 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLASH: Learnable Activation Functions for Improving Accuracy and Adversarial Robustness
Paper and Code
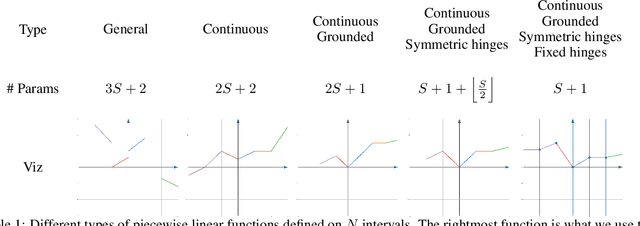
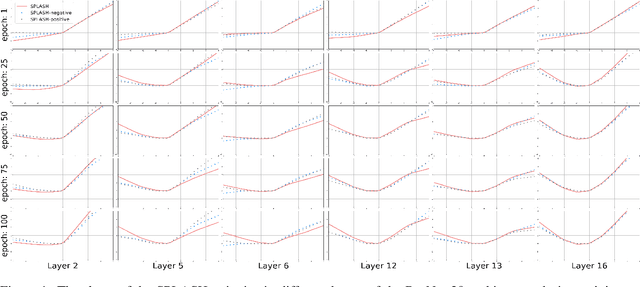
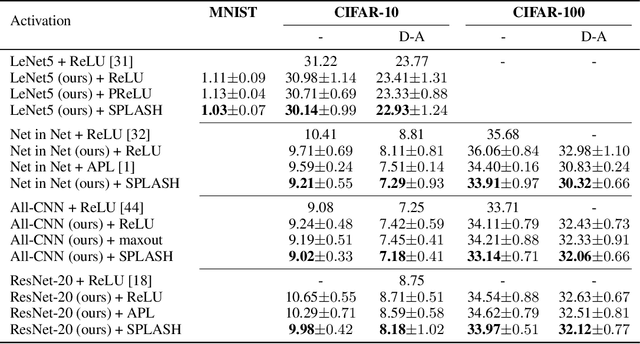
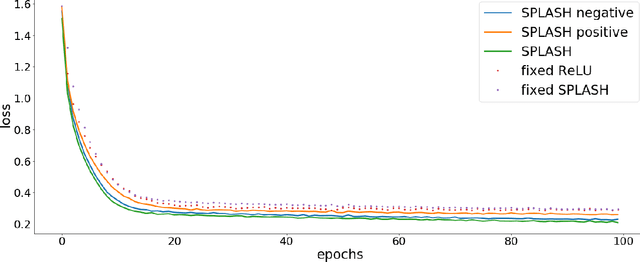
We introduce SPLASH units, a class of learnable activation functions shown to simultaneously improve the accuracy of deep neural networks while also improving their robustness to adversarial attacks. SPLASH units have both a simple parameterization and maintain the ability to approximate a wide range of non-linear functions. SPLASH units are: 1) continuous; 2) grounded (f(0) = 0); 3) use symmetric hinges; and 4) the locations of the hinges are derived directly from the data (i.e. no learning required). Compared to nine other learned and fixed activation functions, including ReLU and its variants, SPLASH units show superior performance across three datasets (MNIST, CIFAR-10, and CIFAR-100) and four architectures (LeNet5, All-CNN, ResNet-20, and Network-in-Network). Furthermore, we show that SPLASH units significantly increase the robustness of deep neural networks to adversarial attacks. Our experiments on both black-box and open-box adversarial attacks show that commonly-used architectures, namely LeNet5, All-CNN, ResNet-20, and Network-in-Network, can be up to 31% more robust to adversarial attacks by simply using SPLASH units instead of ReLUs.