 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData mining for censored time-to-event data: A Bayesian network model for predicting cardiovascular risk from electronic health record data
Apr 08, 2014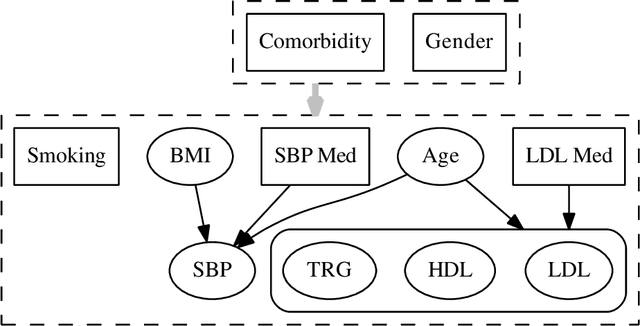


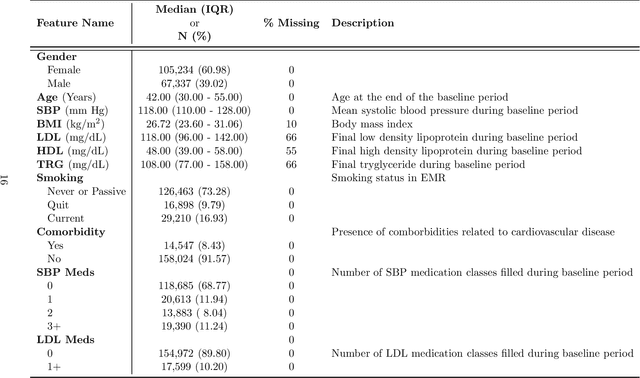
Models for predicting the risk of cardiovascular events based on individual patient characteristics are important tools for managing patient care. Most current and commonly used risk prediction models have been built from carefully selected epidemiological cohorts. However, the homogeneity and limited size of such cohorts restricts the predictive power and generalizability of these risk models to other populations. Electronic health data (EHD) from large health care systems provide access to data on large, heterogeneous, and contemporaneous patient populations. The unique features and challenges of EHD, including missing risk factor information, non-linear relationships between risk factors and cardiovascular event outcomes, and differing effects from different patient subgroups, demand novel machine learning approaches to risk model development. In this paper, we present a machine learning approach based on Bayesian networks trained on EHD to predict the probability of having a cardiovascular event within five years. In such data, event status may be unknown for some individuals as the event time is right-censored due to disenrollment and incomplete follow-up. Since many traditional data mining methods are not well-suited for such data, we describe how to modify both modelling and assessment techniques to account for censored observation times. We show that our approach can lead to better predictive performance than the Cox proportional hazards model (i.e., a regression-based approach commonly used for censored, time-to-event data) or a Bayesian network with {\em{ad hoc}} approaches to right-censoring. Our techniques are motivated by and illustrated on data from a large U.S. Midwestern health care system.
A Naive Bayes machine learning approach to risk prediction using censored, time-to-event data
Apr 08, 2014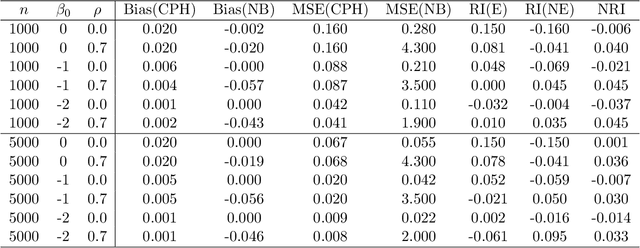
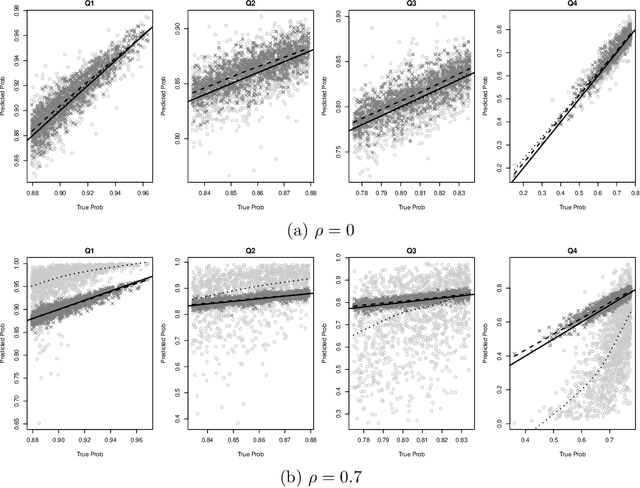
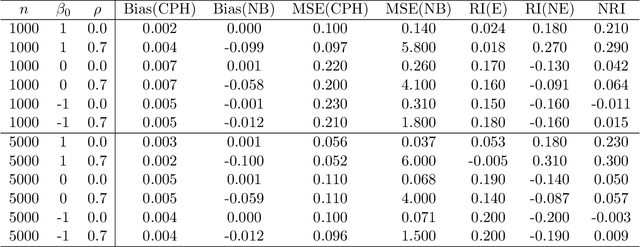
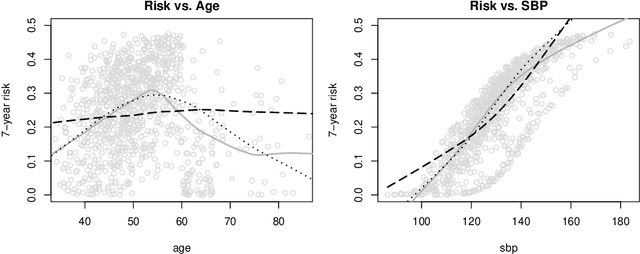
Predicting an individual's risk of experiencing a future clinical outcome is a statistical task with important consequences for both practicing clinicians and public health experts. Modern observational databases such as electronic health records (EHRs) provide an alternative to the longitudinal cohort studies traditionally used to construct risk models, bringing with them both opportunities and challenges. Large sample sizes and detailed covariate histories enable the use of sophisticated machine learning techniques to uncover complex associations and interactions, but observational databases are often ``messy,'' with high levels of missing data and incomplete patient follow-up. In this paper, we propose an adaptation of the well-known Naive Bayes (NB) machine learning approach for classification to time-to-event outcomes subject to censoring. We compare the predictive performance of our method to the Cox proportional hazards model which is commonly used for risk prediction in healthcare populations, and illustrate its application to prediction of cardiovascular risk using an EHR dataset from a large Midwest integrated healthcare system.