 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUTOSPARSE: Towards Automated Sparse Training of Deep Neural Networks
Apr 14, 2023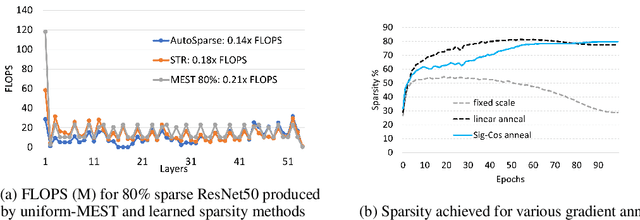
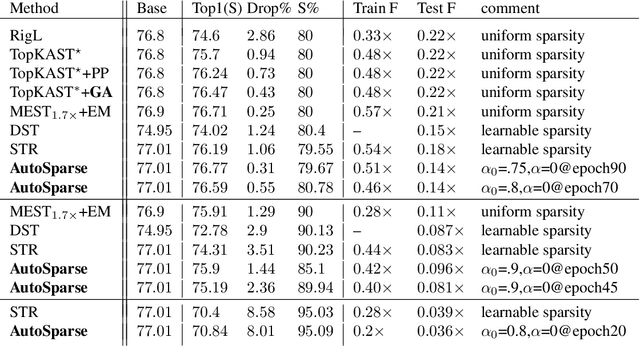

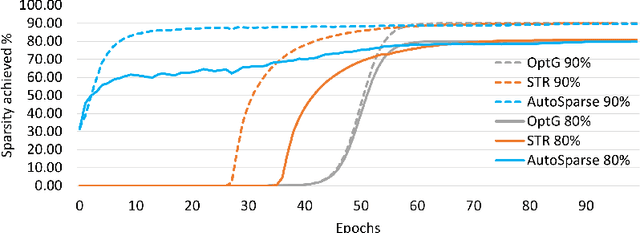
Sparse training is emerging as a promising avenue for reducing the computational cost of training neural networks. Several recent studies have proposed pruning methods using learnable thresholds to efficiently explore the non-uniform distribution of sparsity inherent within the models. In this paper, we propose Gradient Annealing (GA), where gradients of masked weights are scaled down in a non-linear manner. GA provides an elegant trade-off between sparsity and accuracy without the need for additional sparsity-inducing regularization. We integrated GA with the latest learnable pruning methods to create an automated sparse training algorithm called AutoSparse, which achieves better accuracy and/or training/inference FLOPS reduction than existing learnable pruning methods for sparse ResNet50 and MobileNetV1 on ImageNet-1K: AutoSparse achieves (2x, 7x) reduction in (training,inference) FLOPS for ResNet50 on ImageNet at 80% sparsity. Finally, AutoSparse outperforms sparse-to-sparse SotA method MEST (uniform sparsity) for 80% sparse ResNet50 with similar accuracy, where MEST uses 12% more training FLOPS and 50% more inference FLOPS.
Ramanujan Bipartite Graph Products for Efficient Block Sparse Neural Networks
Jul 02, 2020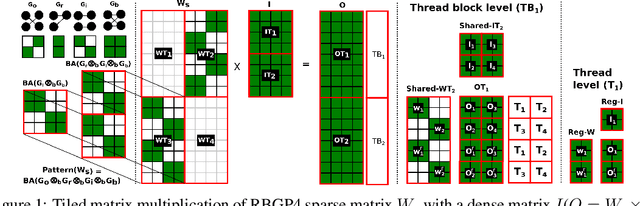
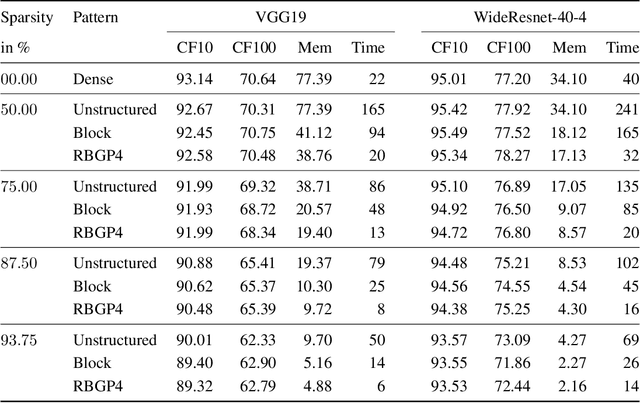
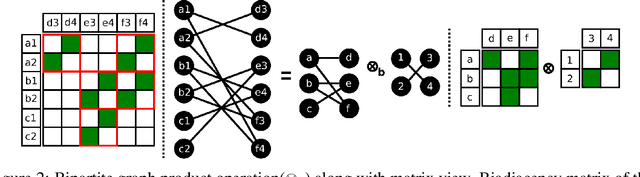
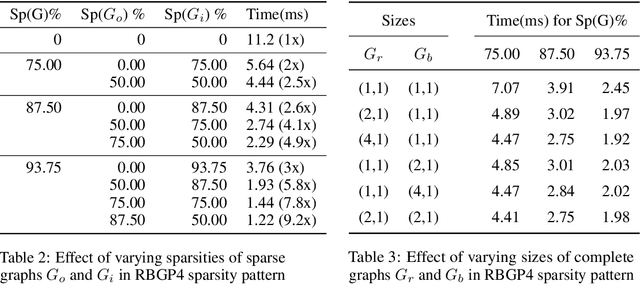
Sparse neural networks are shown to give accurate predictions competitive to denser versions, while also minimizing the number of arithmetic operations performed. However current hardware like GPU's can only exploit structured sparsity patterns for better efficiency. Hence the run time of a sparse neural network may not correspond to the arithmetic operations required. In this work, we propose RBGP( Ramanujan Bipartite Graph Product) framework for generating structured multi level block sparse neural networks by using the theory of Graph products. We also propose to use products