 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePindrop it! Audio and Visual Deepfake Countermeasures for Robust Detection and Fine Grained-Localization
Aug 11, 2025The field of visual and audio generation is burgeoning with new state-of-the-art methods. This rapid proliferation of new techniques underscores the need for robust solutions for detecting synthetic content in videos. In particular, when fine-grained alterations via localized manipulations are performed in visual, audio, or both domains, these subtle modifications add challenges to the detection algorithms. This paper presents solutions for the problems of deepfake video classification and localization. The methods were submitted to the ACM 1M Deepfakes Detection Challenge, achieving the best performance in the temporal localization task and a top four ranking in the classification task for the TestA split of the evaluation dataset.
Novel View Video Prediction Using a Dual Representation
Jun 07, 2021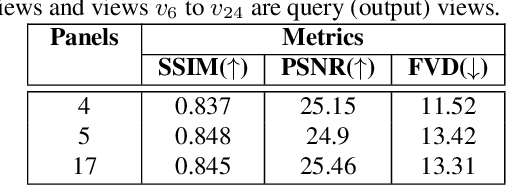
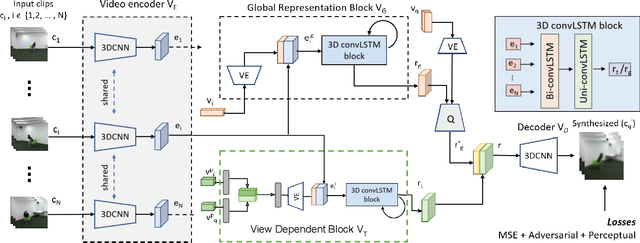
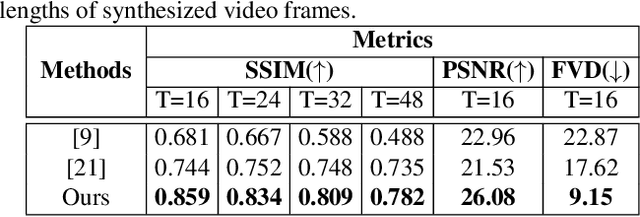

We address the problem of novel view video prediction; given a set of input video clips from a single/multiple views, our network is able to predict the video from a novel view. The proposed approach does not require any priors and is able to predict the video from wider angular distances, upto 45 degree, as compared to the recent studies predicting small variations in viewpoint. Moreover, our method relies only onRGB frames to learn a dual representation which is used to generate the video from a novel viewpoint. The dual representation encompasses a view-dependent and a global representation which incorporates complementary details to enable novel view video prediction. We demonstrate the effectiveness of our framework on two real world datasets: NTU-RGB+D and CMU Panoptic. A comparison with the State-of-the-art novel view video prediction methods shows an improvement of 26.1% in SSIM, 13.6% in PSNR, and 60% inFVD scores without using explicit priors from target views.
Bridging the Domain Gap for Ground-to-Aerial Image Matching
Apr 24, 2019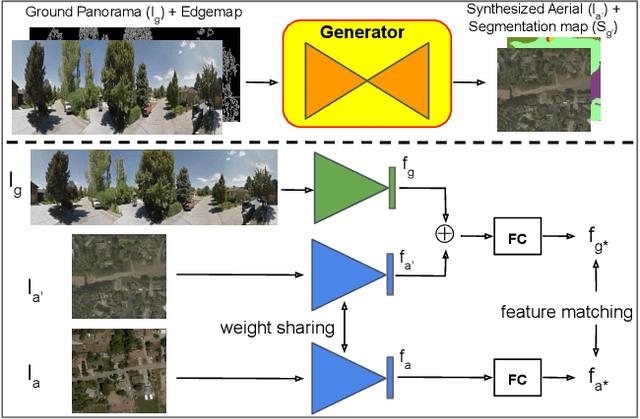
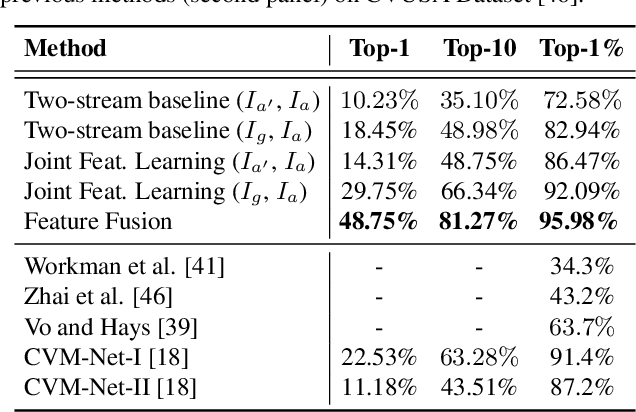
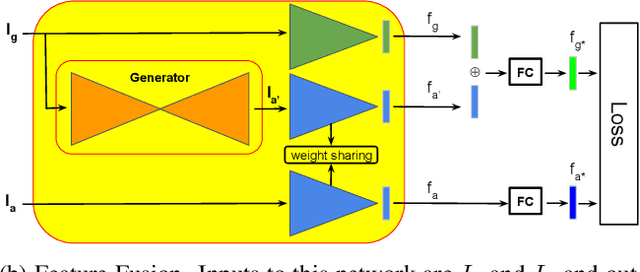
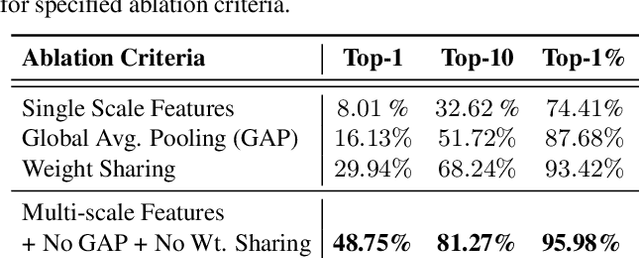
