 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022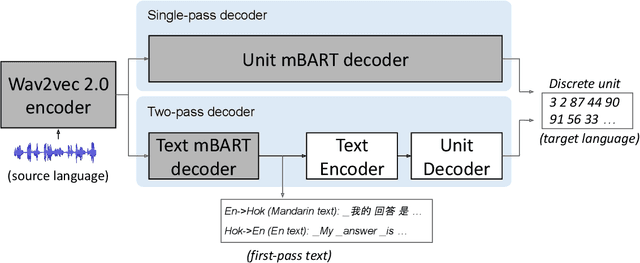
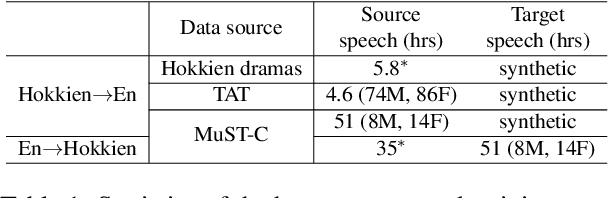
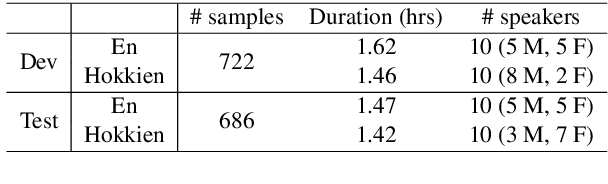
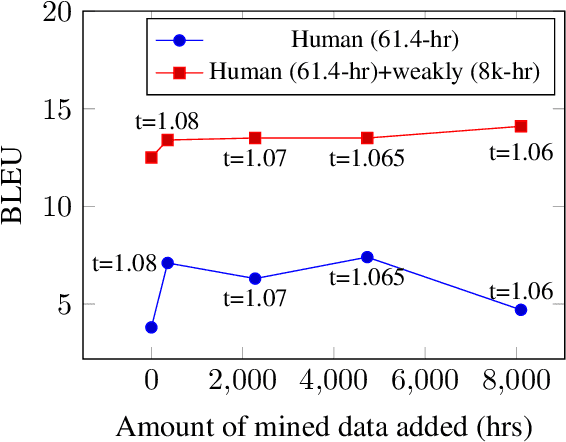
We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
CheXseen: Unseen Disease Detection for Deep Learning Interpretation of Chest X-rays
Mar 08, 2021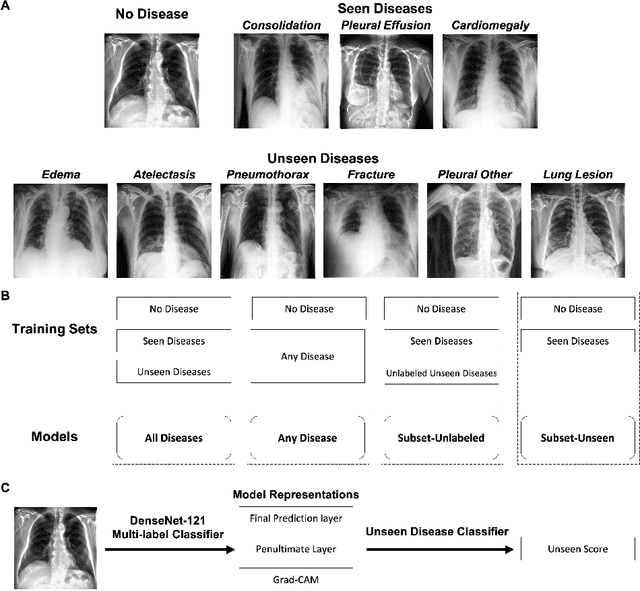
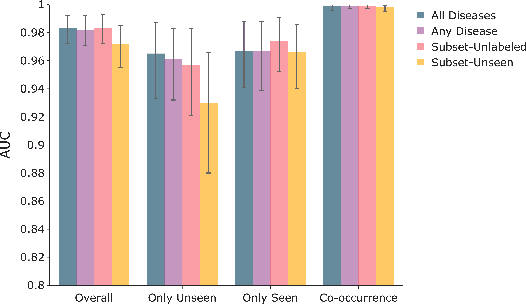
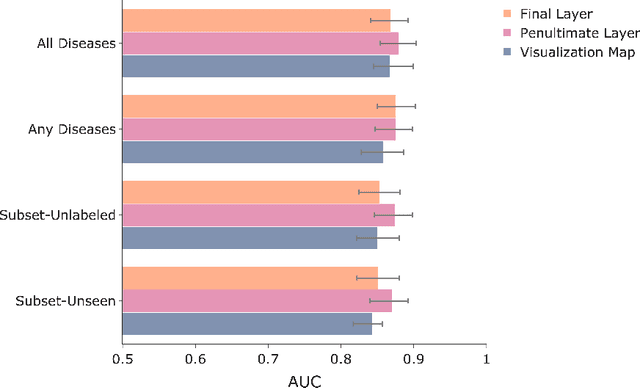
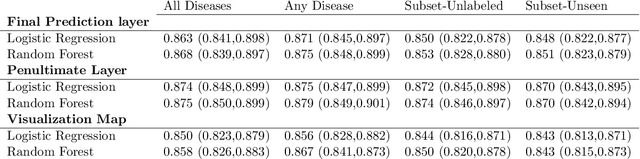
We systematically evaluate the performance of deep learning models in the presence of diseases not labeled for or present during training. First, we evaluate whether deep learning models trained on a subset of diseases (seen diseases) can detect the presence of any one of a larger set of diseases. We find that models tend to falsely classify diseases outside of the subset (unseen diseases) as "no disease". Second, we evaluate whether models trained on seen diseases can detect seen diseases when co-occurring with diseases outside the subset (unseen diseases). We find that models are still able to detect seen diseases even when co-occurring with unseen diseases. Third, we evaluate whether feature representations learned by models may be used to detect the presence of unseen diseases given a small labeled set of unseen diseases. We find that the penultimate layer of the deep neural network provides useful features for unseen disease detection. Our results can inform the safe clinical deployment of deep learning models trained on a non-exhaustive set of disease classes.
The Open Catalyst 2020 Dataset and Community Challenges
