 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectVisA-120: Object-based Visual Attention Prediction in Interactive Street-crossing Environments
Jan 19, 2026The object-based nature of human visual attention is well-known in cognitive science, but has only played a minor role in computational visual attention models so far. This is mainly due to a lack of suitable datasets and evaluation metrics for object-based attention. To address these limitations, we present \dataset~ -- a novel 120-participant dataset of spatial street-crossing navigation in virtual reality specifically geared to object-based attention evaluations. The uniqueness of the presented dataset lies in the ethical and safety affiliated challenges that make collecting comparable data in real-world environments highly difficult. \dataset~ not only features accurate gaze data and a complete state-space representation of objects in the virtual environment, but it also offers variable scenario complexities and rich annotations, including panoptic segmentation, depth information, and vehicle keypoints. We further propose object-based similarity (oSIM) as a novel metric to evaluate the performance of object-based visual attention models, a previously unexplored performance characteristic. Our evaluations show that explicitly optimising for object-based attention not only improves oSIM performance but also leads to an improved model performance on common metrics. In addition, we present SUMGraph, a Mamba U-Net-based model, which explicitly encodes critical scene objects (vehicles) in a graph representation, leading to further performance improvements over several state-of-the-art visual attention prediction methods. The dataset, code and models will be publicly released.
Predicting Pedestrian Crossing Behavior in Germany and Japan: Insights into Model Transferability
Dec 04, 2024



Predicting pedestrian crossing behavior is important for intelligent traffic systems to avoid pedestrian-vehicle collisions. Most existing pedestrian crossing behavior models are trained and evaluated on datasets collected from a single country, overlooking differences between countries. To address this gap, we compared pedestrian road-crossing behavior at unsignalized crossings in Germany and Japan. We presented four types of machine learning models to predict gap selection behavior, zebra crossing usage, and their trajectories using simulator data collected from both countries. When comparing the differences between countries, pedestrians from the study conducted in Japan are more cautious, selecting larger gaps compared to those in Germany. We evaluate and analyze model transferability. Our results show that neural networks outperform other machine learning models in predicting gap selection and zebra crossing usage, while random forest models perform best on trajectory prediction tasks, demonstrating strong performance and transferability. We develop a transferable model using an unsupervised clustering method, which improves prediction accuracy for gap selection and trajectory prediction. These findings provide a deeper understanding of pedestrian crossing behaviors in different countries and offer valuable insights into model transferability.
Predicting and Analyzing Pedestrian Crossing Behavior at Unsignalized Crossings
Apr 15, 2024Understanding and predicting pedestrian crossing behavior is essential for enhancing automated driving and improving driving safety. Predicting gap selection behavior and the use of zebra crossing enables driving systems to proactively respond and prevent potential conflicts. This task is particularly challenging at unsignalized crossings due to the ambiguous right of way, requiring pedestrians to constantly interact with vehicles and other pedestrians. This study addresses these challenges by utilizing simulator data to investigate scenarios involving multiple vehicles and pedestrians. We propose and evaluate machine learning models to predict gap selection in non-zebra scenarios and zebra crossing usage in zebra scenarios. We investigate and discuss how pedestrians' behaviors are influenced by various factors, including pedestrian waiting time, walking speed, the number of unused gaps, the largest missed gap, and the influence of other pedestrians. This research contributes to the evolution of intelligent vehicles by providing predictive models and valuable insights into pedestrian crossing behavior.
