 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow When To Fold 'Em: Token-Efficient LLM Synthetic Data Generation via Multi-Stage In-Flight Rejection
May 13, 2026While synthetic data generation with large language models (LLMs) is widely used in post-training pipelines, existing approaches typically generate full outputs before applying quality filters, leading to substantial token waste on samples that are ultimately discarded. To address this, we propose Multi-Stage In-Flight Rejection (MSIFR), a lightweight, training-free framework that detects and terminates low-quality generation trajectories at intermediate checkpoints before they reach full completion. MSIFR decomposes the generation process into sequential stages and applies fast rule-based validators to identify arithmetic inconsistencies, hallucination patterns, and formatting violations, enabling early rejection of faulty samples. We formalize in-flight rejection as a sequential decision process and show that any non-trivial discard policy reduces expected token consumption, with stage-wise savings increasing when rejection occurs earlier in the generation pipeline. We further demonstrate that conditional utility estimates form a martingale, ensuring that early, in-flight rejection does not bias the expected utility of retained samples. Across five instruction-tuned models and seven reasoning benchmarks, MSIFR reduces token consumption by 11%-77% as a standalone method, and up to 78.2% when combined with early-exit methods, while preserving or improving evaluation accuracy. These results confirm that MSIFR provides a practical mechanism for improving the efficiency of LLM-based synthetic data generation without additional training or architectural changes.
PEML: Parameter-efficient Multi-Task Learning with Optimized Continuous Prompts
May 13, 2026Parameter-Efficient Fine-Tuning (PEFT) is widely used for adapting Large Language Models (LLMs) for various tasks. Recently, there has been an increasing demand for fine-tuning a single LLM for multiple tasks because it requires overall less data for fine-tuning thanks to the common features shared among tasks. More importantly, LLMs are resource demanding and deploying a single model for multiple tasks facilitates resource consolidation and consumes significantly less resources compared to deploying individual large model for each task. Existing PEFT methods like LoRA and Prefix Tuning are designed to adapt LLMs to a specific task. LoRA and its variation focus on aligning the model itself for tasks, overlooking the importance of prompt tuning in multi-task learning while Prefix Tuning only adopts a simple architecture to optimize prompts, which limits the adaption capabilities for multi-task. To enable efficient fine-tuning for multi-task learning, it is important to co-optimize prompt optimization and model adaptation. In this work, we propose a Parameter-Efficient Multi-task Learning (\PM), which employs a neural architecture engineering method for optimizing the continuous prompts while also performing low-rank adaption for model weights. We prototype PEML by creating an automated framework for optimizing the continuous prompts and adapting model weights. We evaluate PEML against state-of-the-arts multi-task learning methods MTL-LoRA, MultiLoRa, C-Poly, and MoE, on the GLUE, SuperGLUE, Massive Multitask Language Understanding, and commonsense reasoning benchmarks. The evaluation results present an average accuracy improvement of up to 6.67%, with individual tasks showing peak gains of up to 10.75%.
When Data is the Algorithm: A Systematic Study and Curation of Preference Optimization Datasets
Nov 14, 2025Aligning large language models (LLMs) is a central objective of post-training, often achieved through reward modeling and reinforcement learning methods. Among these, direct preference optimization (DPO) has emerged as a widely adopted technique that fine-tunes LLMs on preferred completions over less favorable ones. While most frontier LLMs do not disclose their curated preference pairs, the broader LLM community has released several open-source DPO datasets, including TuluDPO, ORPO, UltraFeedback, HelpSteer, and Code-Preference-Pairs. However, systematic comparisons remain scarce, largely due to the high computational cost and the lack of rich quality annotations, making it difficult to understand how preferences were selected, which task types they span, and how well they reflect human judgment on a per-sample level. In this work, we present the first comprehensive, data-centric analysis of popular open-source DPO corpora. We leverage the Magpie framework to annotate each sample for task category, input quality, and preference reward, a reward-model-based signal that validates the preference order without relying on human annotations. This enables a scalable, fine-grained inspection of preference quality across datasets, revealing structural and qualitative discrepancies in reward margins. Building on these insights, we systematically curate a new DPO mixture, UltraMix, that draws selectively from all five corpora while removing noisy or redundant samples. UltraMix is 30% smaller than the best-performing individual dataset yet exceeds its performance across key benchmarks. We publicly release all annotations, metadata, and our curated mixture to facilitate future research in data-centric preference optimization.
