 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Invariant Prompt Learning for Vision-Language Models
Mar 30, 2026Large pre-trained vision-language models like CLIP have transformed computer vision by aligning images and text in a shared feature space, enabling robust zero-shot transfer via prompting. Soft-prompting, such as Context Optimization (CoOp), effectively adapts these models for downstream recognition tasks by learning a set of context vectors. However, CoOp lacks explicit mechanisms for handling domain shifts across unseen distributions. To address this, we propose Domain-invariant Context Optimization (DiCoOp), an extension of CoOp optimized for domain generalization. By employing an adversarial training approach, DiCoOp forces the model to learn domain-invariant prompts while preserving discriminative power for classification. Experimental results show that DiCoOp consistently surpasses CoOp in domain generalization tasks across diverse visual domains.
GateLens: A Reasoning-Enhanced LLM Agent for Automotive Software Release Analytics
Mar 27, 2025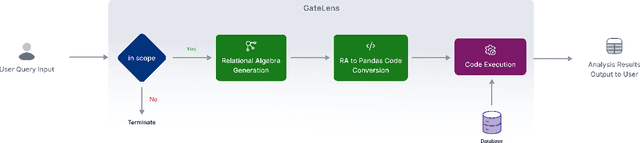


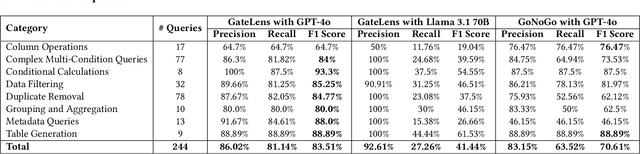
Ensuring the reliability and effectiveness of software release decisions is critical, particularly in safety-critical domains like automotive systems. Precise analysis of release validation data, often presented in tabular form, plays a pivotal role in this process. However, traditional methods that rely on manual analysis of extensive test datasets and validation metrics are prone to delays and high costs. Large Language Models (LLMs) offer a promising alternative but face challenges in analytical reasoning, contextual understanding, handling out-of-scope queries, and processing structured test data consistently; limitations that hinder their direct application in safety-critical scenarios. This paper introduces GateLens, an LLM-based tool for analyzing tabular data in the automotive domain. GateLens translates natural language queries into Relational Algebra (RA) expressions and then generates optimized Python code. It outperforms the baseline system on benchmarking datasets, achieving higher F1 scores and handling complex and ambiguous queries with greater robustness. Ablation studies confirm the critical role of the RA module, with performance dropping sharply when omitted. Industrial evaluations reveal that GateLens reduces analysis time by over 80% while maintaining high accuracy and reliability. As demonstrated by presented results, GateLens achieved high performance without relying on few-shot examples, showcasing strong generalization across various query types from diverse company roles. Insights from deploying GateLens with a partner automotive company offer practical guidance for integrating AI into critical workflows such as release validation. Results show that by automating test result analysis, GateLens enables faster, more informed, and dependable release decisions, and can thus advance software scalability and reliability in automotive systems.
GoNoGo: An Efficient LLM-based Multi-Agent System for Streamlining Automotive Software Release Decision-Making
Aug 19, 2024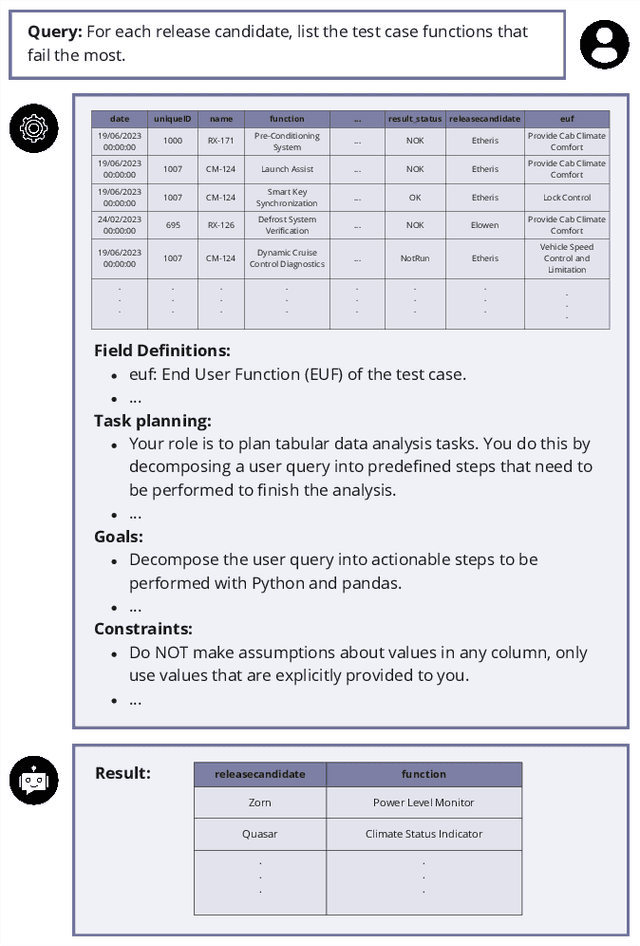
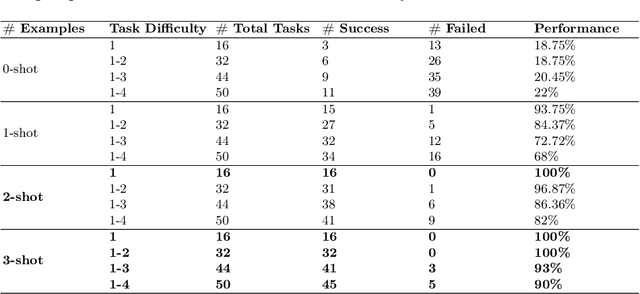

