 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Single Image to 3D Generation using Gaussian Splatting and Hybrid Diffusion Priors
Paper and Code
Oct 12, 2024
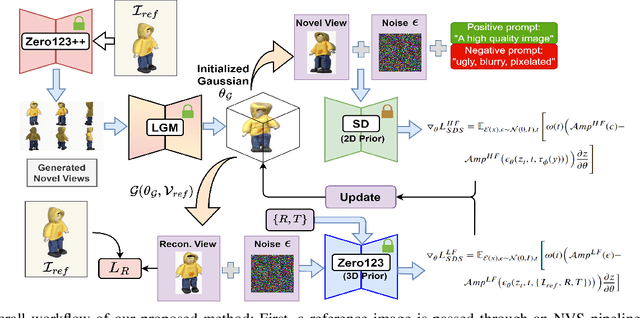
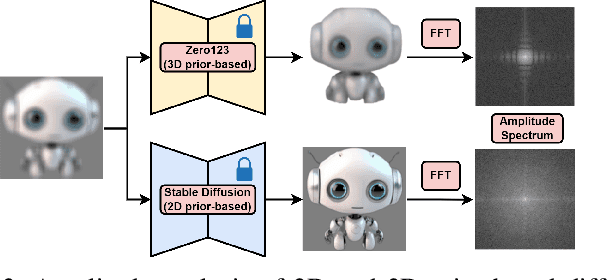
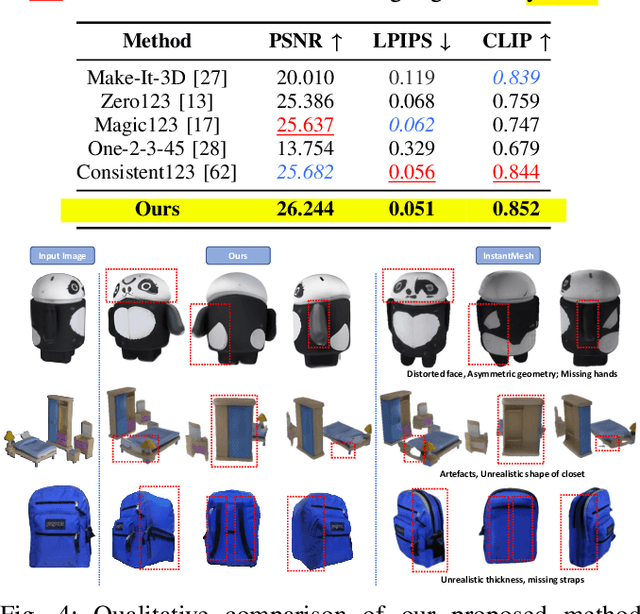
3D object generation from a single image involves estimating the full 3D geometry and texture of unseen views from an unposed RGB image captured in the wild. Accurately reconstructing an object's complete 3D structure and texture has numerous applications in real-world scenarios, including robotic manipulation, grasping, 3D scene understanding, and AR/VR. Recent advancements in 3D object generation have introduced techniques that reconstruct an object's 3D shape and texture by optimizing the efficient representation of Gaussian Splatting, guided by pre-trained 2D or 3D diffusion models. However, a notable disparity exists between the training datasets of these models, leading to distinct differences in their outputs. While 2D models generate highly detailed visuals, they lack cross-view consistency in geometry and texture. In contrast, 3D models ensure consistency across different views but often result in overly smooth textures. We propose bridging the gap between 2D and 3D diffusion models to address this limitation by integrating a two-stage frequency-based distillation loss with Gaussian Splatting. Specifically, we leverage geometric priors in the low-frequency spectrum from a 3D diffusion model to maintain consistent geometry and use a 2D diffusion model to refine the fidelity and texture in the high-frequency spectrum of the generated 3D structure, resulting in more detailed and fine-grained outcomes. Our approach enhances geometric consistency and visual quality, outperforming the current SOTA. Additionally, we demonstrate the easy adaptability of our method for efficient object pose estimation and tracking.