Fixing It in Post: A Comparative Study of LLM Post-Training Data Quality and Model Performance
Jun 06, 2025


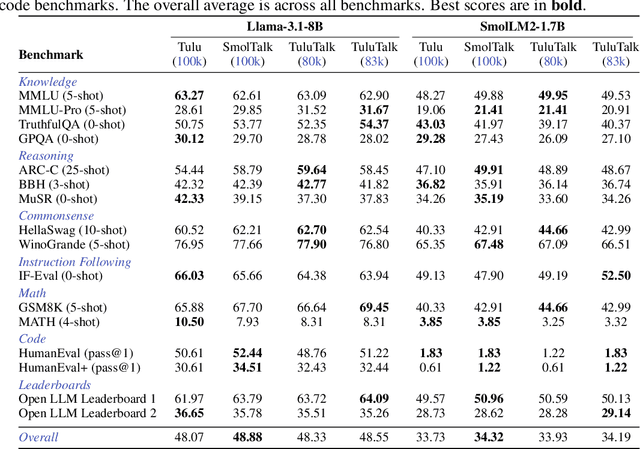
Recent work on large language models (LLMs) has increasingly focused on post-training and alignment with datasets curated to enhance instruction following, world knowledge, and specialized skills. However, most post-training datasets used in leading open- and closed-source LLMs remain inaccessible to the public, with limited information about their construction process. This lack of transparency has motivated the recent development of open-source post-training corpora. While training on these open alternatives can yield performance comparable to that of leading models, systematic comparisons remain challenging due to the significant computational cost of conducting them rigorously at scale, and are therefore largely absent. As a result, it remains unclear how specific samples, task types, or curation strategies influence downstream performance when assessing data quality. In this work, we conduct the first comprehensive side-by-side analysis of two prominent open post-training datasets: Tulu-3-SFT-Mix and SmolTalk. Using the Magpie framework, we annotate each sample with detailed quality metrics, including turn structure (single-turn vs. multi-turn), task category, input quality, and response quality, and we derive statistics that reveal structural and qualitative similarities and differences between the two datasets. Based on these insights, we design a principled curation recipe that produces a new data mixture, TuluTalk, which contains 14% fewer samples than either source dataset while matching or exceeding their performance on key benchmarks. Our findings offer actionable insights for constructing more effective post-training datasets that improve model performance within practical resource limits. To support future research, we publicly release both the annotated source datasets and our curated TuluTalk mixture.
SafeMERGE: Preserving Safety Alignment in Fine-Tuned Large Language Models via Selective Layer-Wise Model Merging
Mar 21, 2025
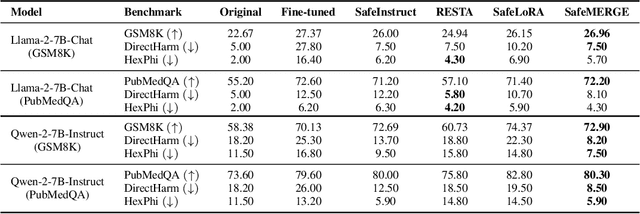
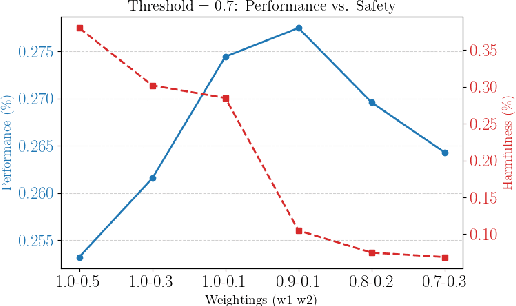
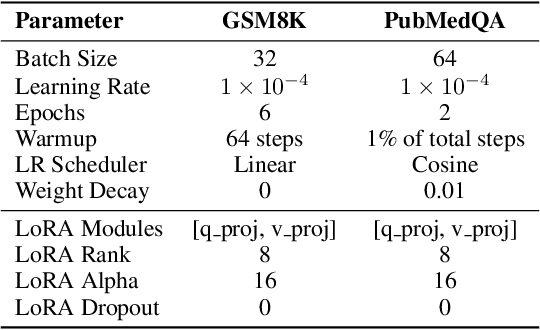
Fine-tuning large language models (LLMs) on downstream tasks can inadvertently erode their safety alignment, even for benign fine-tuning datasets. We address this challenge by proposing SafeMERGE, a post-fine-tuning framework that preserves safety while maintaining task utility. It achieves this by selectively merging fine-tuned and safety-aligned model layers only when those deviate from safe behavior, measured by a cosine similarity criterion. We evaluate SafeMERGE against other fine-tuning- and post-fine-tuning-stage approaches for Llama-2-7B-Chat and Qwen-2-7B-Instruct models on GSM8K and PubMedQA tasks while exploring different merging strategies. We find that SafeMERGE consistently reduces harmful outputs compared to other baselines without significantly sacrificing performance, sometimes even enhancing it. The results suggest that our selective, subspace-guided, and per-layer merging method provides an effective safeguard against the inadvertent loss of safety in fine-tuned LLMs while outperforming simpler post-fine-tuning-stage defenses.
