 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLoRA: Single-shot Hyper-parameter Optimization for Federated Learning
Paper and Code
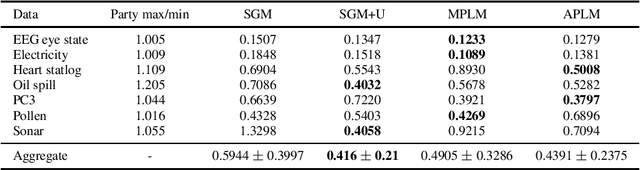
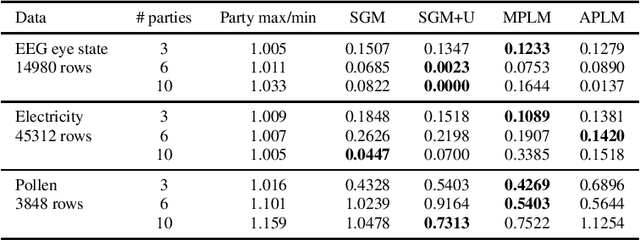

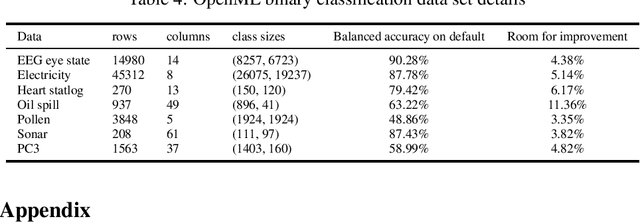
We address the relatively unexplored problem of hyper-parameter optimization (HPO) for federated learning (FL-HPO). We introduce Federated Loss suRface Aggregation (FLoRA), the first FL-HPO solution framework that can address use cases of tabular data and gradient boosting training algorithms in addition to stochastic gradient descent/neural networks commonly addressed in the FL literature. The framework enables single-shot FL-HPO, by first identifying a good set of hyper-parameters that are used in a **single** FL training. Thus, it enables FL-HPO solutions with minimal additional communication overhead compared to FL training without HPO. Our empirical evaluation of FLoRA for Gradient Boosted Decision Trees on seven OpenML data sets demonstrates significant model accuracy improvements over the considered baseline, and robustness to increasing number of parties involved in FL-HPO training.