 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Generative AI to Innovative AI: An Evolutionary Roadmap
Mar 14, 2025This paper explores the critical transition from Generative Artificial Intelligence (GenAI) to Innovative Artificial Intelligence (InAI). While recent advancements in GenAI have enabled systems to produce high-quality content across various domains, these models often lack the capacity for true innovation. In this context, innovation is defined as the ability to generate novel and useful outputs that go beyond mere replication of learned data. The paper examines this shift and proposes a roadmap for developing AI systems that can generate content and engage in autonomous problem-solving and creative ideation. The work provides both theoretical insights and practical strategies for advancing AI to a stage where it can genuinely innovate, contributing meaningfully to science, technology, and the arts.
Communication-Efficient Training Workload Balancing for Decentralized Multi-Agent Learning
May 01, 2024Decentralized Multi-agent Learning (DML) enables collaborative model training while preserving data privacy. However, inherent heterogeneity in agents' resources (computation, communication, and task size) may lead to substantial variations in training time. This heterogeneity creates a bottleneck, lengthening the overall training time due to straggler effects and potentially wasting spare resources of faster agents. To minimize training time in heterogeneous environments, we present a Communication-Efficient Training Workload Balancing for Decentralized Multi-Agent Learning (ComDML), which balances the workload among agents through a decentralized approach. Leveraging local-loss split training, ComDML enables parallel updates, where slower agents offload part of their workload to faster agents. To minimize the overall training time, ComDML optimizes the workload balancing by jointly considering the communication and computation capacities of agents, which hinges upon integer programming. A dynamic decentralized pairing scheduler is developed to efficiently pair agents and determine optimal offloading amounts. We prove that in ComDML, both slower and faster agents' models converge, for convex and non-convex functions. Furthermore, extensive experimental results on popular datasets (CIFAR-10, CIFAR-100, and CINIC-10) and their non-I.I.D. variants, with large models such as ResNet-56 and ResNet-110, demonstrate that ComDML can significantly reduce the overall training time while maintaining model accuracy, compared to state-of-the-art methods. ComDML demonstrates robustness in heterogeneous environments, and privacy measures can be seamlessly integrated for enhanced data protection.
Speed Up Federated Learning in Heterogeneous Environment: A Dynamic Tiering Approach
Dec 09, 2023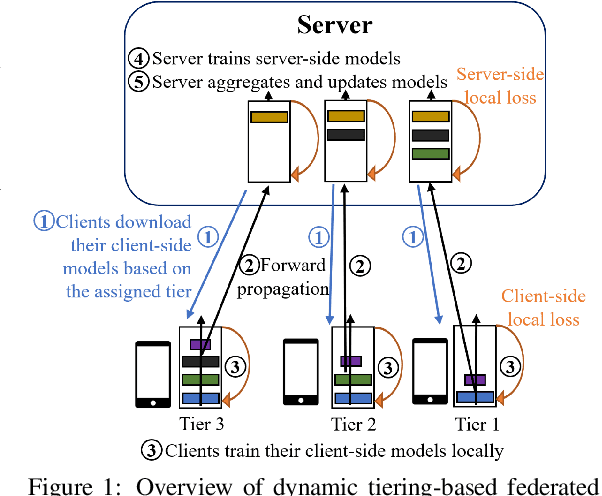
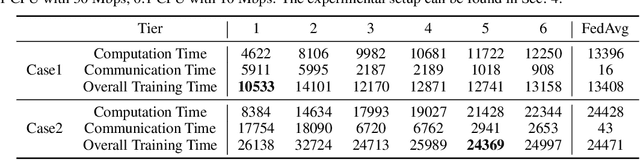

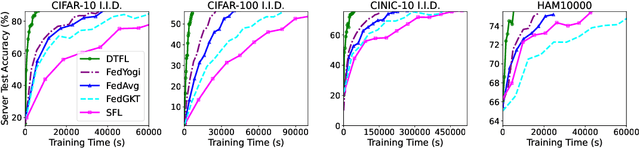
Federated learning (FL) enables collaboratively training a model while keeping the training data decentralized and private. However, one significant impediment to training a model using FL, especially large models, is the resource constraints of devices with heterogeneous computation and communication capacities as well as varying task sizes. Such heterogeneity would render significant variations in the training time of clients, resulting in a longer overall training time as well as a waste of resources in faster clients. To tackle these heterogeneity issues, we propose the Dynamic Tiering-based Federated Learning (DTFL) system where slower clients dynamically offload part of the model to the server to alleviate resource constraints and speed up training. By leveraging the concept of Split Learning, DTFL offloads different portions of the global model to clients in different tiers and enables each client to update the models in parallel via local-loss-based training. This helps reduce the computation and communication demand on resource-constrained devices and thus mitigates the straggler problem. DTFL introduces a dynamic tier scheduler that uses tier profiling to estimate the expected training time of each client, based on their historical training time, communication speed, and dataset size. The dynamic tier scheduler assigns clients to suitable tiers to minimize the overall training time in each round. We first theoretically prove the convergence properties of DTFL. We then train large models (ResNet-56 and ResNet-110) on popular image datasets (CIFAR-10, CIFAR-100, CINIC-10, and HAM10000) under both IID and non-IID systems. Extensive experimental results show that compared with state-of-the-art FL methods, DTFL can significantly reduce the training time while maintaining model accuracy.