 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIFT: Reinforcement Learning in Computer Systems by Learning From Demonstrations
Aug 23, 2018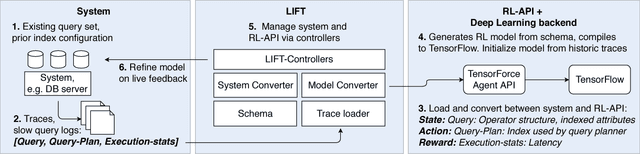

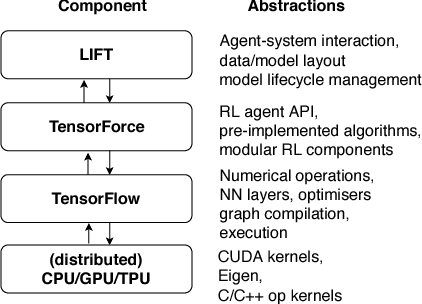
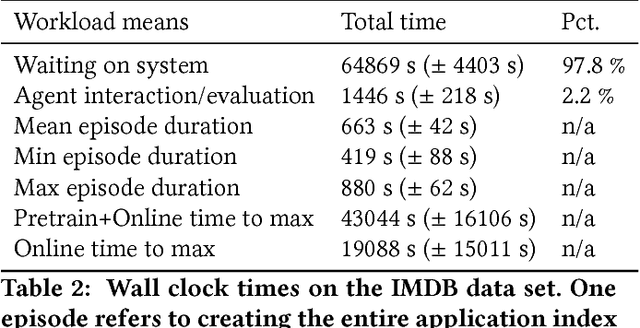
Reinforcement learning approaches have long appealed to the data management community due to their ability to learn to control dynamic behavior from raw system performance. Recent successes in combining deep neural networks with reinforcement learning have sparked significant new interest in this domain. However, practical solutions remain elusive due to large training data requirements, algorithmic instability, and lack of standard tools. In this work, we introduce LIFT, an end-to-end software stack for applying deep reinforcement learning to data management tasks. While prior work has frequently explored applications in simulations, LIFT centers on utilizing human expertise to learn from demonstrations, thus lowering online training times. We further introduce TensorForce, a TensorFlow library for applied deep reinforcement learning exposing a unified declarative interface to common RL algorithms, thus providing a backend to LIFT. We demonstrate the utility of LIFT in two case studies in database compound indexing and resource management in stream processing. Results show LIFT controllers initialized from demonstrations can outperform human baselines and heuristics across latency metrics and space usage by up to 70%.
Learning Runtime Parameters in Computer Systems with Delayed Experience Injection
Oct 31, 2016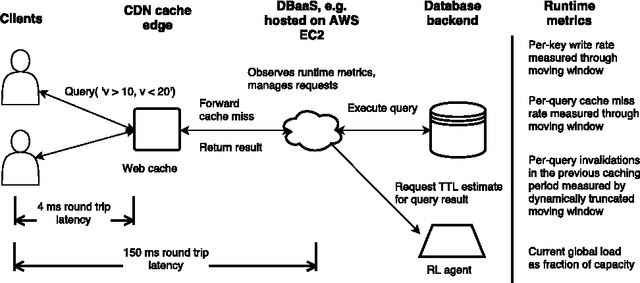
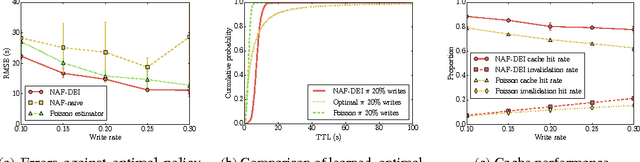
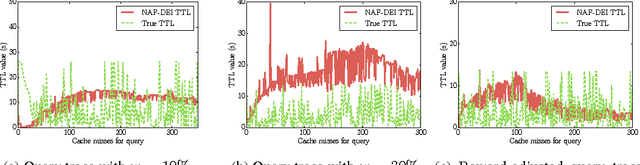
Learning effective configurations in computer systems without hand-crafting models for every parameter is a long-standing problem. This paper investigates the use of deep reinforcement learning for runtime parameters of cloud databases under latency constraints. Cloud services serve up to thousands of concurrent requests per second and can adjust critical parameters by leveraging performance metrics. In this work, we use continuous deep reinforcement learning to learn optimal cache expirations for HTTP caching in content delivery networks. To this end, we introduce a technique for asynchronous experience management called delayed experience injection, which facilitates delayed reward and next-state computation in concurrent environments where measurements are not immediately available. Evaluation results show that our approach based on normalized advantage functions and asynchronous CPU-only training outperforms a statistical estimator.