 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCARNN-DCBF: Minimal-Intervention Geofence Enforcement for Ground Vehicles
Nov 19, 2025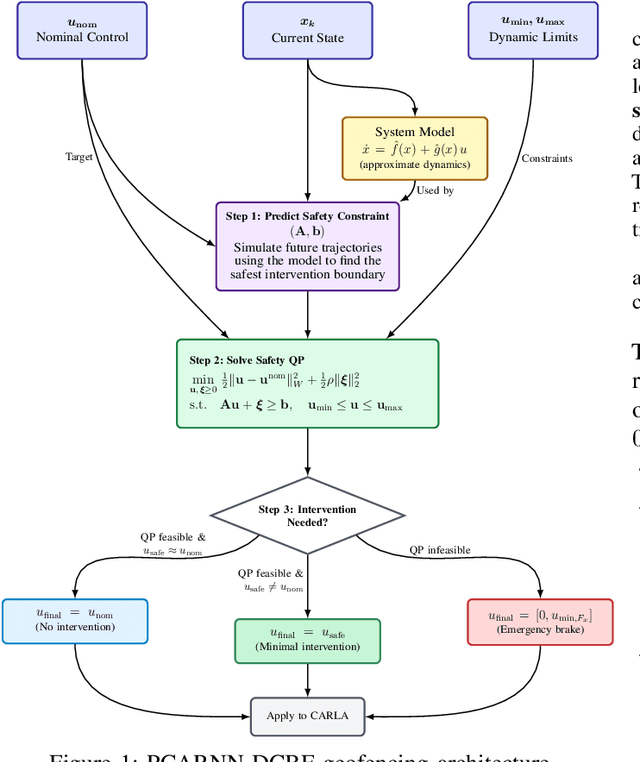



Runtime geofencing for ground vehicles is rapidly emerging as a critical technology for enforcing Operational Design Domains (ODDs). However, existing solutions struggle to reconcile high-fidelity learning with the structural requirements of verifiable control. We address this by introducing PCARNN-DCBF, a novel pipeline integrating a Physics-encoded Control-Affine Residual Neural Network with a preview-based Discrete Control Barrier Function. Unlike generic learned models, PCARNN explicitly preserves the control-affine structure of vehicle dynamics, ensuring the linearity required for reliable optimization. This enables the DCBF to enforce polygonal keep-in constraints via a real-time Quadratic Program (QP) that handles high relative degree and mitigates actuator saturation. Experiments in CARLA across electric and combustion platforms demonstrate that this structure-preserving approach significantly outperforms analytical and unstructured neural baselines.
Separable Convolutional Eigen-Filters (SCEF): Building Efficient CNNs Using Redundancy Analysis
Nov 16, 2019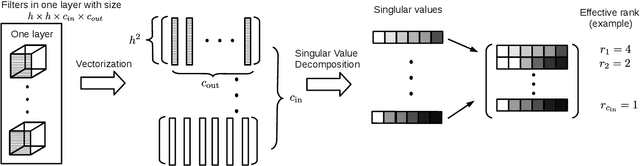
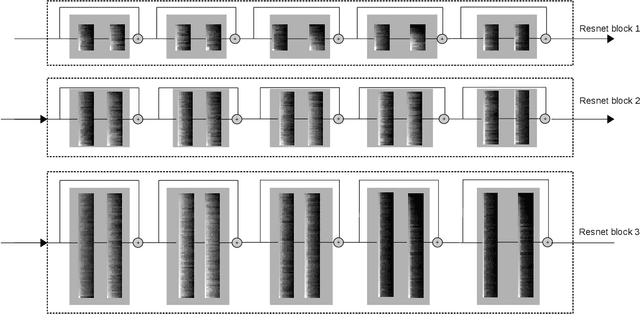
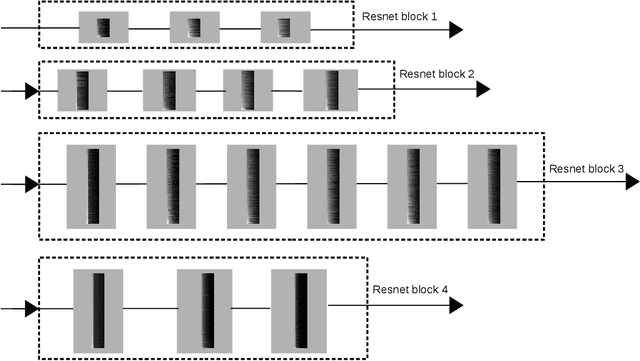
Deep Convolutional Neural Networks (CNNs) have been widely used in computer vision due to its effectiveness. While the high model complexity of CNN enables remarkable learning capacity, the large number of trainable parameters comes with a high cost. In addition to the demand of a large amount of resources, the high complexity of the network can result in a high variance in its generalization performance from a statistical learning theory perspective. One way to reduce the complexity of a network without sacrificing its accuracy is to define and identify redundancies in order to remove them. In this work, we propose a method to observe and analyze redundancies in the weights of 2D convolutional (Conv2D) filters. From our experiments, we observe that 1) the vectorized Conv2D filters exhibit low rank behaviors; 2) the effective ranks of these filters typically decrease when the network goes deeper, and 3) these effective ranks are converging over training steps. Inspired by these observations, we propose a new layer called Separable Convolutional Eigen-Filters (SCEF) as an alternative parameterization to Conv2D filters. A SCEF layer can be easily implemented using the depthwise separable convolutions trained with our proposed training strategy. In addition to the decreased number of trainable parameters by using SCEF, depthwise separable convolutions are known to be more computationally efficient compared to Conv2D operations, which reduces the runtime FLOPs as well. Experiments are conducted on the CIFAR-10 and ImageNet datasets by replacing the Conv2D layers with SCEF. The results have shown an increased accuracy using about 2/3 of the original parameters and reduce the number of FLOPs to 2/3 of the base net.
Mono-Camera 3D Multi-Object Tracking Using Deep Learning Detections and PMBM Filtering
Feb 27, 2018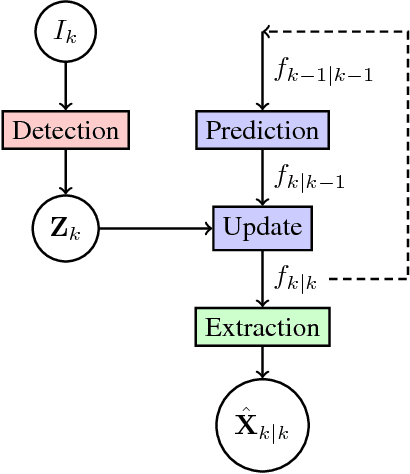
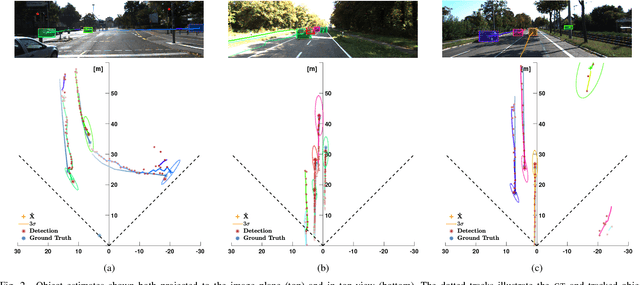


