 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Framework for Learning Subgraph and Graph Similarity Measures
Dec 28, 2021
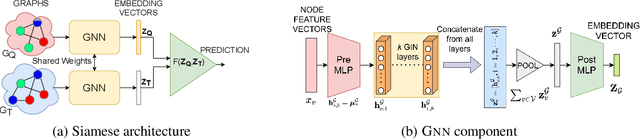
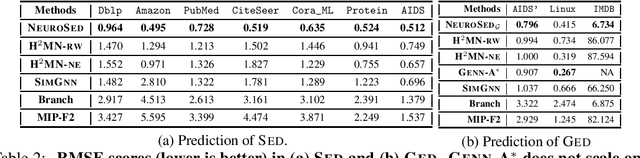
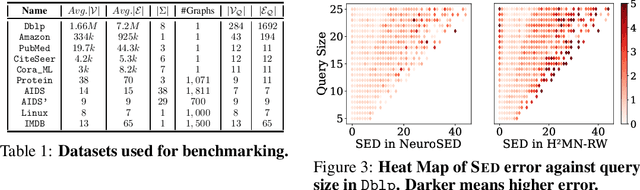
Subgraph similarity search is a fundamental operator in graph analysis. In this framework, given a query graph and a graph database, the goal is to identify subgraphs of the database graphs that are structurally similar to the query. Subgraph edit distance (SED) is one of the most expressive measures for subgraph similarity. In this work, we study the problem of learning SED from a training set of graph pairs and their SED values. Towards that end, we design a novel siamese graph neural network called NEUROSED, which learns an embedding space with a rich structure reminiscent of SED. With the help of a specially crafted inductive bias, NEUROSED not only enables high accuracy but also ensures that the predicted SED, like true SED, satisfies triangle inequality. The design is generic enough to also model graph edit distance (GED), while ensuring that the predicted GED space is metric, like the true GED space. Extensive experiments on real graph datasets, for both SED and GED, establish that NEUROSED achieves approximately 2 times lower RMSE than the state of the art and is approximately 18 times faster than the fastest baseline. Further, owing to its pair-independent embeddings and theoretical properties, NEUROSED allows approximately 3 orders of magnitude faster retrieval of graphs and subgraphs.
Efficient Scaling of Dynamic Graph Neural Networks
Sep 16, 2021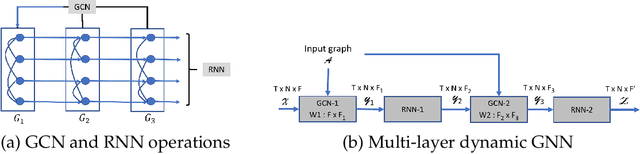
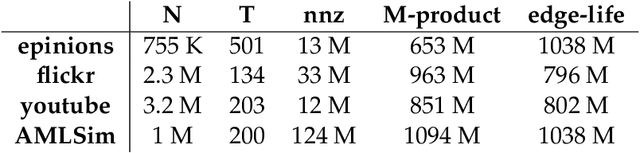
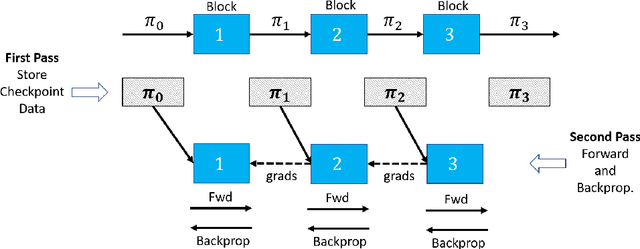
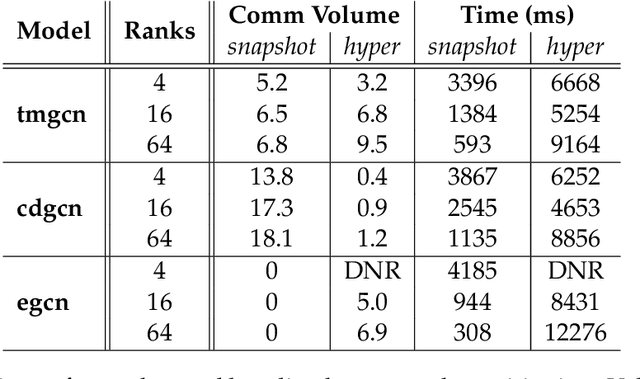
We present distributed algorithms for training dynamic Graph Neural Networks (GNN) on large scale graphs spanning multi-node, multi-GPU systems. To the best of our knowledge, this is the first scaling study on dynamic GNN. We devise mechanisms for reducing the GPU memory usage and identify two execution time bottlenecks: CPU-GPU data transfer; and communication volume. Exploiting properties of dynamic graphs, we design a graph difference-based