of Ramanujan graphs which gives the best connectivity for a given level of sparsity. This essentially ensures that the i.) the networks has the structured block sparsity for which runtime efficient algorithms exists ii.) the model gives high prediction accuracy, due to the better expressive power derived from the connectivity of the graph iii.) the graph data structure has a succinct representation that can be stored efficiently in memory. We use our framework to design a specific connectivity pattern called RBGP4 which makes efficient use of the memory hierarchy available on GPU. We benchmark our approach by experimenting on image classification task over CIFAR dataset using VGG19 and WideResnet-40-4 networks and achieve 5-9x and 2-5x runtime gains over unstructured and block sparsity patterns respectively, while achieving the same level of accuracy.
A Study of BFLOAT16 for Deep Learning Training
Jun 13, 2019

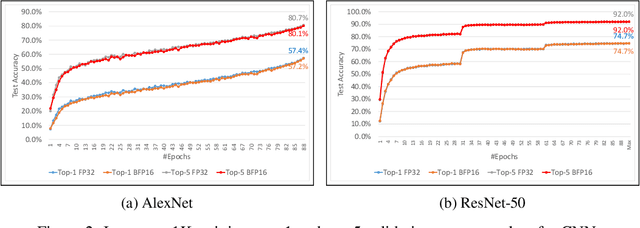

This paper presents the first comprehensive empirical study demonstrating the efficacy of the Brain Floating Point (BFLOAT16) half-precision format for Deep Learning training across image classification, speech recognition, language modeling, generative networks and industrial recommendation systems. BFLOAT16 is attractive for Deep Learning training for two reasons: the range of values it can represent is the same as that of IEEE 754 floating-point format (FP32) and conversion to/from FP32 is simple. Maintaining the same range as FP32 is important to ensure that no hyper-parameter tuning is required for convergence; e.g., IEEE 754 compliant half-precision floating point (FP16) requires hyper-parameter tuning. In this paper, we discuss the flow of tensors and various key operations in mixed precision training, and delve into details of operations, such as the rounding modes for converting FP32 tensors to BFLOAT16. We have implemented a method to emulate BFLOAT16 operations in Tensorflow, Caffe2, IntelCaffe, and Neon for our experiments. Our results show that deep learning training using BFLOAT16 tensors achieves the same state-of-the-art (SOTA) results across domains as FP32 tensors in the same number of iterations and with no changes to hyper-parameters.
