 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Synopsis Generation for Egocentric Videos
Paper and Code
May 08, 2020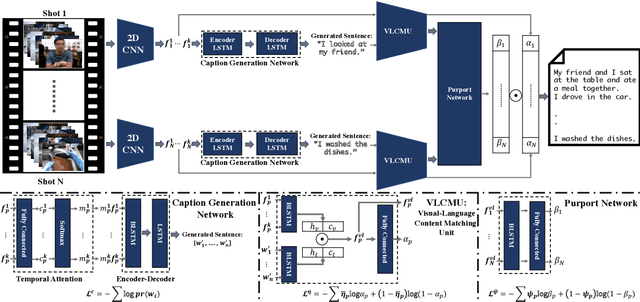
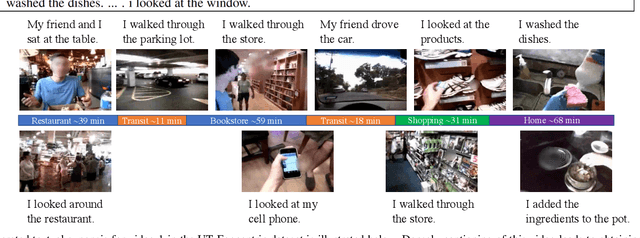


Mass utilization of body-worn cameras has led to a huge corpus of available egocentric video. Existing video summarization algorithms can accelerate browsing such videos by selecting (visually) interesting shots from them. Nonetheless, since the system user still has to watch the summary videos, browsing large video databases remain a challenge. Hence, in this work, we propose to generate a textual synopsis, consisting of a few sentences describing the most important events in a long egocentric videos. Users can read the short text to gain insight about the video, and more importantly, efficiently search through the content of a large video database using text queries. Since egocentric videos are long and contain many activities and events, using video-to-text algorithms results in thousands of descriptions, many of which are incorrect. Therefore, we propose a multi-task learning scheme to simultaneously generate descriptions for video segments and summarize the resulting descriptions in an end-to-end fashion. We Input a set of video shots and the network generates a text description for each shot. Next, visual-language content matching unit that is trained with a weakly supervised objective, identifies the correct descriptions. Finally, the last component of our network, called purport network, evaluates the descriptions all together to select the ones containing crucial information. Out of thousands of descriptions generated for the video, a few informative sentences are returned to the user. We validate our framework on the challenging UT Egocentric video dataset, where each video is between 3 to 5 hours long, associated with over 3000 textual descriptions on average. The generated textual summaries, including only 5 percent (or less) of the generated descriptions, are compared to groundtruth summaries in text domain using well-established metrics in natural language processing.