 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Wield: Systematic Reinforcement Learning With Progressive Randomization
Sep 15, 2019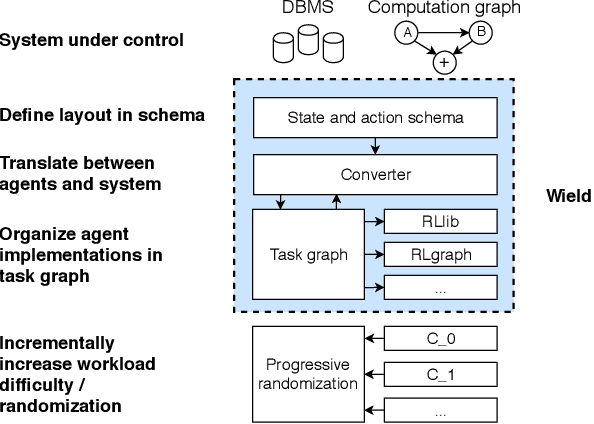
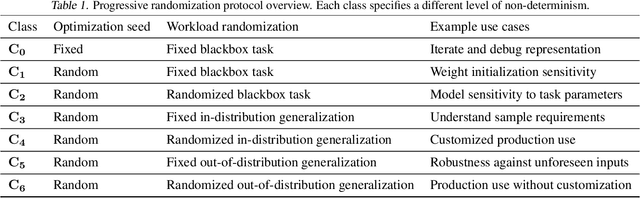

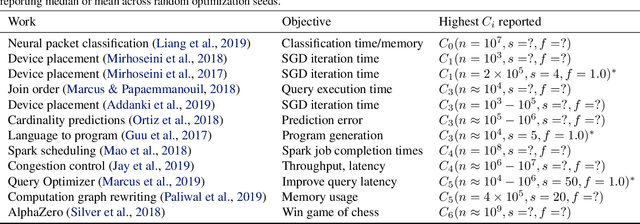
Reinforcement learning frameworks have introduced abstractions to implement and execute algorithms at scale. They assume standardized simulator interfaces but are not concerned with identifying suitable task representations. We present Wield, a first-of-its kind system to facilitate task design for practical reinforcement learning. Through software primitives, Wield enables practitioners to decouple system-interface and deployment-specific configuration from state and action design. To guide experimentation, Wield further introduces a novel task design protocol and classification scheme centred around staged randomization to incrementally evaluate model capabilities.
RLgraph: Flexible Computation Graphs for Deep Reinforcement Learning
Oct 21, 2018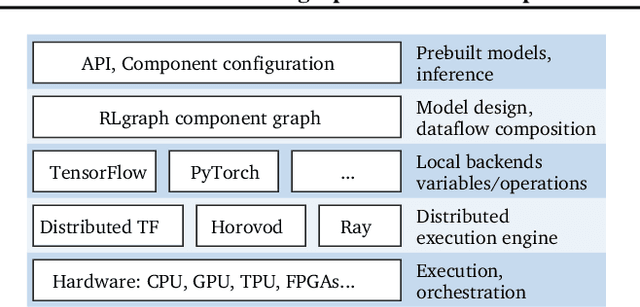
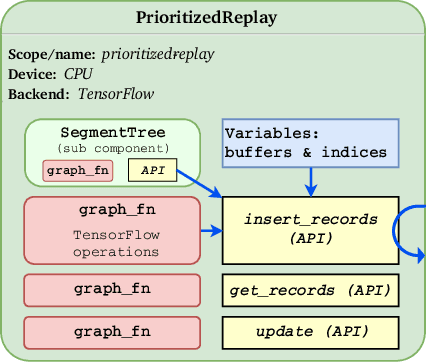