Oct 20, 2020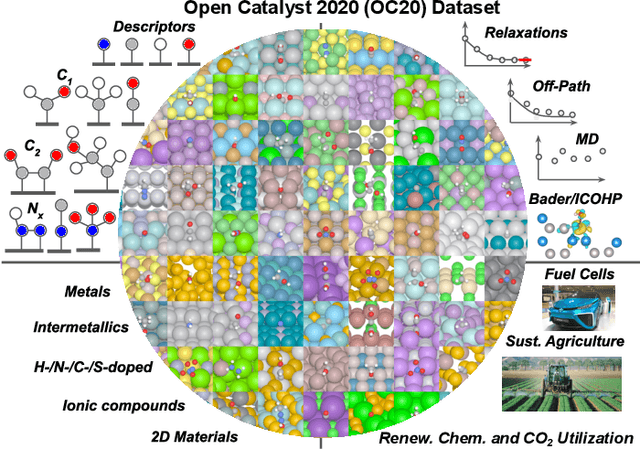

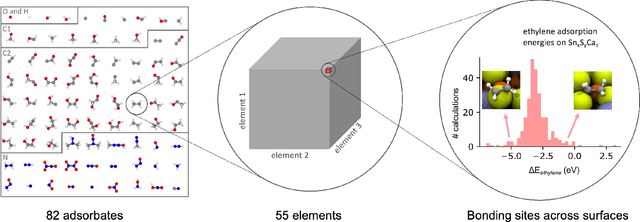
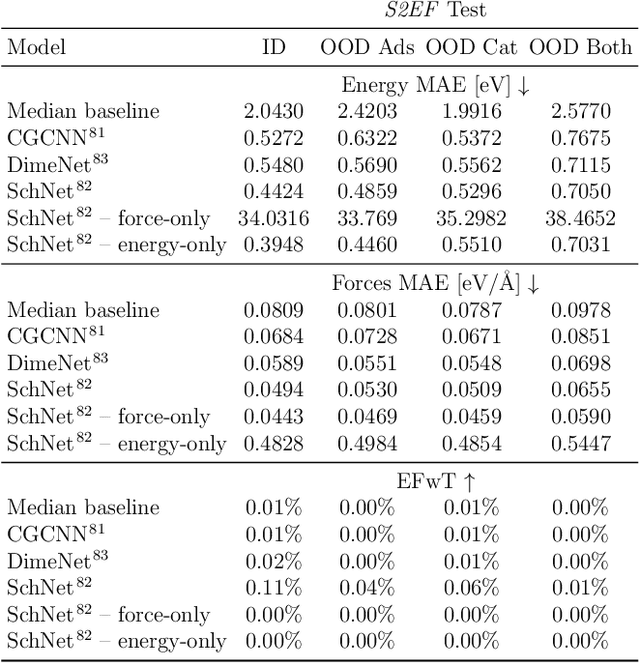
Catalyst discovery and optimization is key to solving many societal and energy challenges including solar fuels synthesis, long-term energy storage, and renewable fertilizer production. Despite considerable effort by the catalysis community to apply machine learning models to the computational catalyst discovery process, it remains an open challenge to build models that can generalize across both elemental compositions of surfaces and adsorbate identity/configurations, perhaps because datasets have been smaller in catalysis than related fields. To address this we developed the OC20 dataset, consisting of 1,281,121 Density Functional Theory (DFT) relaxations (264,900,500 single point evaluations) across a wide swath of materials, surfaces, and adsorbates (nitrogen, carbon, and oxygen chemistries). We supplemented this dataset with randomly perturbed structures, short timescale molecular dynamics, and electronic structure analyses. The dataset comprises three central tasks indicative of day-to-day catalyst modeling and comes with pre-defined train/validation/test splits to facilitate direct comparisons with future model development efforts. We applied three state-of-the-art graph neural network models (SchNet, Dimenet, CGCNN) to each of these tasks as baseline demonstrations for the community to build on. In almost every task, no upper limit on model size was identified, suggesting that even larger models are likely to improve on initial results. The dataset and baseline models are both provided as open resources, as well as a public leader board to encourage community contributions to solve these important tasks.
