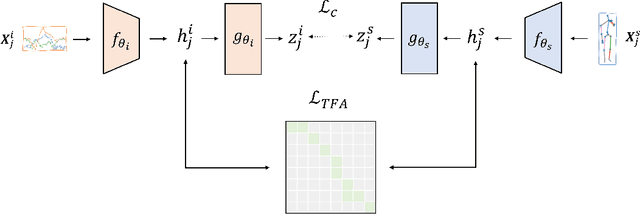
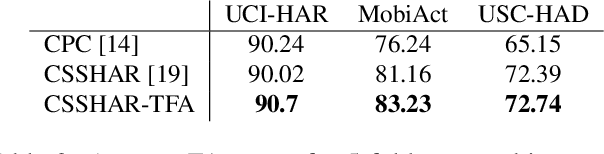
Automated Human Activity Recognition has long been a problem of great interest in human-centered and ubiquitous computing. In the last years, a plethora of supervised learning algorithms based on deep neural networks has been suggested to address this problem using various modalities. While every modality has its own limitations, there is one common challenge. Namely, supervised learning requires vast amounts of annotated data which is practically hard to collect. In this paper, we benefit from the self-supervised learning paradigm (SSL) that is typically used to learn deep feature representations from unlabeled data. Moreover, we upgrade a contrastive SSL framework, namely SimCLR, widely used in various applications by introducing a temporal feature alignment procedure for Human Activity Recognition. Specifically, we propose integrating a dynamic time warping (DTW) algorithm in a latent space to force features to be aligned in a temporal dimension. Extensive experiments have been conducted for the unimodal scenario with inertial modality as well as in multimodal settings using inertial and skeleton data. According to the obtained results, the proposed approach has a great potential in learning robust feature representations compared to the recent SSL baselines, and clearly outperforms supervised models in semi-supervised learning. The code for the unimodal case is available via the following link: https://github.com/bulatkh/csshar_tfa.
Contrastive Learning with Cross-Modal Knowledge Mining for Multimodal Human Activity Recognition
May 20, 2022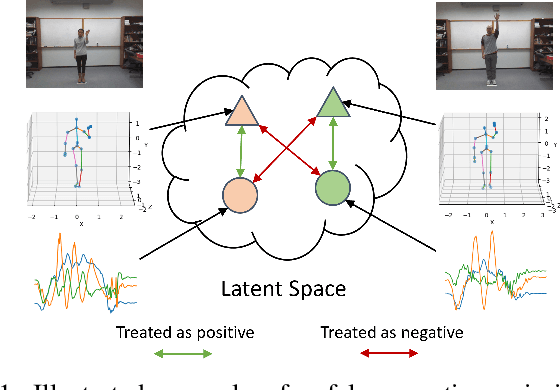
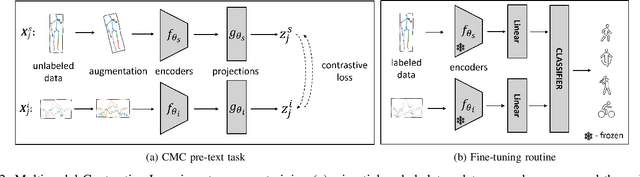
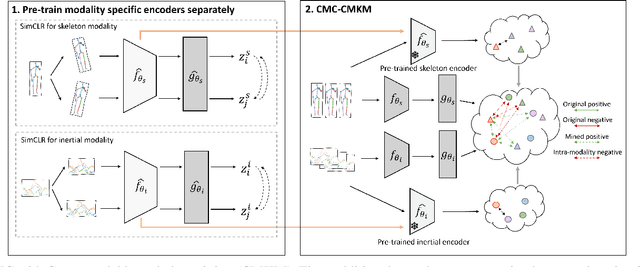
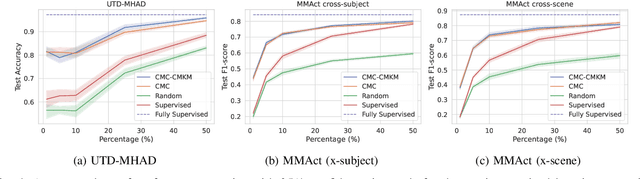
Human Activity Recognition is a field of research where input data can take many forms. Each of the possible input modalities describes human behaviour in a different way, and each has its own strengths and weaknesses. We explore the hypothesis that leveraging multiple modalities can lead to better recognition. Since manual annotation of input data is expensive and time-consuming, the emphasis is made on self-supervised methods which can learn useful feature representations without any ground truth labels. We extend a number of recent contrastive self-supervised approaches for the task of Human Activity Recognition, leveraging inertial and skeleton data. Furthermore, we propose a flexible, general-purpose framework for performing multimodal self-supervised learning, named Contrastive Multiview Coding with Cross-Modal Knowledge Mining (CMC-CMKM). This framework exploits modality-specific knowledge in order to mitigate the limitations of typical self-supervised frameworks. The extensive experiments on two widely-used datasets demonstrate that the suggested framework significantly outperforms contrastive unimodal and multimodal baselines on different scenarios, including fully-supervised fine-tuning, activity retrieval and semi-supervised learning. Furthermore, it shows performance competitive even compared to supervised methods.