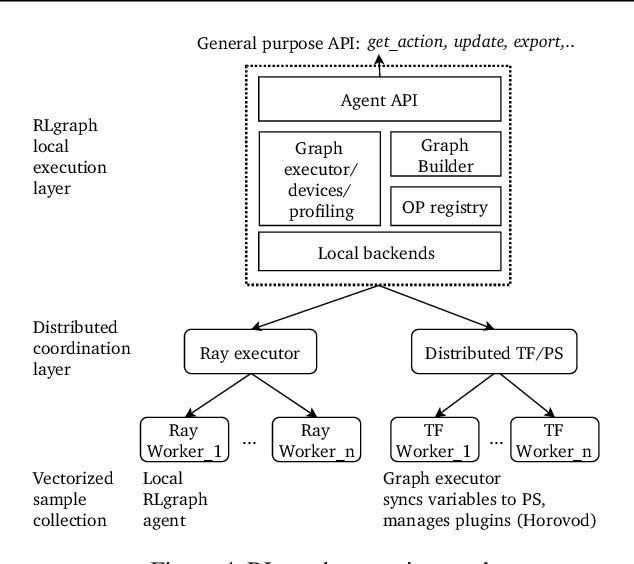
Reinforcement learning (RL) tasks are challenging to implement, execute and test due to algorithmic instability, hyper-parameter sensitivity, and heterogeneous distributed communication patterns. We argue for the separation of logical component composition, backend graph definition, and distributed execution. To this end, we introduce RLgraph, a library for designing and executing high performance RL computation graphs in both static graph and define-by-run paradigms. The resulting implementations yield high performance across different deep learning frameworks and distributed backends.
LIFT: Reinforcement Learning in Computer Systems by Learning From Demonstrations
Aug 23, 2018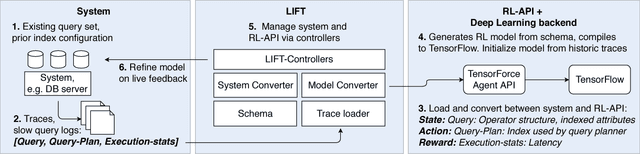

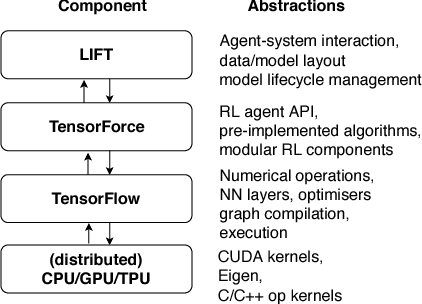
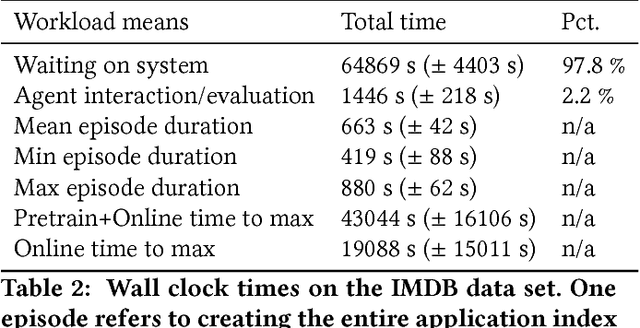
Reinforcement learning approaches have long appealed to the data management community due to their ability to learn to control dynamic behavior from raw system performance. Recent successes in combining deep neural networks with reinforcement learning have sparked significant new interest in this domain. However, practical solutions remain elusive due to large training data requirements, algorithmic instability, and lack of standard tools. In this work, we introduce LIFT, an end-to-end software stack for applying deep reinforcement learning to data management tasks. While prior work has frequently explored applications in simulations, LIFT centers on utilizing human expertise to learn from demonstrations, thus lowering online training times. We further introduce TensorForce, a TensorFlow library for applied deep reinforcement learning exposing a unified declarative interface to common RL algorithms, thus providing a backend to LIFT. We demonstrate the utility of LIFT in two case studies in database compound indexing and resource management in stream processing. Results show LIFT controllers initialized from demonstrations can outperform human baselines and heuristics across latency metrics and space usage by up to 70%.