The visual entities in cross-view images exhibit drastic domain changes due to the difference in viewpoints each set of images is captured from. Existing state-of-the-art methods address the problem by learning view-invariant descriptors for the images. We propose a novel method for solving this task by exploiting the generative powers of conditional GANs to synthesize an aerial representation of a ground level panorama and use it to minimize the domain gap between the two views. The synthesized image being from the same view as the target image helps the network to preserve important cues in aerial images following our Joint Feature Learning approach. Our Feature Fusion method combines the complementary features from a synthesized aerial image with the corresponding ground features to obtain a robust query representation. In addition, multi-scale feature aggregation preserves image representations at different feature scales useful for solving this complex task. Experimental results show that our proposed approach performs significantly better than the state-of-the-art methods on the challenging CVUSA dataset in terms of top-1 and top-1% retrieval accuracies. Furthermore, to evaluate the generalization of our method on urban landscapes, we collected a new cross-view localization dataset with geo-reference information.
From Third Person to First Person: Dataset and Baselines for Synthesis and Retrieval
Dec 01, 2018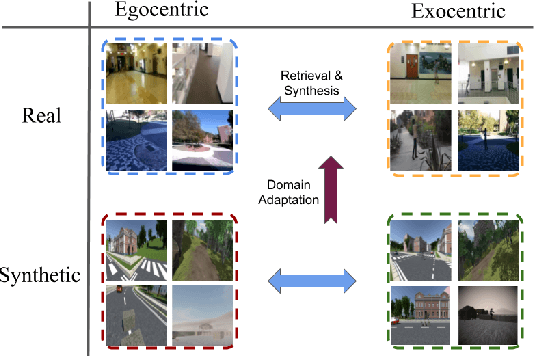



First-person (egocentric) and third person (exocentric) videos are drastically different in nature. The relationship between these two views have been studied in recent years, however, it has yet to be fully explored. In this work, we introduce two datasets (synthetic and natural/real) containing simultaneously recorded egocentric and exocentric videos. We also explore relating the two domains (egocentric and exocentric) in two aspects. First, we synthesize images in the egocentric domain from the exocentric domain using a conditional generative adversarial network (cGAN). We show that with enough training data, our network is capable of hallucinating how the world would look like from an egocentric perspective, given an exocentric video. Second, we address the cross-view retrieval problem across the two views. Given an egocentric query frame (or its momentary optical flow), we retrieve its corresponding exocentric frame (or optical flow) from a gallery set. We show that using synthetic data could be beneficial in retrieving real data. We show that performing domain adaptation from the synthetic domain to the natural/real domain, is helpful in tasks such as retrieval. We believe that the presented datasets and the proposed baselines offer new opportunities for further research in this direction. The code and dataset are publicly available.
