 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Visual Recognition Using Knowledge Graphs
Aug 28, 2017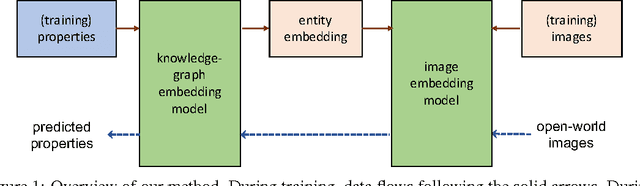
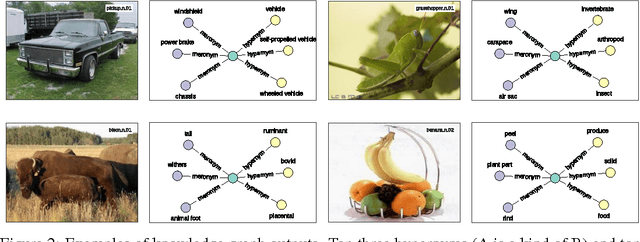
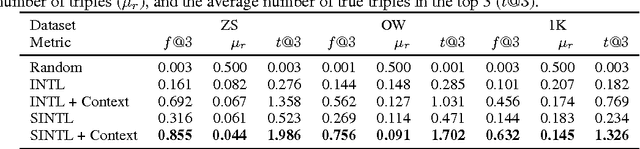
In a real-world setting, visual recognition systems can be brought to make predictions for images belonging to previously unknown class labels. In order to make semantically meaningful predictions for such inputs, we propose a two-step approach that utilizes information from knowledge graphs. First, a knowledge-graph representation is learned to embed a large set of entities into a semantic space. Second, an image representation is learned to embed images into the same space. Under this setup, we are able to predict structured properties in the form of relationship triples for any open-world image. This is true even when a set of labels has been omitted from the training protocols of both the knowledge graph and image embeddings. Furthermore, we append this learning framework with appropriate smoothness constraints and show how prior knowledge can be incorporated into the model. Both these improvements combined increase performance for visual recognition by a factor of six compared to our baseline. Finally, we propose a new, extended dataset which we use for experiments.