Hierarchical Block Sparse Neural Networks
Aug 10, 2018

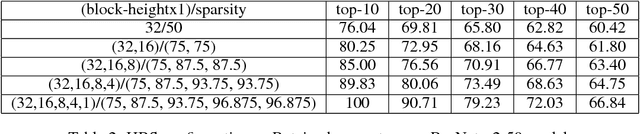
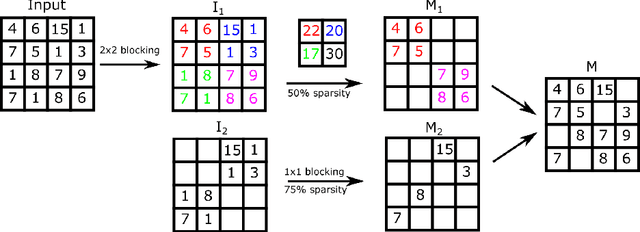
Sparse deep neural networks(DNNs) are efficient in both memory and compute when compared to dense DNNs. But due to irregularity in computation of sparse DNNs, their efficiencies are much lower than that of dense DNNs on general purpose hardwares. This leads to poor/no performance benefits for sparse DNNs. Performance issue for sparse DNNs can be alleviated by bringing structure to the sparsity and leveraging it for improving runtime efficiency. But such structural constraints often lead to sparse models with suboptimal accuracies. In this work, we jointly address both accuracy and performance of sparse DNNs using our proposed class of neural networks called HBsNN ( Hierarchical Block Sparse Neural Networks).
Efficient Inferencing of Compressed Deep Neural Networks
Nov 01, 2017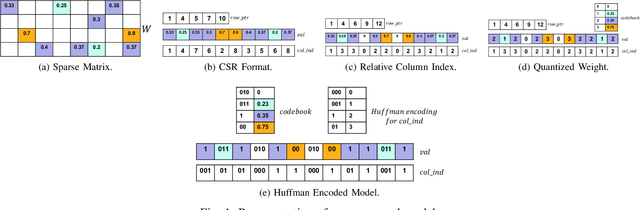
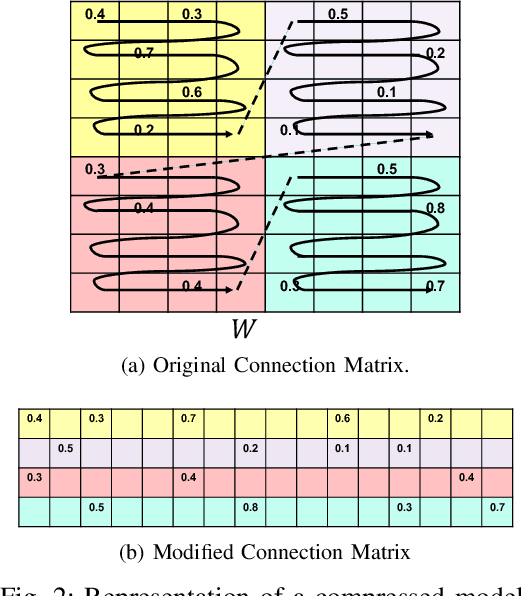
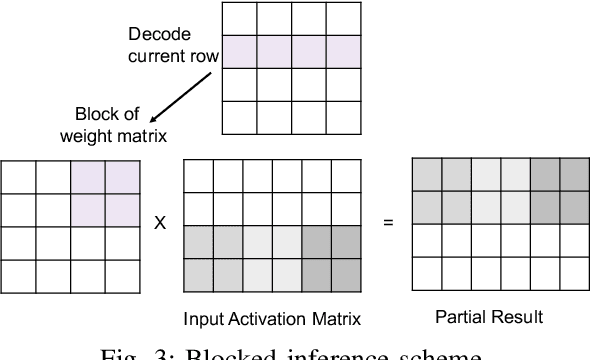
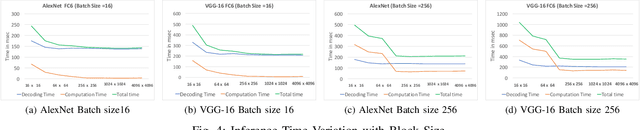
Large number of weights in deep neural networks makes the models difficult to be deployed in low memory environments such as, mobile phones, IOT edge devices as well as "inferencing as a service" environments on cloud. Prior work has considered reduction in the size of the models, through compression techniques like pruning, quantization, Huffman encoding etc. However, efficient inferencing using the compressed models has received little attention, specially with the Huffman encoding in place. In this paper, we propose efficient parallel algorithms for inferencing of single image and batches, under various memory constraints. Our experimental results show that our approach of using variable batch size for inferencing achieves 15-25\% performance improvement in the inference throughput for AlexNet, while maintaining memory and latency constraints.