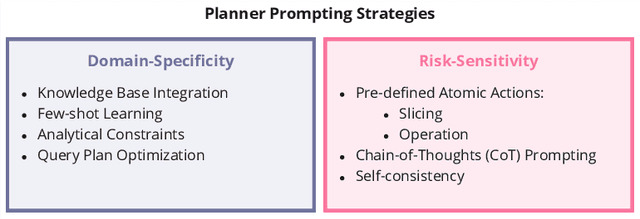
Traditional methods for making software deployment decisions in the automotive industry typically rely on manual analysis of tabular software test data. These methods often lead to higher costs and delays in the software release cycle due to their labor-intensive nature. Large Language Models (LLMs) present a promising solution to these challenges. However, their application generally demands multiple rounds of human-driven prompt engineering, which limits their practical deployment, particularly for industrial end-users who need reliable and efficient results. In this paper, we propose GoNoGo, an LLM agent system designed to streamline automotive software deployment while meeting both functional requirements and practical industrial constraints. Unlike previous systems, GoNoGo is specifically tailored to address domain-specific and risk-sensitive systems. We evaluate GoNoGo's performance across different task difficulties using zero-shot and few-shot examples taken from industrial practice. Our results show that GoNoGo achieves a 100% success rate for tasks up to Level 2 difficulty with 3-shot examples, and maintains high performance even for more complex tasks. We find that GoNoGo effectively automates decision-making for simpler tasks, significantly reducing the need for manual intervention. In summary, GoNoGo represents an efficient and user-friendly LLM-based solution currently employed in our industrial partner's company to assist with software release decision-making, supporting more informed and timely decisions in the release process for risk-sensitive vehicle systems.
Domain Generalization through Meta-Learning: A Survey
Apr 03, 2024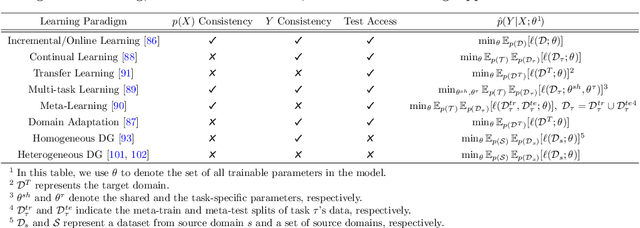