strategy to significantly reduce the transfer time. We develop a simple, but effective data distribution technique under which the communication volume remains fixed and linear in the input size, for any number of GPUs. Our experiments using billion-size graphs on a system of 128 GPUs shows that: (i) the distribution scheme achieves up to 30x speedup on 128 GPUs; (ii) the graph-difference technique reduces the transfer time by a factor of up to 4.1x and the overall execution time by up to 40%
Effective Elastic Scaling of Deep Learning Workloads
Jun 24, 2020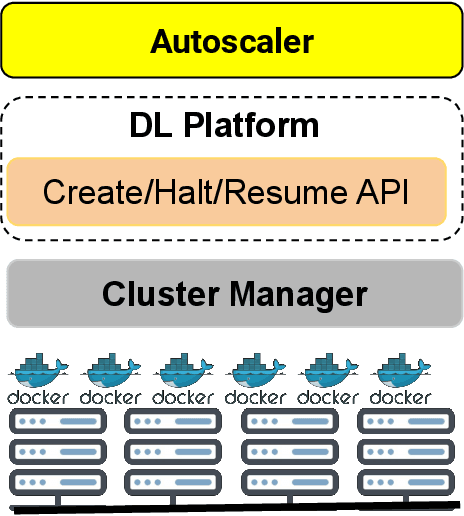
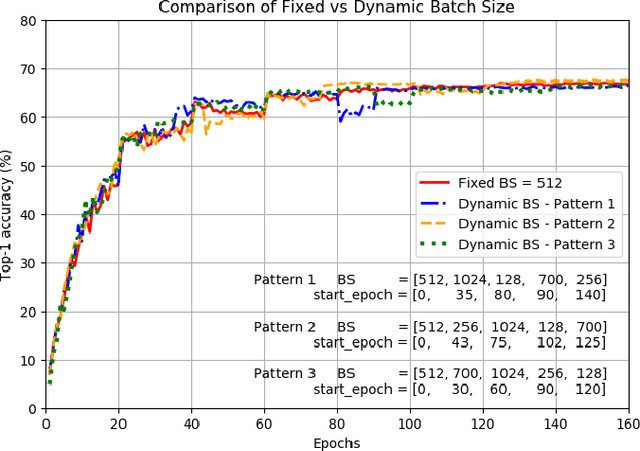
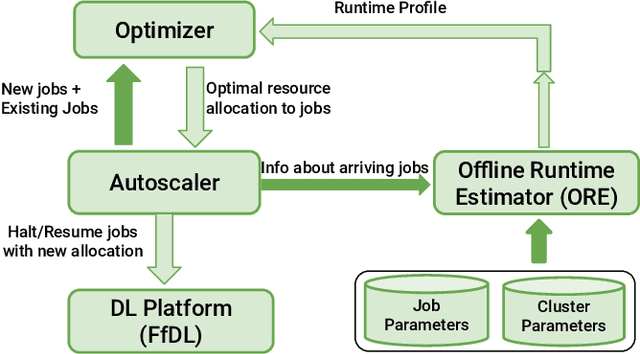

The increased use of deep learning (DL) in academia, government and industry has, in turn, led to the popularity of on-premise and cloud-hosted deep learning platforms, whose goals are to enable organizations utilize expensive resources effectively, and to share said resources among multiple teams in a fair and effective manner. In this paper, we examine the elastic scaling of Deep Learning (DL) jobs over large-scale training platforms and propose a novel resource allocation strategy for DL training jobs, resulting in improved job run time performance as well as increased cluster utilization. We begin by analyzing DL workloads and exploit the fact that DL jobs can be run with a range of batch sizes without affecting their final accuracy. We formulate an optimization problem that explores a dynamic batch size allocation to individual DL jobs based on their scaling efficiency, when running on multiple nodes. We design a fast dynamic programming based optimizer to solve this problem in real-time to determine jobs that can be scaled up/down, and use this optimizer in an autoscaler to dynamically change the allocated resources and batch sizes of individual DL jobs. We demonstrate empirically that our elastic scaling algorithm can complete up to $\approx 2 \times$ as many jobs as compared to a strong baseline algorithm that also scales the number of GPUs but does not change the batch size. We also demonstrate that the average completion time with our algorithm is up to $\approx 10 \times$ faster than that of the baseline.
