 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Semantic Segmentation of Motion Capture Data using Dilated Temporal Fully-Convolutional Networks
Paper and Code
Mar 02, 2019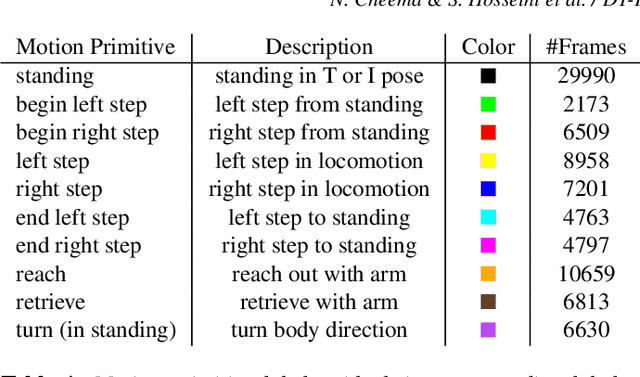

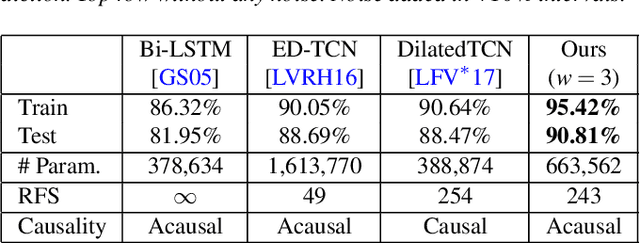
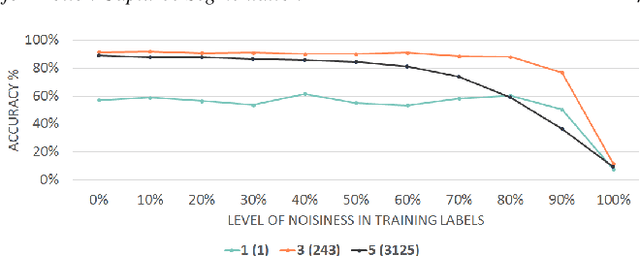
Human motion capture data has been widely used in data-driven character animation. In order to generate realistic, natural-looking motions, most data-driven approaches require considerable efforts of pre-processing, including motion segmentation and annotation. Existing (semi-) automatic solutions either require hand-crafted features for motion segmentation or do not produce the semantic annotations required for motion synthesis and building large-scale motion databases. In addition, human labeled annotation data suffers from inter- and intra-labeler inconsistencies by design. We propose a semi-automatic framework for semantic segmentation of motion capture data based on supervised machine learning techniques. It first transforms a motion capture sequence into a ``motion image'' and applies a convolutional neural network for image segmentation. Dilated temporal convolutions enable the extraction of temporal information from a large receptive field. Our model outperforms two state-of-the-art models for action segmentation, as well as a popular network for sequence modeling. Most of all, our method is very robust under noisy and inaccurate training labels and thus can handle human errors during the labeling process.