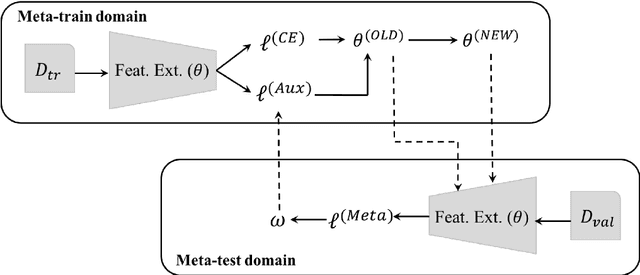
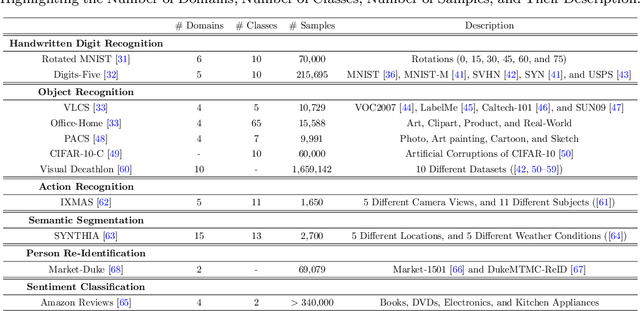
Deep neural networks (DNNs) have revolutionized artificial intelligence but often lack performance when faced with out-of-distribution (OOD) data, a common scenario due to the inevitable domain shifts in real-world applications. This limitation stems from the common assumption that training and testing data share the same distribution-an assumption frequently violated in practice. Despite their effectiveness with large amounts of data and computational power, DNNs struggle with distributional shifts and limited labeled data, leading to overfitting and poor generalization across various tasks and domains. Meta-learning presents a promising approach by employing algorithms that acquire transferable knowledge across various tasks for fast adaptation, eliminating the need to learn each task from scratch. This survey paper delves into the realm of meta-learning with a focus on its contribution to domain generalization. We first clarify the concept of meta-learning for domain generalization and introduce a novel taxonomy based on the feature extraction strategy and the classifier learning methodology, offering a granular view of methodologies. Through an exhaustive review of existing methods and underlying theories, we map out the fundamentals of the field. Our survey provides practical insights and an informed discussion on promising research directions, paving the way for future innovation in meta-learning for domain generalization.
Meta-Learning in Spiking Neural Networks with Reward-Modulated STDP
Jun 07, 2023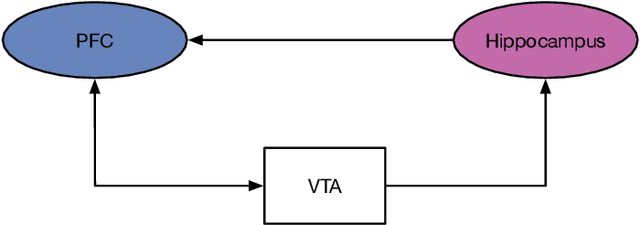
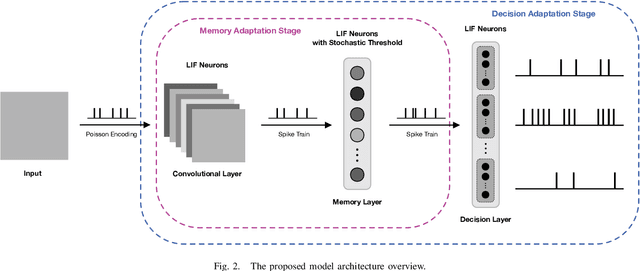


The human brain constantly learns and rapidly adapts to new situations by integrating acquired knowledge and experiences into memory. Developing this capability in machine learning models is considered an important goal of AI research since deep neural networks perform poorly when there is limited data or when they need to adapt quickly to new unseen tasks. Meta-learning models are proposed to facilitate quick learning in low-data regimes by employing absorbed information from the past. Although some models have recently been introduced that reached high-performance levels, they are not biologically plausible. We have proposed a bio-plausible meta-learning model inspired by the hippocampus and the prefrontal cortex using spiking neural networks with a reward-based learning system. Our proposed model includes a memory designed to prevent catastrophic forgetting, a phenomenon that occurs when meta-learning models forget what they have learned as soon as the new task begins. Also, our new model can easily be applied to spike-based neuromorphic devices and enables fast learning in neuromorphic hardware. The final analysis will discuss the implications and predictions of the model for solving few-shot classification tasks. In solving these tasks, our model has demonstrated the ability to compete with the existing state-of-the-art meta-learning techniques.
A least squares support vector regression for anisotropic diffusion filtering
Jan 30, 2022
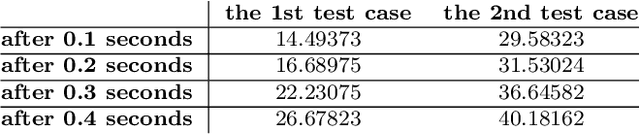


Anisotropic diffusion filtering for signal smoothing as a low-pass filter has the advantage of the edge-preserving, i.e., it does not affect the edges that contain more critical data than the other parts of the signal. In this paper, we present a numerical algorithm based on least squares support vector regression by using Legendre orthogonal kernel with the discretization of the nonlinear diffusion problem in time by the Crank-Nicolson method. This method transforms the signal smoothing process into solving an optimization problem that can be solved by efficient numerical algorithms. In the final analysis, we have reported some numerical experiments to show the effectiveness of the proposed machine learning based approach for signal smoothing.