 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR4REAL: An extended benchmark for speech models
Paper and Code
Oct 16, 2021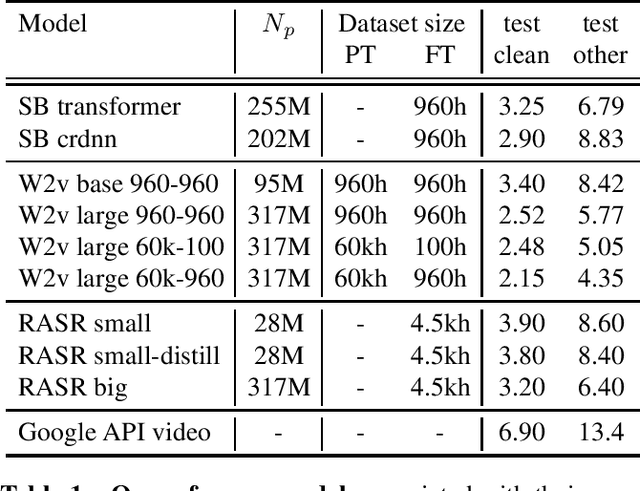
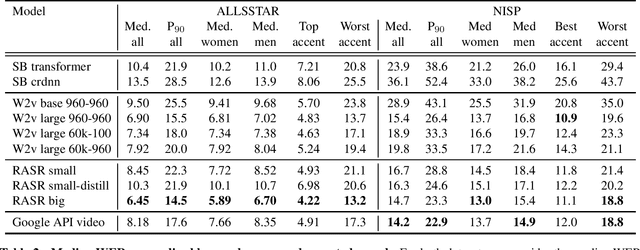
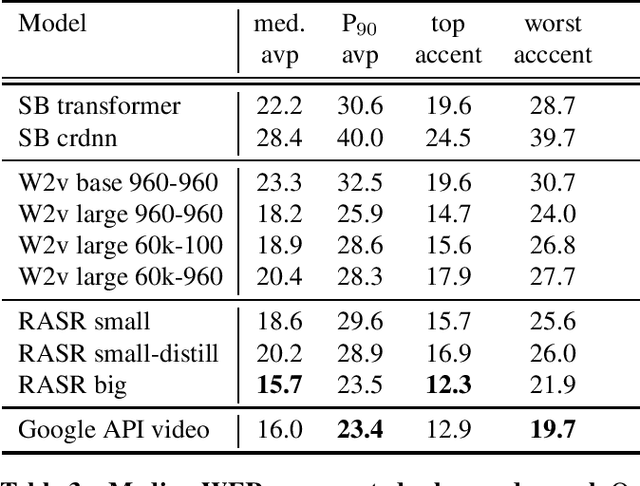
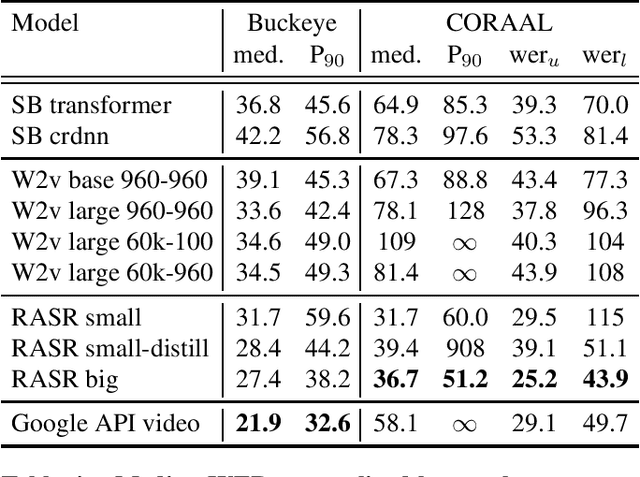
Popular ASR benchmarks such as Librispeech and Switchboard are limited in the diversity of settings and speakers they represent. We introduce a set of benchmarks matching real-life conditions, aimed at spotting possible biases and weaknesses in models. We have found out that even though recent models do not seem to exhibit a gender bias, they usually show important performance discrepancies by accent, and even more important ones depending on the socio-economic status of the speakers. Finally, all tested models show a strong performance drop when tested on conversational speech, and in this precise context even a language model trained on a dataset as big as Common Crawl does not seem to have significant positive effect which reiterates the importance of developing conversational language models