GneissWeb: Preparing High Quality Data for LLMs at Scale
Feb 19, 2025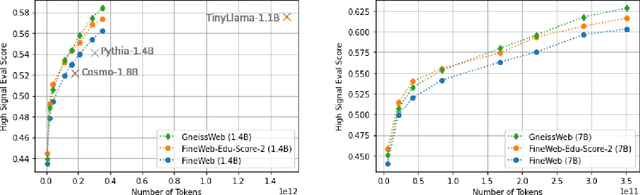
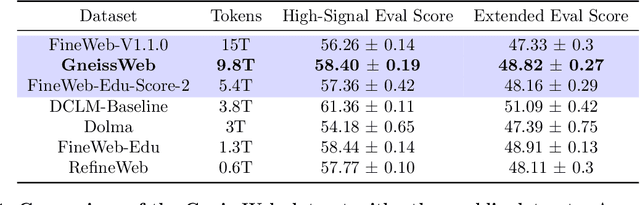
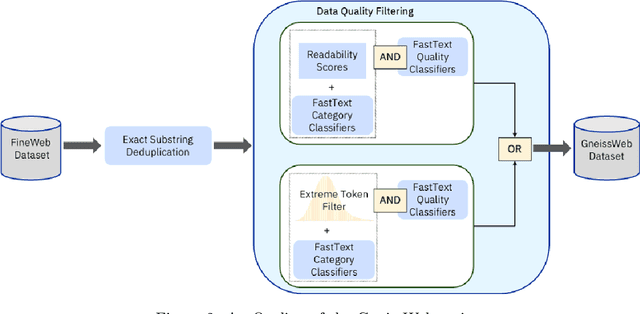

Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Speed Up Federated Learning in Heterogeneous Environment: A Dynamic Tiering Approach
Dec 09, 2023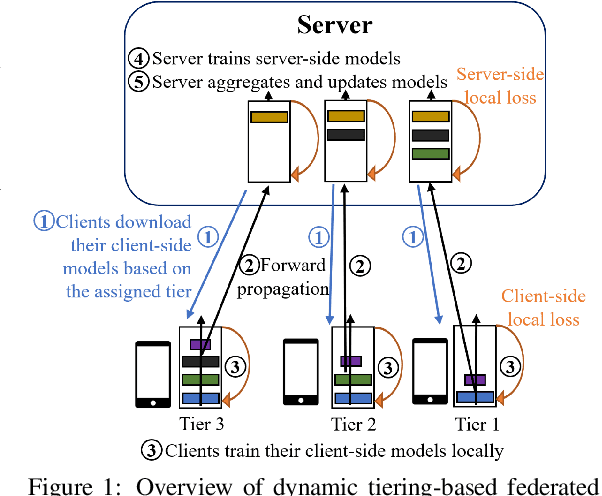
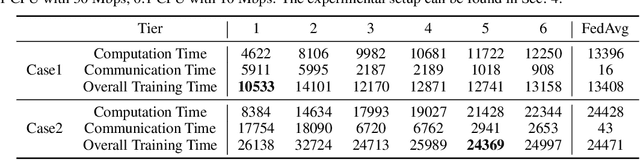

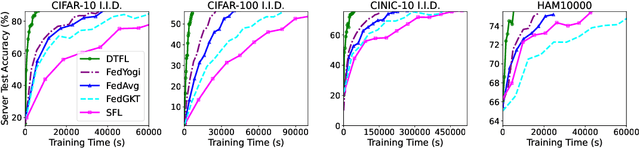
Federated learning (FL) enables collaboratively training a model while keeping the training data decentralized and private. However, one significant impediment to training a model using FL, especially large models, is the resource constraints of devices with heterogeneous computation and communication capacities as well as varying task sizes. Such heterogeneity would render significant variations in the training time of clients, resulting in a longer overall training time as well as a waste of resources in faster clients. To tackle these heterogeneity issues, we propose the Dynamic Tiering-based Federated Learning (DTFL) system where slower clients dynamically offload part of the model to the server to alleviate resource constraints and speed up training. By leveraging the concept of Split Learning, DTFL offloads different portions of the global model to clients in different tiers and enables each client to update the models in parallel via local-loss-based training. This helps reduce the computation and communication demand on resource-constrained devices and thus mitigates the straggler problem. DTFL introduces a dynamic tier scheduler that uses tier profiling to estimate the expected training time of each client, based on their historical training time, communication speed, and dataset size. The dynamic tier scheduler assigns clients to suitable tiers to minimize the overall training time in each round. We first theoretically prove the convergence properties of DTFL. We then train large models (ResNet-56 and ResNet-110) on popular image datasets (CIFAR-10, CIFAR-100, CINIC-10, and HAM10000) under both IID and non-IID systems. Extensive experimental results show that compared with state-of-the-art FL methods, DTFL can significantly reduce the training time while maintaining model accuracy.