PoWER-BERT: Accelerating BERT inference for Classification Tasks
Jan 24, 2020
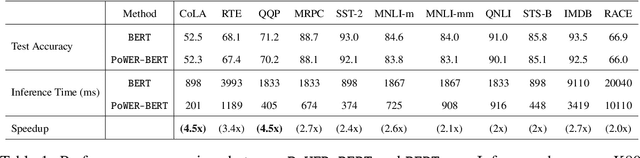
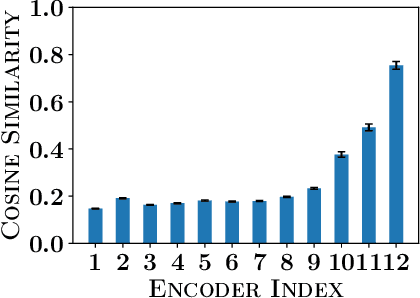
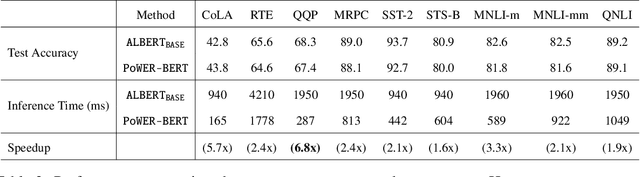
BERT has emerged as a popular model for natural language understanding. Given its compute intensive nature, even for inference, many recent studies have considered optimization of two important performance characteristics: model size and inference time. We consider classification tasks and propose a novel method, called PoWER-BERT, for improving the inference time for the BERT model without significant loss in the accuracy. The method works by eliminating word-vectors (intermediate vector outputs) from the encoder pipeline. We design a strategy for measuring the significance of the word-vectors based on the self-attention mechanism of the encoders which helps us identify the word-vectors to be eliminated. Experimental evaluation on the standard GLUE benchmark shows that PoWER-BERT achieves up to 4.5x reduction in inference time over BERT with < 1% loss in accuracy. We show that compared to the prior inference time reduction methods, PoWER-BERT offers better trade-off between accuracy and inference time. Lastly, we demonstrate that our scheme can also be used in conjunction with ALBERT (a highly compressed version of BERT) and can attain up to 6.8x factor reduction in inference time with < 1% loss in accuracy.
Efficient Inferencing of Compressed Deep Neural Networks
Nov 01, 2017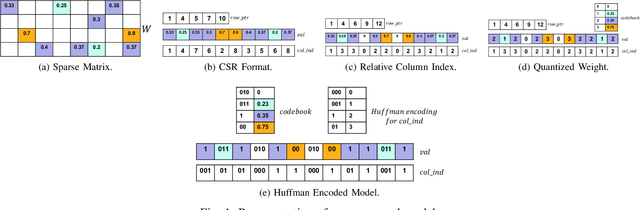
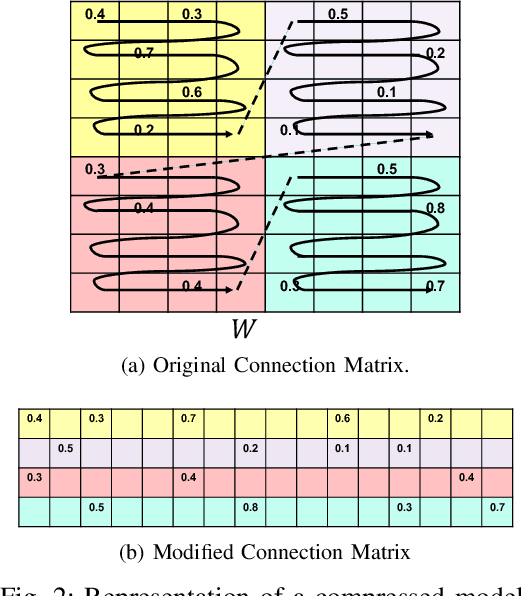
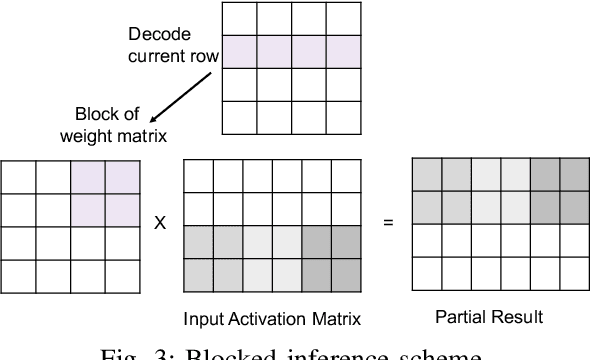
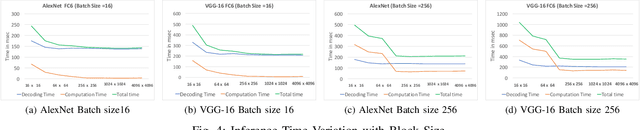
Large number of weights in deep neural networks makes the models difficult to be deployed in low memory environments such as, mobile phones, IOT edge devices as well as "inferencing as a service" environments on cloud. Prior work has considered reduction in the size of the models, through compression techniques like pruning, quantization, Huffman encoding etc. However, efficient inferencing using the compressed models has received little attention, specially with the Huffman encoding in place. In this paper, we propose efficient parallel algorithms for inferencing of single image and batches, under various memory constraints. Our experimental results show that our approach of using variable batch size for inferencing achieves 15-25\% performance improvement in the inference throughput for AlexNet, while maintaining memory and latency constraints.