An Introduction to Electrocatalyst Design using Machine Learning for Renewable Energy Storage
Oct 14, 2020
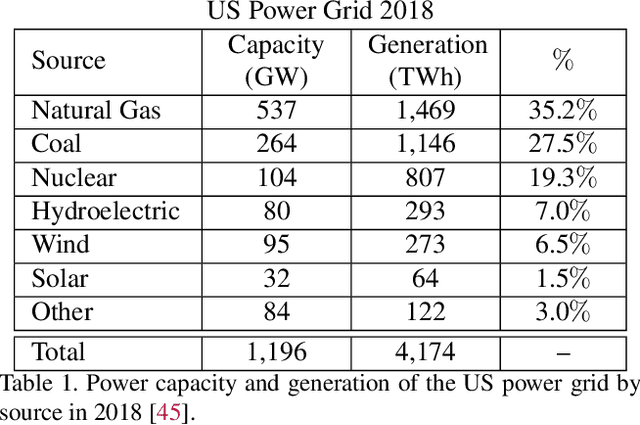
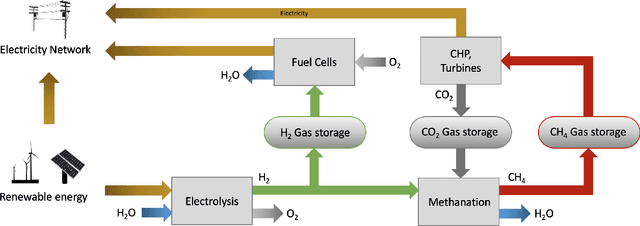
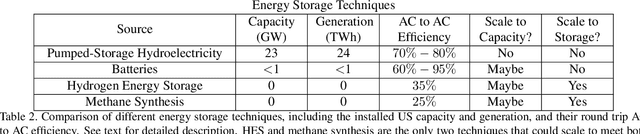
Scalable and cost-effective solutions to renewable energy storage are essential to addressing the world's rising energy needs while reducing climate change. As we increase our reliance on renewable energy sources such as wind and solar, which produce intermittent power, storage is needed to transfer power from times of peak generation to peak demand. This may require the storage of power for hours, days, or months. One solution that offers the potential of scaling to nation-sized grids is the conversion of renewable energy to other fuels, such as hydrogen or methane. To be widely adopted, this process requires cost-effective solutions to running electrochemical reactions. An open challenge is finding low-cost electrocatalysts to drive these reactions at high rates. Through the use of quantum mechanical simulations (density functional theory), new catalyst structures can be tested and evaluated. Unfortunately, the high computational cost of these simulations limits the number of structures that may be tested. The use of machine learning may provide a method to efficiently approximate these calculations, leading to new approaches in finding effective electrocatalysts. In this paper, we provide an introduction to the challenges in finding suitable electrocatalysts, how machine learning may be applied to the problem, and the use of the Open Catalyst Project OC20 dataset for model training.