 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancements in Repetitive Action Counting: Joint-Based PoseRAC Model With Improved Performance
Aug 15, 2023



Repetitive counting (RepCount) is critical in various applications, such as fitness tracking and rehabilitation. Previous methods have relied on the estimation of red-green-and-blue (RGB) frames and body pose landmarks to identify the number of action repetitions, but these methods suffer from a number of issues, including the inability to stably handle changes in camera viewpoints, over-counting, under-counting, difficulty in distinguishing between sub-actions, inaccuracy in recognizing salient poses, etc. In this paper, based on the work done by [1], we integrate joint angles with body pose landmarks to address these challenges and achieve better results than the state-of-the-art RepCount methods, with a Mean Absolute Error (MAE) of 0.211 and an Off-By-One (OBO) counting accuracy of 0.599 on the RepCount data set [2]. Comprehensive experimental results demonstrate the effectiveness and robustness of our method.
SalGaze: Personalizing Gaze Estimation Using Visual Saliency
Oct 23, 2019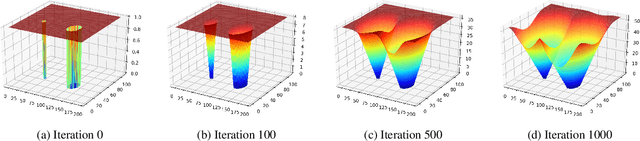
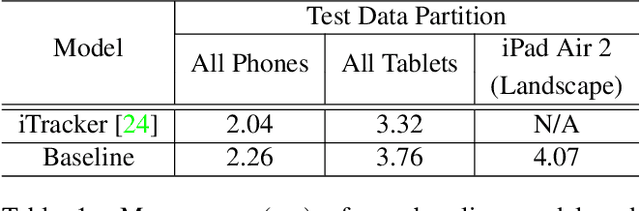
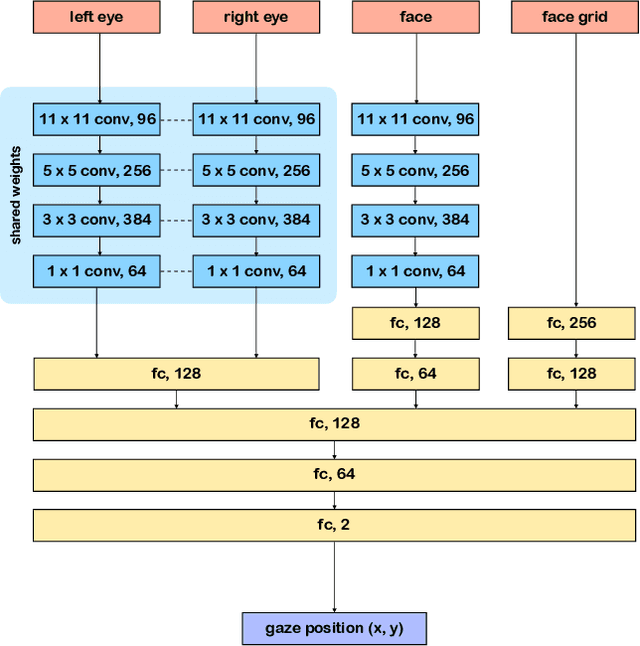
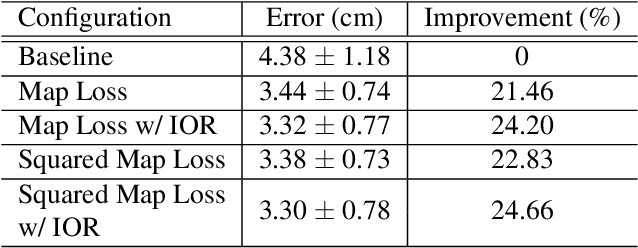
Traditional gaze estimation methods typically require explicit user calibration to achieve high accuracy. This process is cumbersome and recalibration is often required when there are changes in factors such as illumination and pose. To address this challenge, we introduce SalGaze, a framework that utilizes saliency information in the visual content to transparently adapt the gaze estimation algorithm to the user without explicit user calibration. We design an algorithm to transform a saliency map into a differentiable loss map that can be used for the optimization of CNN-based models. SalGaze is also able to greatly augment standard point calibration data with implicit video saliency calibration data using a unified framework. We show accuracy improvements over 24% using our technique on existing methods.