SMLT: A Serverless Framework for Scalable and Adaptive Machine Learning Design and Training
May 04, 2022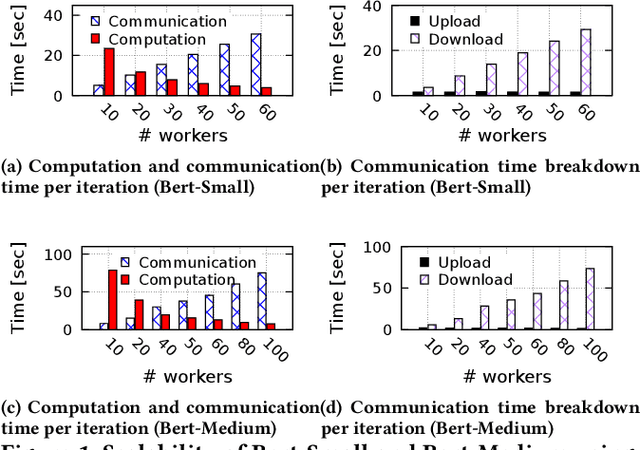

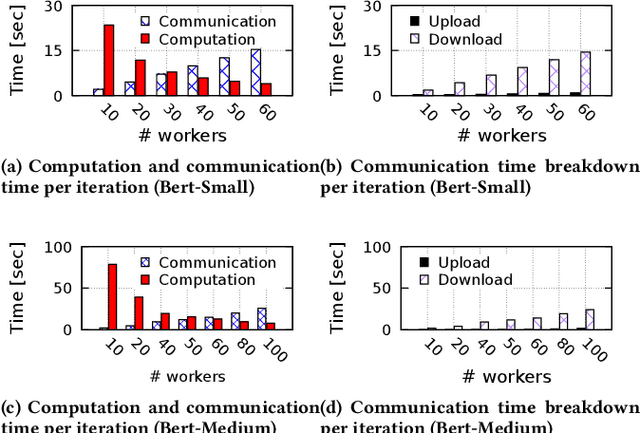
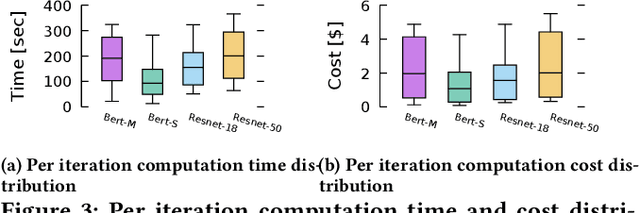
In today's production machine learning (ML) systems, models are continuously trained, improved, and deployed. ML design and training are becoming a continuous workflow of various tasks that have dynamic resource demands. Serverless computing is an emerging cloud paradigm that provides transparent resource management and scaling for users and has the potential to revolutionize the routine of ML design and training. However, hosting modern ML workflows on existing serverless platforms has non-trivial challenges due to their intrinsic design limitations such as stateless nature, limited communication support across function instances, and limited function execution duration. These limitations result in a lack of an overarching view and adaptation mechanism for training dynamics and an amplification of existing problems in ML workflows. To address the above challenges, we propose SMLT, an automated, scalable, and adaptive serverless framework to enable efficient and user-centric ML design and training. SMLT employs an automated and adaptive scheduling mechanism to dynamically optimize the deployment and resource scaling for ML tasks during training. SMLT further enables user-centric ML workflow execution by supporting user-specified training deadlines and budget limits. In addition, by providing an end-to-end design, SMLT solves the intrinsic problems in serverless platforms such as the communication overhead, limited function execution duration, need for repeated initialization, and also provides explicit fault tolerance for ML training. SMLT