 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Domain Gap for Ground-to-Aerial Image Matching
Paper and Code
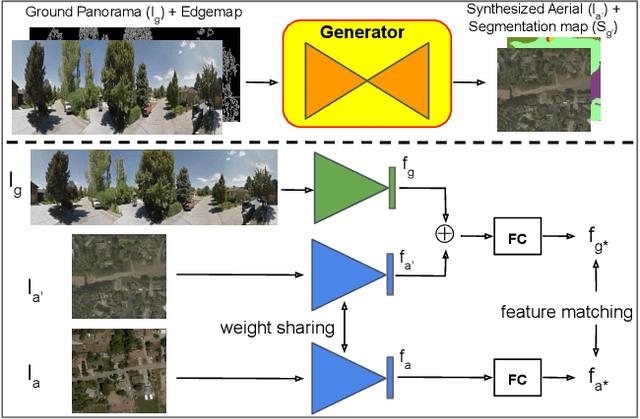
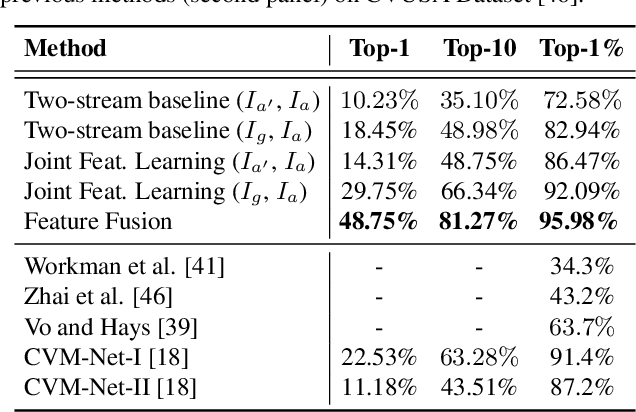
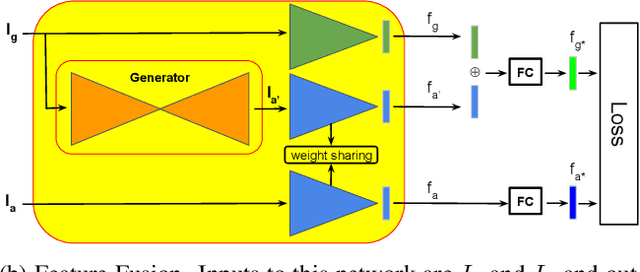
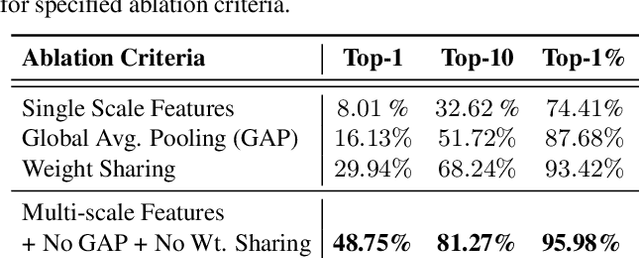
The visual entities in cross-view images exhibit drastic domain changes due to the difference in viewpoints each set of images is captured from. Existing state-of-the-art methods address the problem by learning view-invariant descriptors for the images. We propose a novel method for solving this task by exploiting the generative powers of conditional GANs to synthesize an aerial representation of a ground level panorama and use it to minimize the domain gap between the two views. The synthesized image being from the same view as the target image helps the network to preserve important cues in aerial images following our Joint Feature Learning approach. Our Feature Fusion method combines the complementary features from a synthesized aerial image with the corresponding ground features to obtain a robust query representation. In addition, multi-scale feature aggregation preserves image representations at different feature scales useful for solving this complex task. Experimental results show that our proposed approach performs significantly better than the state-of-the-art methods on the challenging CVUSA dataset in terms of top-1 and top-1% retrieval accuracies. Furthermore, to evaluate the generalization of our method on urban landscapes, we collected a new cross-view localization dataset with geo-reference information.