 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Biomedical Question-Answering Services with LLM and Multi-BERT Integration
Oct 11, 2024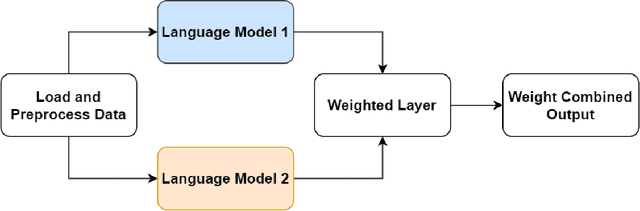
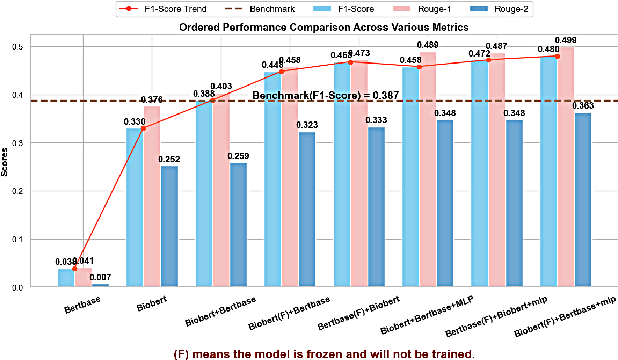
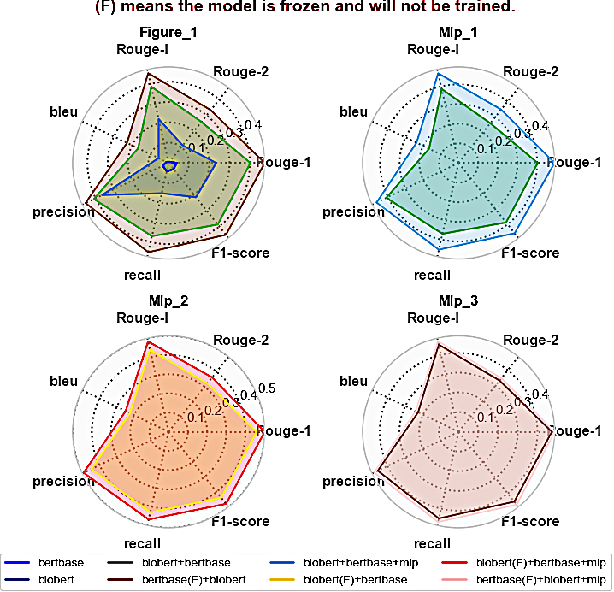
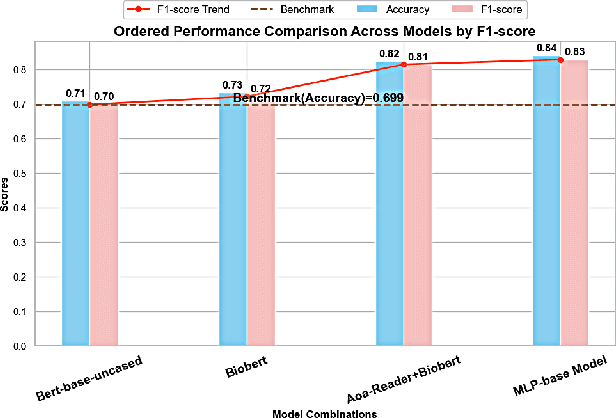
We present a refined approach to biomedical question-answering (QA) services by integrating large language models (LLMs) with Multi-BERT configurations. By enhancing the ability to process and prioritize vast amounts of complex biomedical data, this system aims to support healthcare professionals in delivering better patient outcomes and informed decision-making. Through innovative use of BERT and BioBERT models, combined with a multi-layer perceptron (MLP) layer, we enable more specialized and efficient responses to the growing demands of the healthcare sector. Our approach not only addresses the challenge of overfitting by freezing one BERT model while training another but also improves the overall adaptability of QA services. The use of extensive datasets, such as BioASQ and BioMRC, demonstrates the system's ability to synthesize critical information. This work highlights how advanced language models can make a tangible difference in healthcare, providing reliable and responsive tools for professionals to manage complex information, ultimately serving the broader goal of improved care and data-driven insights.
A Multi-tasking Model of Speaker-Keyword Classification for Keeping Human in the Loop of Drone-assisted Inspection
Jul 08, 2022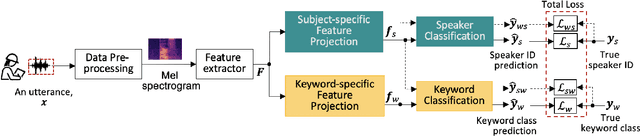

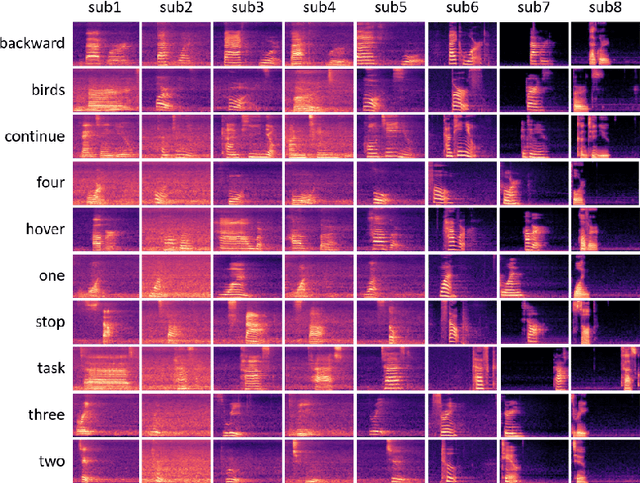

Audio commands are a preferred communication medium to keep inspectors in the loop of civil infrastructure inspection performed by a semi-autonomous drone. To understand job-specific commands from a group of heterogeneous and dynamic inspectors, a model needs to be developed cost-effectively for the group and easily adapted when the group changes. This paper is motivated to build a multi-tasking deep learning model that possesses a Share-Split-Collaborate architecture. This architecture allows the two classification tasks to share the feature extractor and then split subject-specific and keyword-specific features intertwined in the extracted features through feature projection and collaborative training. A base model for a group of five authorized subjects is trained and tested on the inspection keyword dataset collected by this study. The model achieved a 95.3% or higher mean accuracy in classifying the keywords of any authorized inspectors. Its mean accuracy in speaker classification is 99.2%. Due to the richer keyword representations that the model learns from the pooled training data, adapting the base model to a new inspector requires only a little training data from that inspector, like five utterances per keyword. Using the speaker classification scores for inspector verification can achieve a success rate of at least 93.9% in verifying authorized inspectors and 76.1\% in detecting unauthorized ones. Further, the paper demonstrates the applicability of the proposed model to larger-size groups on a public dataset. This paper provides a solution to addressing challenges facing AI-assisted human-robot interaction, including worker heterogeneity, worker dynamics, and job heterogeneity.