Cross-view image synthesis using geometry-guided conditional GANs
Aug 14, 2018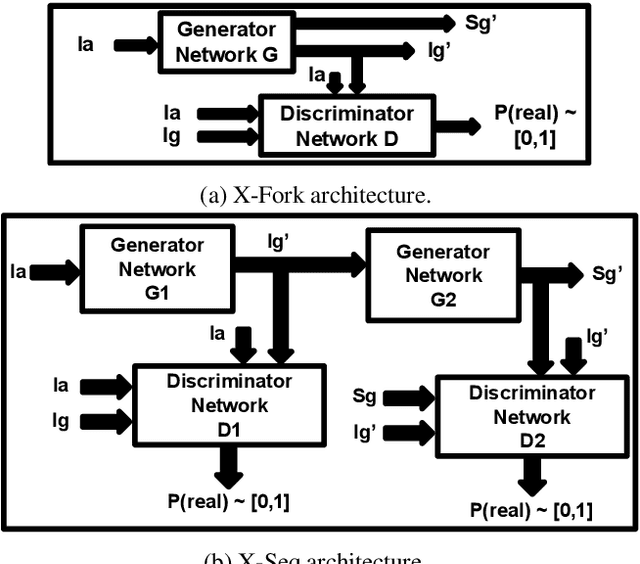

We address the problem of generating images across two drastically different views, namely ground (street) and aerial (overhead) views. Image synthesis by itself is a very challenging computer vision task and is even more so when generation is conditioned on an image in another view. Due the difference in viewpoints, there is small overlapping field of view and little common content between these two views. Here, we try to preserve the pixel information between the views so that the generated image is a realistic representation of cross view input image. For this, we propose to use homography as a guide to map the images between the views based on the common field of view to preserve the details in the input image. We then use generative adversarial networks to inpaint the missing regions in the transformed image and add realism to it. Our exhaustive evaluation and model comparison demonstrate that utilizing geometry constraints adds fine details to the generated images and can be a better approach for cross view image synthesis than purely pixel based synthesis methods.
Cross-View Image Synthesis using Conditional GANs
Mar 29, 2018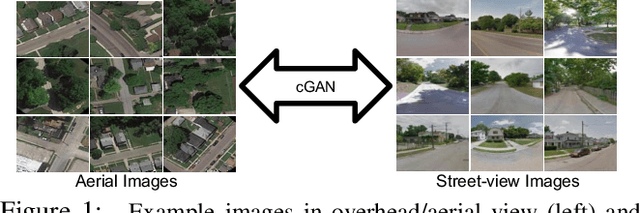
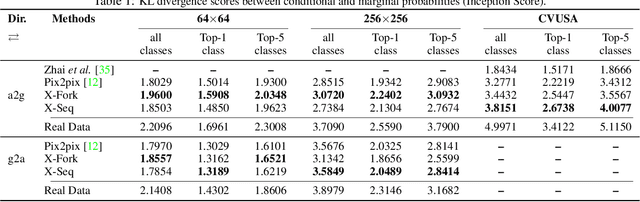
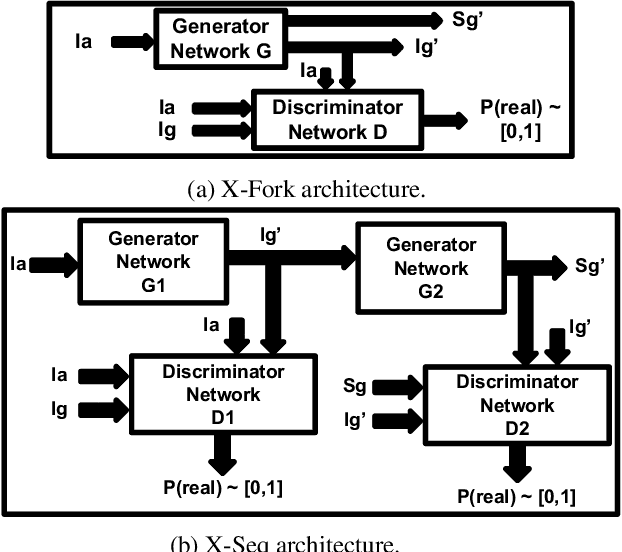
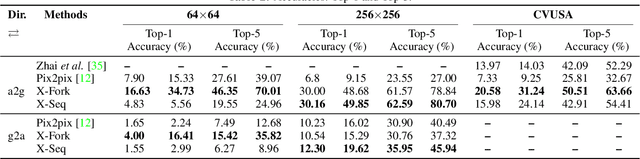
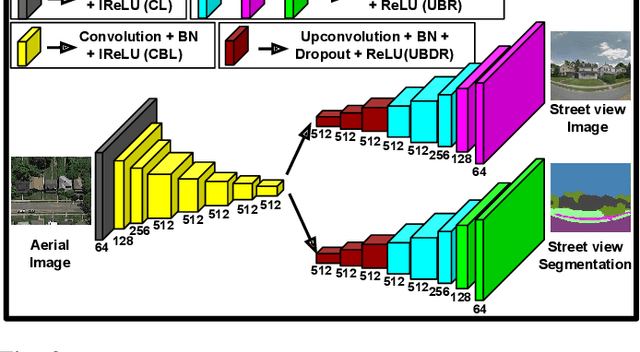
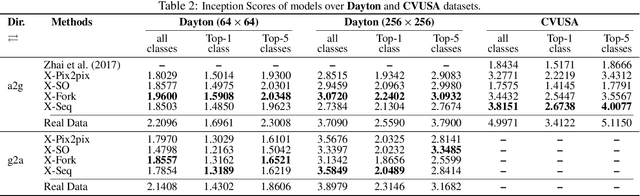
Learning to generate natural scenes has always been a challenging task in computer vision. It is even more painstaking when the generation is conditioned on images with drastically different views. This is mainly because understanding, corresponding, and transforming appearance and semantic information across the views is not trivial. In this paper, we attempt to solve the novel problem of cross-view image synthesis, aerial to street-view and vice versa, using conditional generative adversarial networks (cGAN). Two new architectures called Crossview Fork (X-Fork) and Crossview Sequential (X-Seq) are proposed to generate scenes with resolutions of 64x64 and 256x256 pixels. X-Fork architecture has a single discriminator and a single generator. The generator hallucinates both the image and its semantic segmentation in the target view. X-Seq architecture utilizes two cGANs. The first one generates the target image which is