 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Video Prediction Using a Dual Representation
Jun 07, 2021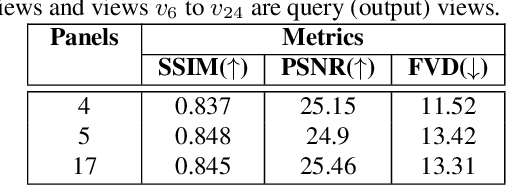
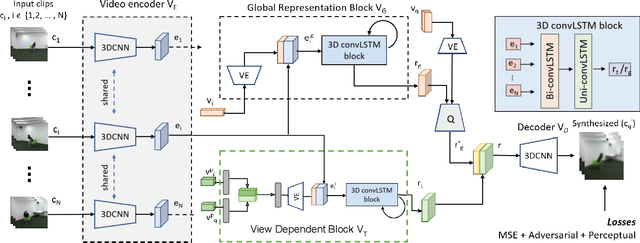
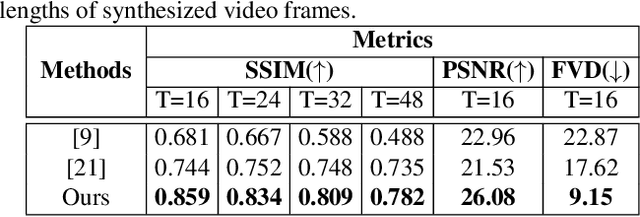

We address the problem of novel view video prediction; given a set of input video clips from a single/multiple views, our network is able to predict the video from a novel view. The proposed approach does not require any priors and is able to predict the video from wider angular distances, upto 45 degree, as compared to the recent studies predicting small variations in viewpoint. Moreover, our method relies only onRGB frames to learn a dual representation which is used to generate the video from a novel viewpoint. The dual representation encompasses a view-dependent and a global representation which incorporates complementary details to enable novel view video prediction. We demonstrate the effectiveness of our framework on two real world datasets: NTU-RGB+D and CMU Panoptic. A comparison with the State-of-the-art novel view video prediction methods shows an improvement of 26.1% in SSIM, 13.6% in PSNR, and 60% inFVD scores without using explicit priors from target views.