 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Aware Representation of Multi-Modal Data for Data Ingress: A Literature Review
Paper and Code
Jul 17, 2024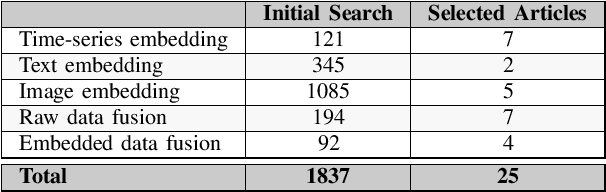
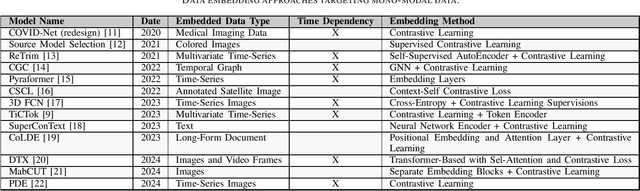
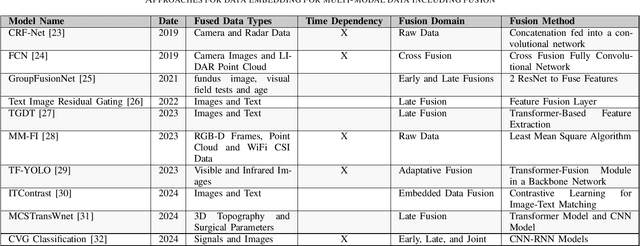
Machine Learning (ML) is continuously permeating a growing amount of application domains. Generative AI such as Large Language Models (LLMs) also sees broad adoption to process multi-modal data such as text, images, audio, and video. While the trend is to use ever-larger datasets for training, managing this data efficiently has become a significant practical challenge in the industry-double as much data is certainly not double as good. Rather the opposite is important since getting an understanding of the inherent quality and diversity of the underlying data lakes is a growing challenge for application-specific ML as well as for fine-tuning foundation models. Furthermore, information retrieval (IR) from expanding data lakes is complicated by the temporal dimension inherent in time-series data which must be considered to determine its semantic value. This study focuses on the different semantic-aware techniques to extract embeddings from mono-modal, multi-modal, and cross-modal data to enhance IR capabilities in a growing data lake. Articles were collected to summarize information about the state-of-the-art techniques focusing on applications of embedding for three different categories of data modalities.