Monocular cameras are one of the most commonly used sensors in the automotive industry for autonomous vehicles. One major drawback using a monocular camera is that it only makes observations in the two dimensional image plane and can not directly measure the distance to objects. In this paper, we aim at filling this gap by developing a multi-object tracking algorithm that takes an image as input and produces trajectories of detected objects in a world coordinate system. We solve this by using a deep neural network trained to detect and estimate the distance to objects from a single input image. The detections from a sequence of images are fed in to a state-of-the art Poisson multi-Bernoulli mixture tracking filter. The combination of the learned detector and the PMBM filter results in an algorithm that achieves 3D tracking using only mono-camera images as input. The performance of the algorithm is evaluated both in 3D world coordinates, and 2D image coordinates, using the publicly available KITTI object tracking dataset. The algorithm shows the ability to accurately track objects, correctly handle data associations, even when there is a big overlap of the objects in the image, and is one of the top performing algorithms on the KITTI object tracking benchmark. Furthermore, the algorithm is efficient, running on average close to 20 frames per second.
Fast LIDAR-based Road Detection Using Fully Convolutional Neural Networks
Mar 29, 2017
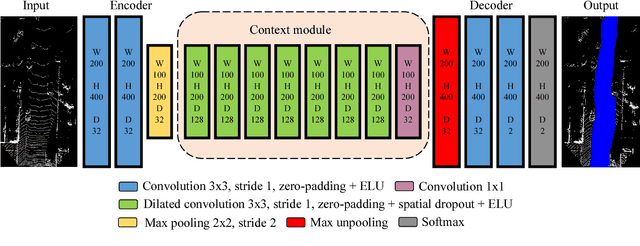
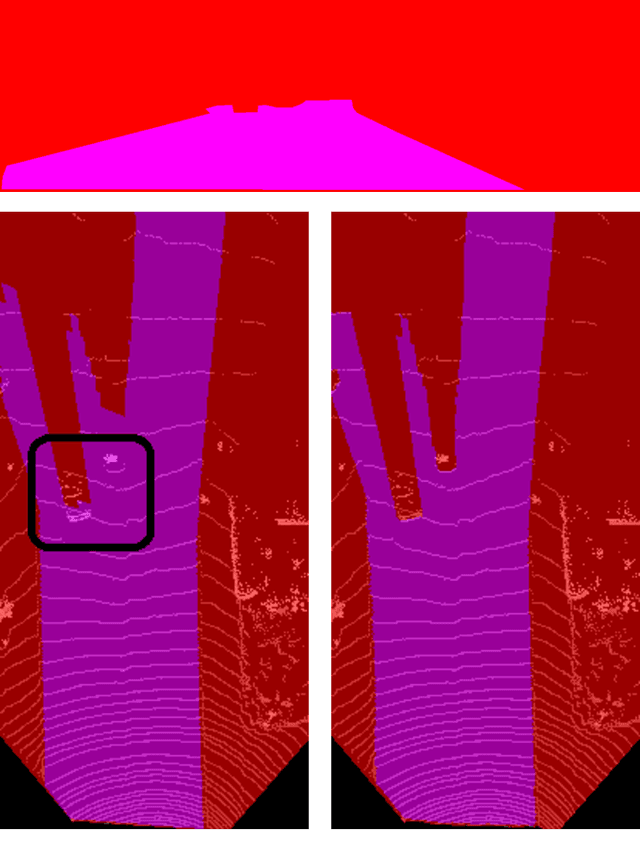

In this work, a deep learning approach has been developed to carry out road detection using only LIDAR data. Starting from an unstructured point cloud, top-view images encoding several basic statistics such as mean elevation and density are generated. By considering a top-view representation, road detection is reduced to a single-scale problem that can be addressed with a simple and fast fully convolutional neural network (FCN). The FCN is specifically designed for the task of pixel-wise semantic segmentation by combining a large receptive field with high-resolution feature maps. The proposed system achieved excellent performance and it is among the top-performing algorithms on the KITTI road benchmark. Its fast inference makes it particularly suitable for real-time applications.