subsequently fed to the second cGAN for generating its corresponding semantic segmentation map. The feedback from the second cGAN helps the first cGAN generate sharper images. Both of our proposed architectures learn to generate natural images as well as their semantic segmentation maps. The proposed methods show that they are able to capture and maintain the true semantics of objects in source and target views better than the traditional image-to-image translation method which considers only the visual appearance of the scene. Extensive qualitative and quantitative evaluations support the effectiveness of our frameworks, compared to two state of the art methods, for natural scene generation across drastically different views.
EgoTransfer: Transferring Motion Across Egocentric and Exocentric Domains using Deep Neural Networks
Dec 17, 2016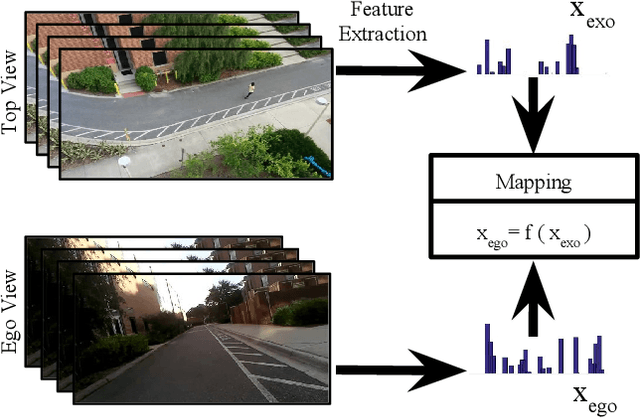

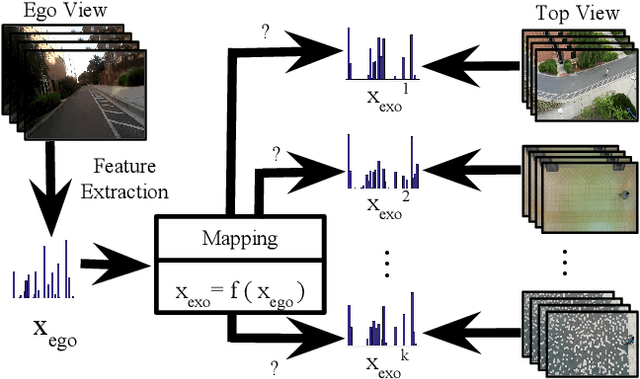

Mirror neurons have been observed in the primary motor cortex of primate species, in particular in humans and monkeys. A mirror neuron fires when a person performs a certain action, and also when he observes the same action being performed by another person. A crucial step towards building fully autonomous intelligent systems with human-like learning abilities is the capability in modeling the mirror neuron. On one hand, the abundance of egocentric cameras in the past few years has offered the opportunity to study a lot of vision problems from the first-person perspective. A great deal of interesting research has been done during the past few years, trying to explore various computer vision tasks from the perspective of the self. On the other hand, videos recorded by traditional static cameras, capture humans performing different actions from an exocentric third-person perspective. In this work, we take the first step towards relating motion information across these two perspectives. We train models that predict motion in an egocentric view, by observing it from an exocentric view, and vice versa. This allows models to predict how an egocentric motion would look like from outside. To do so, we train linear and nonlinear models and evaluate their performance in terms of retrieving the egocentric (exocentric) motion features, while having access to an exocentric (egocentric) motion feature. Our experimental results demonstrate that motion information can be successfully transferred across the two views.