 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Consistency Analysis of LLMs
Paper and Code
Feb 10, 2025

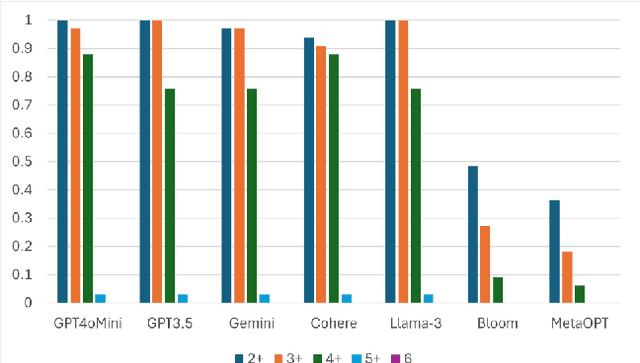

Generative AI (Gen AI) with large language models (LLMs) are being widely adopted across the industry, academia and government. Cybersecurity is one of the key sectors where LLMs can be and/or are already being used. There are a number of problems that inhibit the adoption of trustworthy Gen AI and LLMs in cybersecurity and such other critical areas. One of the key challenge to the trustworthiness and reliability of LLMs is: how consistent an LLM is in its responses? In this paper, we have analyzed and developed a formal definition of consistency of responses of LLMs. We have formally defined what is consistency of responses and then develop a framework for consistency evaluation. The paper proposes two approaches to validate consistency: self-validation, and validation across multiple LLMs. We have carried out extensive experiments for several LLMs such as GPT4oMini, GPT3.5, Gemini, Cohere, and Llama3, on a security benchmark consisting of several cybersecurity questions: informational and situational. Our experiments corroborate the fact that even though these LLMs are being considered and/or already being used for several cybersecurity tasks today, they are often inconsistent in their responses, and thus are untrustworthy and unreliable for cybersecurity.