is open-sourced and compatible with all major ML frameworks. Our experimental evaluation with large, sophisticated modern ML models demonstrate that SMLT outperforms the state-of-the-art VM based systems and existing serverless ML training frameworks in both training speed (up to 8X) and monetary cost (up to 3X)
Curse or Redemption? How Data Heterogeneity Affects the Robustness of Federated Learning
Feb 01, 2021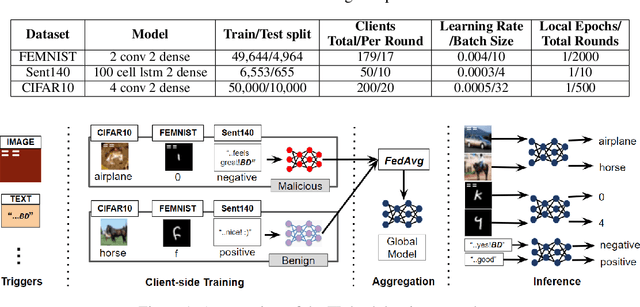
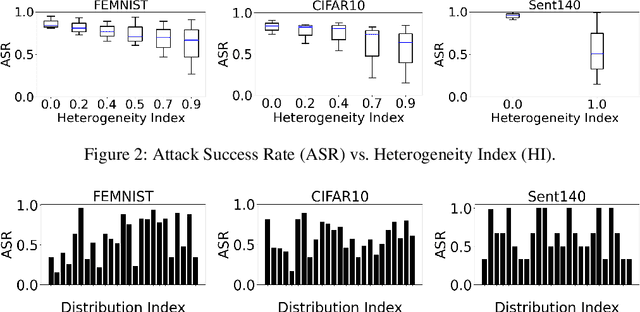
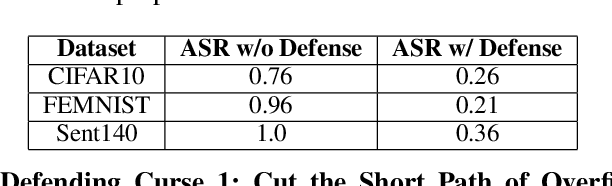
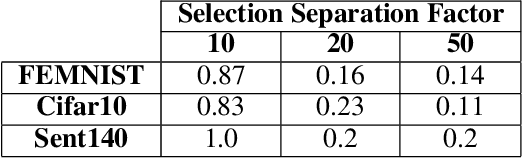
Data heterogeneity has been identified as one of the key features in federated learning but often overlooked in the lens of robustness to adversarial attacks. This paper focuses on characterizing and understanding its impact on backdooring attacks in federated learning through comprehensive experiments using synthetic and the LEAF benchmarks. The initial impression driven by our experimental results suggests that data heterogeneity is the dominant factor in the effectiveness of attacks and it may be a redemption for defending against backdooring as it makes the attack less efficient, more challenging to design effective attack strategies, and the attack result also becomes less predictable. However, with further investigations, we found data heterogeneity is more of a curse than a redemption as the attack effectiveness can be significantly boosted by simply adjusting the client-side backdooring timing. More importantly,data heterogeneity may result in overfitting at the local training of benign clients, which can be utilized by attackers to disguise themselves and fool skewed-feature based defenses. In addition, effective attack strategies can be made by adjusting attack data distribution. Finally, we discuss the potential directions of defending the curses brought by data heterogeneity. The results and lessons learned from our extensive experiments and analysis offer new insights for designing robust federated learning methods and systems