Fine-Grained Semantic Segmentation of Motion Capture Data using Dilated Temporal Fully-Convolutional Networks
Mar 02, 2019

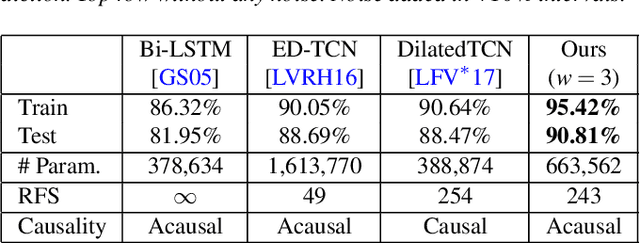
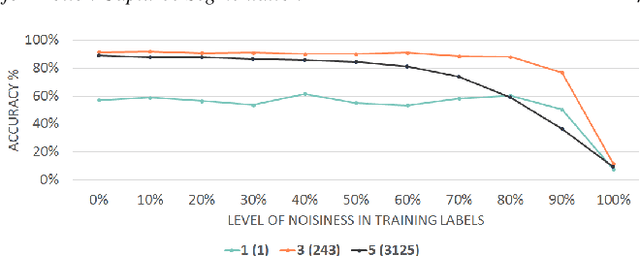
Human motion capture data has been widely used in data-driven character animation. In order to generate realistic, natural-looking motions, most data-driven approaches require considerable efforts of pre-processing, including motion segmentation and annotation. Existing (semi-) automatic solutions either require hand-crafted features for motion segmentation or do not produce the semantic annotations required for motion synthesis and building large-scale motion databases. In addition, human labeled annotation data suffers from inter- and intra-labeler inconsistencies by design. We propose a semi-automatic framework for semantic segmentation of motion capture data based on supervised machine learning techniques. It first transforms a motion capture sequence into a ``motion image'' and applies a convolutional neural network for image segmentation. Dilated temporal convolutions enable the extraction of temporal information from a large receptive field. Our model outperforms two state-of-the-art models for action segmentation, as well as a popular network for sequence modeling. Most of all, our method is very robust under noisy and inaccurate training labels and thus can handle human errors during the labeling process.
Dilated Temporal Fully-Convolutional Network for Semantic Segmentation of Motion Capture Data
Jun 24, 2018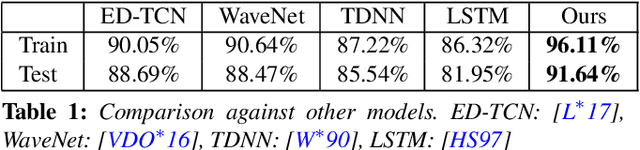
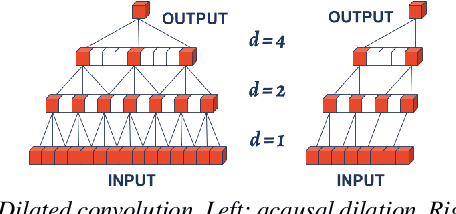
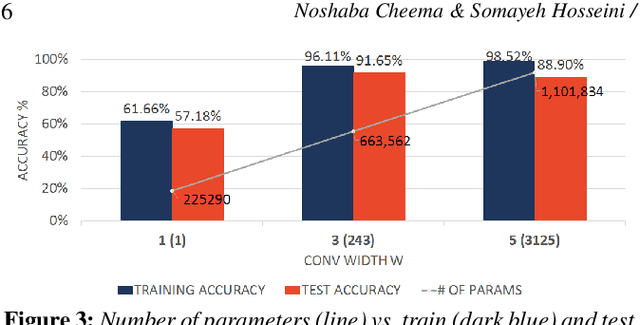
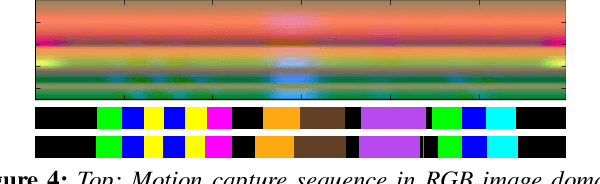
Semantic segmentation of motion capture sequences plays a key part in many data-driven motion synthesis frameworks. It is a preprocessing step in which long recordings of motion capture sequences are partitioned into smaller segments. Afterwards, additional methods like statistical modeling can be applied to each group of structurally-similar segments to learn an abstract motion manifold. The segmentation task however often remains a manual task, which increases the effort and cost of generating large-scale motion databases. We therefore propose an automatic framework for semantic segmentation of motion capture data using a dilated temporal fully-convolutional network. Our model outperforms a state-of-the-art model in action segmentation, as well as three networks for sequence modeling. We further show our model is robust against high noisy training labels.