 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Summarization via Actionness Ranking
Paper and Code
Mar 01, 2019


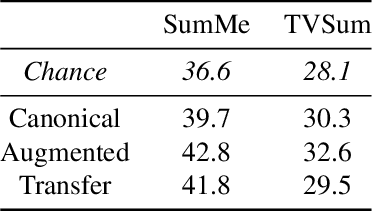
To automatically produce a brief yet expressive summary of a long video, an automatic algorithm should start by resembling the human process of summary generation. Prior work proposed supervised and unsupervised algorithms to train models for learning the underlying behavior of humans by increasing modeling complexity or craft-designing better heuristics to simulate human summary generation process. In this work, we take a different approach by analyzing a major cue that humans exploit for the summary generation; the nature and intensity of actions. We empirically observed that a frame is more likely to be included in human-generated summaries if it contains a substantial amount of deliberate motion performed by an agent, which is referred to as actionness. Therefore, we hypothesize that learning to automatically generate summaries involves an implicit knowledge of actionness estimation and ranking. We validate our hypothesis by running a user study that explores the correlation between human-generated summaries and actionness ranks. We also run a consensus and behavioral analysis between human subjects to ensure reliable and consistent results. The analysis exhibits a considerable degree of agreement among subjects within obtained data and verifying our initial hypothesis. Based on the study findings, we develop a method to incorporate actionness data to explicitly regulate a learning algorithm that is trained for summary generation. We assess the performance of our approach to four summarization benchmark datasets and demonstrate an evident advantage compared to state-of-the-art summarization methods.